- The paper critically examines LLMs’ autonomous planning, finding limited success with only about 34% correctness in Blocksworld tasks.
- The study employs various prompting strategies, including zero-shot, one-shot, and chain-of-thought, to reveal a reliance on contextual cues over abstract reasoning.
- LLM-modulo mode demonstrates heuristic value by guiding external planners and verifiers, while also highlighting challenges in bias mitigation and safety.
On the Planning Abilities of LLMs: A Critical Investigation
Introduction
LLMs, particularly those based on transformer architectures, have gained significant traction in the field of NLP due to their impressive performance in various language processing tasks. However, the extent to which LLMs possess planning capabilities, independently generating executable plans or assisting humans and automated systems in planning tasks, remains unclear. This paper scrutinizes these capabilities by conducting experiments across several domains, focusing on both autonomous mode plan generation and LLM-Modulo mode, where LLMs guide external planners or verifiers.
Figure 1: The diagrammatic overview of the two modes of LLMs for planning.
Autonomous Planning Abilities
Evaluation in Common Planning Domains
This section assesses LLMs' ability to autonomously generate plans in domains like Blocksworld and Logistics. Despite the simplicity of these domains, where humans are generally proficient, LLMs exhibit quite limited success. For instance, even the most advanced model, GPT-4, achieves only approximately 34% correctness in Blocksworld tasks.
Figure 2: Assessment of GPT-4 plans with relaxations in Blocksworld domain.
These models were evaluated under different prompting configurations, including zero-shot, one-shot, and chain-of-thought. The output demonstrates that even state-tracking prompts don't substantially improve performance. Furthermore, obfuscating action and object names in Blocksworld further diminishes LLM effectiveness, revealing a reliance on contextual cues rather than abstract reasoning.
LLM-Modulo Mode
Heuristic Value of LLM-Generated Plans
In heuristic settings, LLM-generated plans can serve as guidance for sound planners like LPG. The experiments show that when LLM-generated plans are provided as initial inputs to LPG, they help reduce search steps required to generate valid plans, indicating their utility as heuristic suggestions.
Figure 3: A detailed comparison of the Blocksworld instances, noting successful plans with prompts including one example.
Interaction with External Verifiers
Another promising approach lies in using LLMs together with external verifiers like VAL. Feedback from these verifiers on the flaws of LLM-generated plans can be backprompted to the LLM, encouraging it to refine its proposals. This process enhances plan correctness in easier domains, but is less effective in domains with deceptive disguising.
Human-in-the-loop Assistance
Further exploration has shown potential in employing LLMs as assistants alongside human planners. Studies indicate no significant increase in plan success rates or subjective task ease when participants receive LLM suggestions, underscoring the challenges of meaningful human-LLM collaboration without bias or error risks.
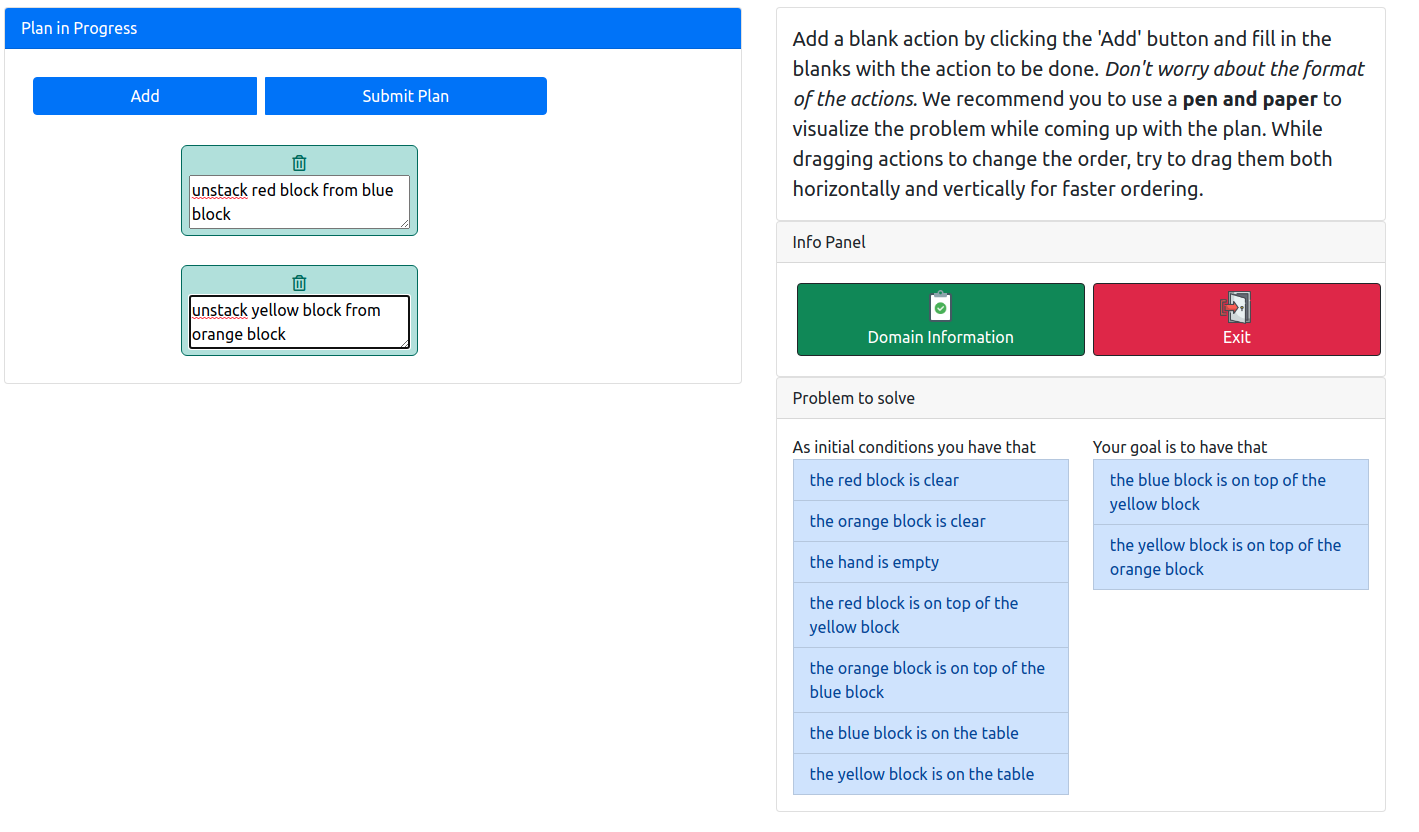
Figure 4: Interface at the plan writing phase without LLM assistance.
Broader Implications
The deployment of LLMs for planning inherently brings potential for perpetuation of biases seen in training data, and challenges in maintaining factual correctness, especially in critical, safety-sensitive domains. Mitigation strategies should include using verified domain models and employing automated or human-led verification steps to ensure plan viability and safety.
Conclusion
The planning capabilities of LLMs, when operating autonomously, remain subpar, particularly in generating executable and goal-achieving plans. Although LLMs show promise when paired with verifiers or sound planners, their autonomous utility is restricted. Future work must address scaling executional reasoning within LLM architectures, alongside robust bias mitigation and safety assurance when employing LLMs in planning-centric applications.

