- The paper presents a novel multi-agent deep RL framework with action supervision to better assess the contributions of soccer players.
- It leverages GRUs and a temporal difference loss combined with supervised learning for more accurate Q-value estimation in dynamic game settings.
- Comparative analysis shows the model delivers robust valuation of both on- and off-ball actions, enhancing scouting and tactical decisions.
Action Valuation for Soccer Players Using Deep Reinforcement Learning
Introduction
This paper introduces a novel method for valuing the actions of on- and off-ball soccer players using a holistic framework based on multi-agent deep reinforcement learning (RL). The approach leverages a discrete action space in a continuous state space, mimicking Google Research Football, and incorporates supervised learning to enhance RL effectiveness. The valuation method addresses the challenges posed by the dynamic nature of soccer, where players continuously make decisions in a spatiotemporally continuous environment. The proposed framework assesses both the overt and subtle contributions of players, providing valuable insights into teamwork effectiveness, player scouting, and fan engagement.
Methodology
The RL framework comprises three core components: state, action, and reward. The state includes the positions and velocities of players and the ball, while the actions encompass movement directions, passes, and shots. Rewards are assigned based on game outcomes, such as goals, expected scoring probabilities, and opponent attacks.
The architecture of the RL model incorporates gated recurrent units (GRUs) for processing sequential game state inputs and outputs Q-values for each player's actions.
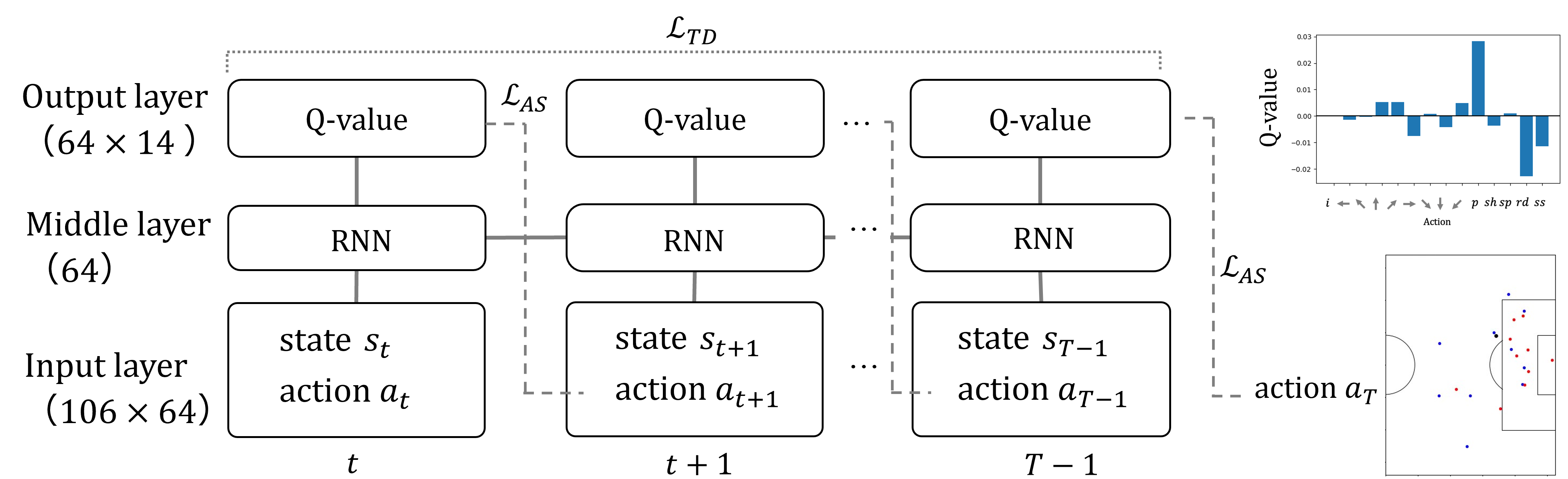
Figure 1: Our deep RL model with action supervision.
To enhance learning accuracy, the model employs a temporal difference (TD) loss function combined with action supervision. The action supervision restrains learning trajectories by emphasizing actions taken in the actual game, inducing an inductive bias to efficiently estimate Q-values for potential actions.
Experiments and Results
Experiments were conducted using data from 54 games in the 2019 Meiji J1 League. The effectiveness of the model was demonstrated through the analysis of attack sequences from Yokohama F. Marinos. Quantitative evaluation showed that models with action supervision exhibited superior performance, evidenced by lower TD loss and higher Q-values for realistic playing strategies.
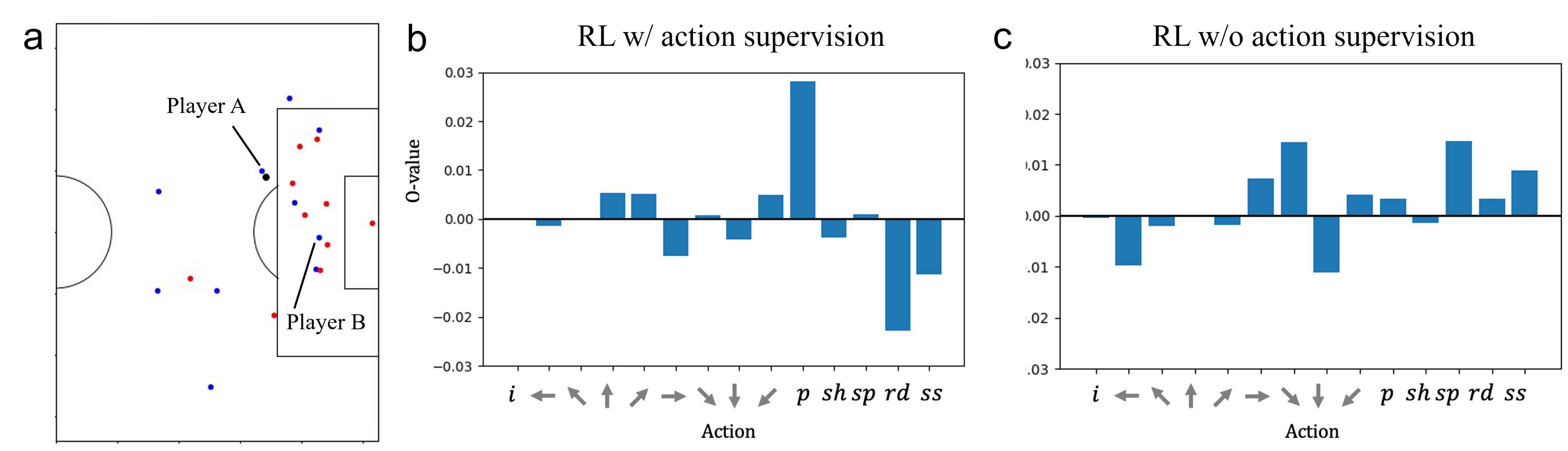
Figure 2: Example of estimated Q-values. (a) shows an example attack. Blue, red, and black indicate the attacker, defender, and the ball, respectively (note that the ball is over a defender). (b) and (c) show the Q-value of player A for each action using the RL model with and without action supervision, respectively. Note that i,p,sh,sp,rd,ss correspond to idle, pass, shot, sprint, decelerate, and sprint end, respectively, and arrows correspond to the direction of movement.
The proposed method displayed robustness in valuing defensive players' contributions, correlating significantly with players known for their effective passes. The analysis of player valuation against conventional indicators like goals, expert ratings, and existing scoring models highlighted the unique insights provided by the RL framework.
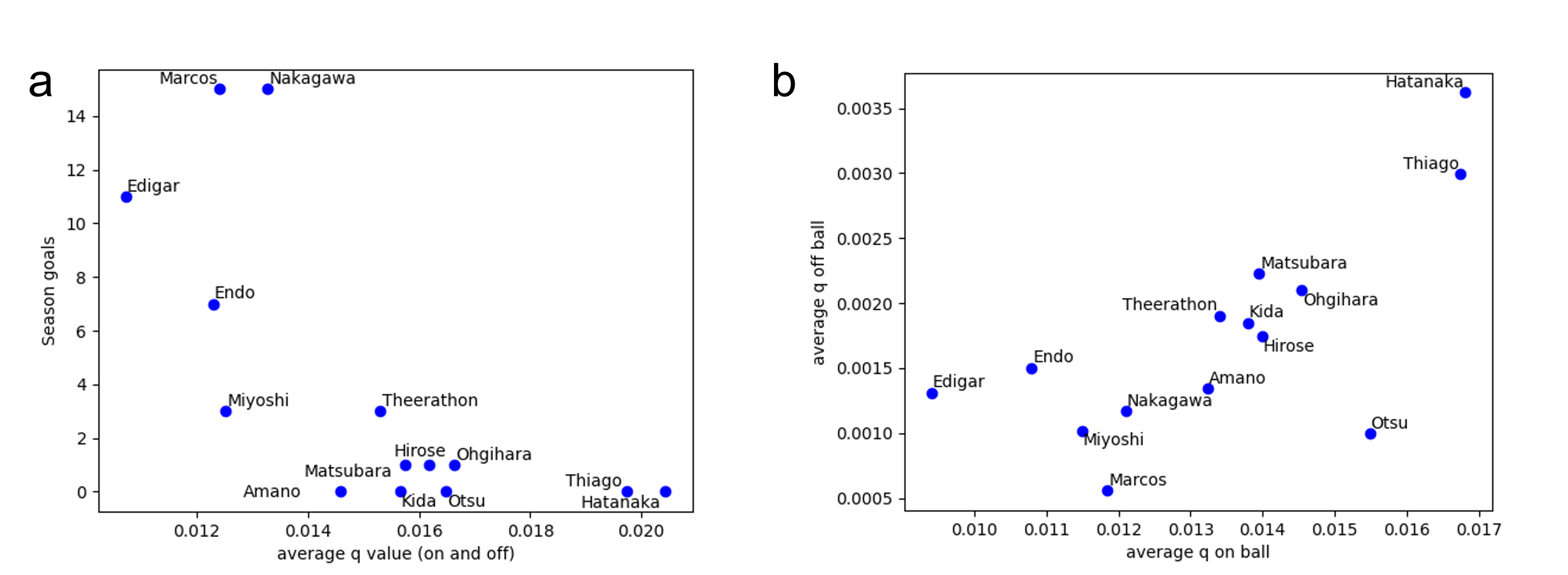
Figure 3: The relationship between (a) average Q-values computed by the proposed method and season goals and (b) average Q-values of on- and off-ball states.
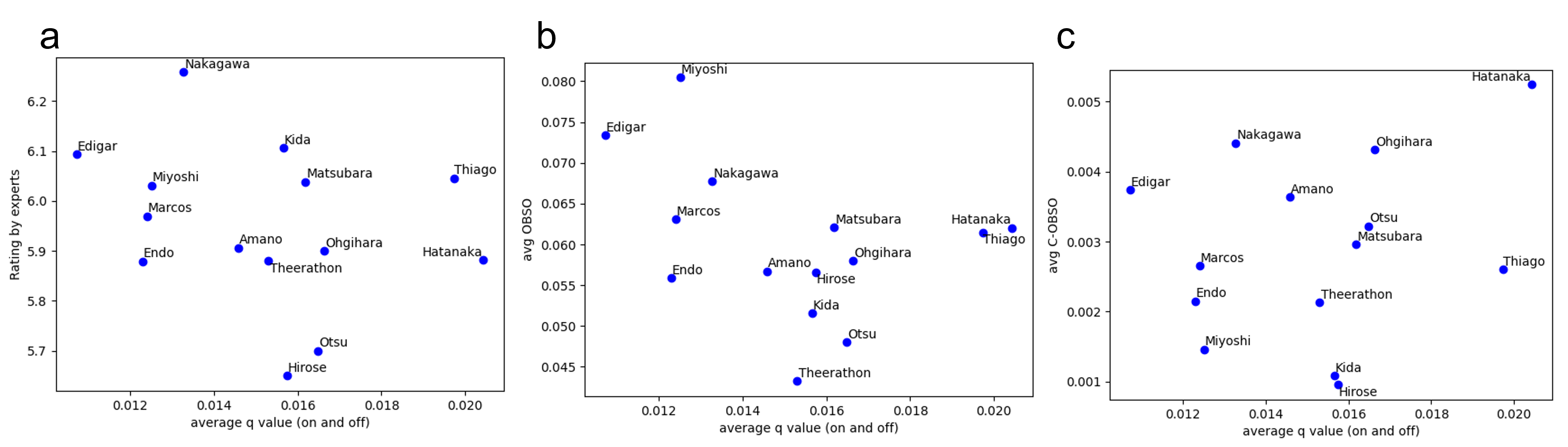
Figure 4: The relationship between average Q-values by the proposed method and (a) the average rating by the experts, (b) OBSO \cite{Spearman18}.
Comparative Analysis
The proposed method was evaluated against other indicators, such as OBSO and C-OBSO. These comparisons underscored the proposed approach's capability to comprehensively value players' impacts, including their indirect contributions through strategic movements and passes. The RL model's valuations effectively identified players' contributions beyond mere goal-scoring, reflecting their overall engagement in playmaking and defense.
Conclusion
The paper presents a deep RL framework augmented with action supervision that systematically values soccer players' contributions in a continuous and dynamic environment. This approach provides meaningful insights into player valuations, offering a tool for coaches, scouts, and teams aiming to enhance team collaboration and extract individual player assessments. Future work may involve refining RL models with more sophisticated reward functions and advancing simulations to bolster player valuation accuracy. The results contribute to strengthening the understanding of tactical behavior modeling in team sports, paving the way for intelligent sports analytics.