- The paper demonstrates that transformers rapidly learn global bigram statistics and gradually develop induction heads for effective in-context learning.
- It employs a novel synthetic dataset setup and attention matrix analysis to isolate and study associative memory mechanisms in transformer training.
- The empirical findings underscore the significance of training dynamics, data diversity, and matrix learning order in refining transformer performance.
This paper, "Birth of a Transformer: A Memory Viewpoint" (2306.00802), investigates the internal mechanisms of large transformer-based LLMs through a synthetic data setup to elucidate how these models learn and balance both global and in-context knowledge. The authors adopt an associative memory perspective to explore the dynamics of transformer weight matrices during training, providing insights into the emergence of in-context learning capabilities.
Introduction
The study aims to demystify transformer models' black-box nature, particularly their influential ability to perform in-context learning, a factor contributing significantly to their success in LLM applications. By deploying a simplified two-layer transformer trained on sequences generated from either global or context-specific bigram distributions, the authors demonstrate a fast learning process of global bigrams vis-à-vis the more gradual development of the induction head mechanism, integral to capturing in-context bigrams.
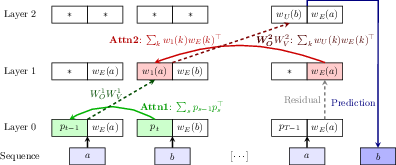
Figure 1: Induction head mechanism. Induction heads are a two-layer mechanism that can predict b from a context […,a,b,…,a]. The first layer is a previous token head, which attends to the previous token based on positional embeddings ($\color{black!40!green} p_t \to p_{t-1}$) and copies it after a remapping (wE(a)→w1(a):=WO1WV1wE(a)). The second layer is the induction head, which attends based on the output of the previous token head ($\color{black!30!red} w_E(a) \to w_1(a)$) and outputs the attended token, remapped to output embeddings ($\color{black!70!red} w_E(b) \to w_U(b)$).
The study introduces a novel synthetic setup to discern between "global" and "in-context" learning capabilities of transformers. This setup uses sequences generated from a bigram LLM, introducing a variation where some bigrams are sequence-specific, compelling the model to efficiently engage its in-context learning capabilities.
Synthetic Data Model and Training Dynamics
The analysis begins with the development of a synthetic setup, comprised of tokens generated from either global or context-specific bigram distributions, necessitating transformers to utilize their remarkable ability to adapt quickly when encountering specific sequence conditions.



Figure 2: Induction head behavior in attention maps observed on a 2-layer transformer trained on two variants of a synthetic dataset. The attention pattern for predicting each token depends strongly on previous occurrences of that token in the sequence.
Emergence of Induction Heads
The research explores the development of the induction head mechanism (Figure 1, Figure 2), which is critical for efficient in-context learning. The induction head is detailed as a layered construction of attention heads whereby the transformer predicts a token by attending to both the previous occurrence and context, employing weight matrices as associative memories (Figure 1).
The empirical analysis (Figure 2) demonstrates how the global memorization of bigram statistics occurs rapidly, relative to the more deliberate formation of an induction head mechanism. This phenomenon highlights the learnable nature of specific associative memories in the transformer's structure facilitated by gradients during training. The study of memorization dynamics (Figure 3) indicates that during an epoch of training, the output matrix WO2 learns appropriate associations faster than its corresponding key-value matrices.
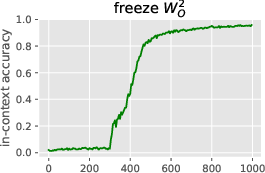
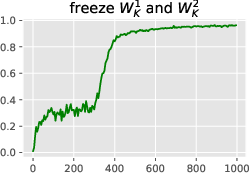
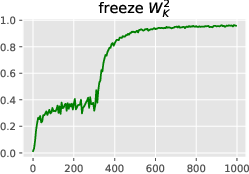
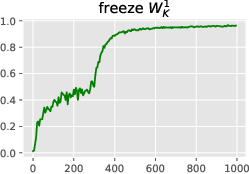
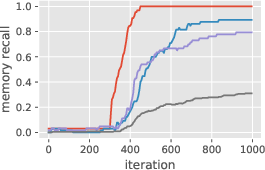
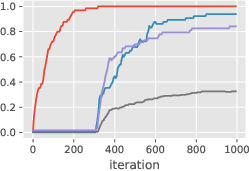
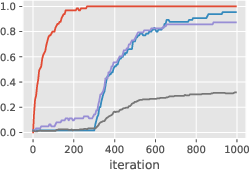
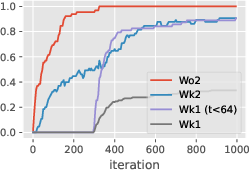
Figure 3: Learning the induction head alone: in-context accuracy (top) and recall probes (bottom) with some layers frozen until iteration 300. The output matrix~WO2 can and must be learned before the key-query matrices, but does not suffice for good accuracy. It is easier to learn~WK2before W_K1,and W_K1 stores initial context positions (t < 64) much faster than late positions.
Global vs. In-Context Learning
The presented research highlights the balance that transformers maintain between global and in-context learning by leveraging weight matrices as associative memories. The synthetic dataset, which challenges the transformer model to learn mixed bigram distributions—some global, others sequence-specific—demonstrates that two-layer transformers are able to capture the in-context learning capabilities through the induction head mechanic, even when many layers are frozen during training.
Figure 3: Learning the induction head alone: in-context accuracy (top) and recall probes (bottom) with some layers frozen until iteration 300. This shows the simplified learning dynamics and layer dependencies in forming the induction head.
Implementation Insights
To implement and explore the induction head mechanism within a simplified two-layer transformer, the paper discusses freezing certain weight matrices, including attention key, value matrices, and embeddings, and only training the remaining parameters. This methodology allows for an isolated study of training dynamics.
The implementation of associative memories using weight matrices (Equation \eqref{eq:simple_memory}) leverages properties of nearly-orthonormal embeddings, stored as outer products. The model adheres to low-rank matrix factorization concepts to manage parameters, useful for both instance embeddings and associative lookups.
Memory Recall Probes
For practical evaluation, memory recall probes are employed. These assess whether individual weight matrices have captured the desired associative memory behavior by measuring recall rates of stored associations (Equation 3).
Figure 3: Learning the induction head alone: in-context accuracy (top) and recall probes (bottom) with some layers frozen until iteration 300. The output matrix~WO2 can and must be learned before the key-query matrices, but does not suffice for good accuracy. It is easier to learn~WK2before WK1,and WK1storesinitialcontextpositions(t<64)$ much faster than late positions.
Theoretical Insights and Conclusions
The paper develops an argument that learning of the induction head occurs through a top-down gradient process. It illustrates that an associative memory viewpoint helps understand how weight matrices within the transformer serve as storage for key-value associations. The results indicate a stark, qualitative learning progression concerning in-context capabilities, notably with the development of induction heads in the simplified setup.
The presence of induction heads at deeper transformer layers appears central to the mechanism by which LLMs achieve capabilities such as in-context learning, as evidenced by precision improvements over time (Figure 3). The model first learns to create output associations in the output matrices, then adjusts attention to focus on relevant context. Data distribution plays a significant role in the efficiency of in-context learning, with random triggers and diverse output distributions leading to slower convergence.
Figure 3: Learning the induction head alone: in-context accuracy (top) and recall probes (bottom) with some layers frozen until iteration 300. The output matrix~WO2 can and must be learned before the key-query matrices, but does not suffice for good accuracy. It is easier to learn~WK2before W_K1,andW_K1storesinitialcontextpositionst < 64$ much faster than late positions.
This observation aligns with the widely acknowledged notion that LLMs can acquire simple global knowledge rapidly compared to more sophisticated context-specific interactions. Further research is essential to explore these dynamics in larger architectures and diversify data regimes to better align with real-world language modeling tasks. The concurrent learning of multiple matrices in a multi-layer setup may lead to complex feedback dynamics, introducing inductive biases and regularization effects that warrant from-depth theoretical exploration [allen2020backward].
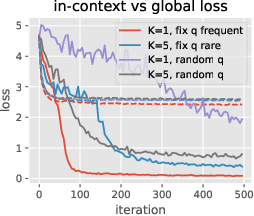
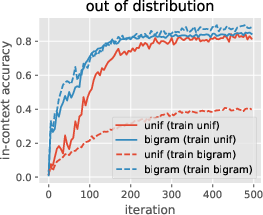
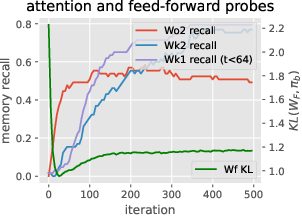
Figure 4: Global vs in-context learning and data-distributional effects. The learning speed and training effectiveness of global and in-context tokens can vary significantly based on the training setup and data distribution.
This study indicates that diversity in training datasets can enhance generalization, particularly for models relying on a robust induction head mechanism. The investigation into associative memories provides leverage to understand the intricate dynamics within transformers, relevant to construct more interpretable and effective LLMs. As the study suggests, future work should focus on further theoretical frameworks and explore seeing transformers through associative memory lenses in more complex architectures, including non-linear components and deeper models with multiple attention heads.
Conclusion
In conclusion, this paper elucidates how transformers develop in-context learning abilities through the lens of associative memories and the induction head mechanism. The research presents a synthetic dataset and a simplified model that facilitate understanding of the training dynamics required for learning these mechanisms. The empirical and theoretical insights proposed have implications for advancing LLM training methodologies, such as optimization, data distribution strategies, and the interpretability of model architectures. The introduction of synthetic setups is instrumental in shedding light on the underlying processes occurring in transformer LLMs. Future research is poised to expand upon these findings to encompass more complex architectural components and richer tasks, potentially leading to model improvement and enhanced interpretability in LLM applications.
Figure 4: Global vs in-context learning and data-distributional effects are highlighted, showing the variance in learning speed and performance depending on the setup.
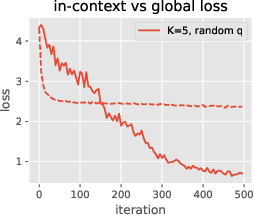
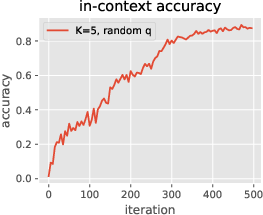
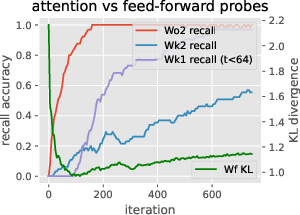
Figure 5: Training of a more realistic architecture with (i) ReLU MLPs replacing linear layers, (ii) training all parameters, and (iii) incorporating pre-layer normalization.

