- The paper demonstrates that grounding and taxonomy-based strategies significantly enhance synthetic data faithfulness for NLP applications.
- The methodology uses sarcasm detection and metrics like macro-F1 to assess the performance of generated data against real-world samples.
- The study highlights practical benefits such as improved model training, reduced annotation needs, and enhanced privacy in data-driven research.
Generating Faithful Synthetic Data with LLMs: A Case Study in Computational Social Science
Introduction
The paper "Generating Faithful Synthetic Data with LLMs: A Case Study in Computational Social Science" addresses the challenge of generating synthetic data that accurately reflects the distribution of real-world data, a crucial issue in NLP. The focus is on enhancing the faithfulness of synthetic data generated by LLMs, which is often unfaithful in its generative distribution when compared to actual data. The paper investigates strategies to mitigate this problem in the context of sarcasm detection and presents grounding, filtering, and taxonomy-based generation as key strategies.
Synthetic Data Generation Challenges
The primary challenge discussed is that synthetic data generated by LLMs often lacks the diversity and authenticity found in real-world data. Simple prompts tend to produce synthetic data that is not reflective of real-world linguistic constructs due to limited topical diversity and stylistic discrepancies. This poses risks in training models that may not perform effectively in real-world applications.
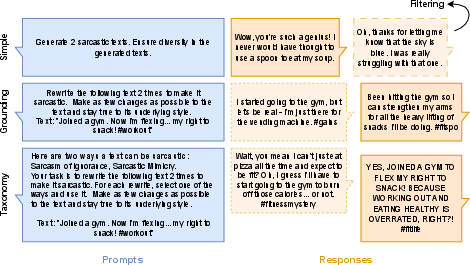
Figure 1: Depiction of the proposed strategies to increase the faithfulness of synthetically generated data.
Proposed Strategies
The paper outlines three approaches to enhance the faithfulness of synthetic data:
- Grounding: This involves integrating real-world examples into the prompting process, thus ensuring that the model generates data with improved topical diversity and construct authenticity.
- Filtering: Implementing a discriminator to identify and discard synthetic data that is easily distinguishable from real data. This aims to enhance the quality of the data that models are trained on by removing unfaithful samples.
- Taxonomy-based Generation: This strategy uses a taxonomy within prompts to diversify the ways in which a construct can be expressed in the generated data.
Methodology
The methods involved deploying these strategies to generate synthetic datasets for sarcasm detection, a task known for its annotation challenges. The evaluation process involved splitting human-annotated data, generating synthetic data using proposed strategies, and training classifiers on these datasets. Performance was measured through metrics such as accuracy and macro-F1 scores, using real-world sarcastic data as a benchmark.
Results and Analysis
The evaluation demonstrates that grounding provides the best performance in terms of macro-F1 scores among the strategies, although it still lags behind zero-shot annotation by LLMs such as ChatGPT.

Figure 2: Our prompting approach consists of four modular steps for generating synthetic data.
- Model Performance: Grounding strategies showed superior performance, with grounded datasets exhibiting higher macro-F1 scores than those generated through simple prompts or filtering.
- Believability Scores: Grounding with taxonomy also resulted in higher believability scores, indicating the data's alignment with real-world styles to some extent.
Implications and Future Work
The findings have significant implications for the deployment of synthetic data in NLP:
- Resource Efficiency: Synthetic data generation, when executed with adequate grounding and diversification strategies, can reduce dependency on exhaustive human annotation.
- Privacy and Ethical Considerations: Using synthetic data addresses privacy concerns tied to real data, crucial for studies involving sensitive information.
- Model Training: These strategies provide a pathway for generating training datasets for smaller models, potentially elucidating avenues for training models in data-constrained environments.
Future work will involve leveraging more advanced LLMs such as GPT-4 and exploring a wider array of NLP tasks. Additionally, improving the evaluation of data faithfulness beyond traditional classifier performance metrics, possibly through human-in-the-loop assessments, is earmarked as a key area of exploration.
Conclusion
The paper advances the field's understanding of how LLMs can be used to generate synthetic data that more faithfully mirrors real-world data distributions. Through careful prompting and filtering strategies, it is possible to produce datasets that enhance the performance of models in detecting complex linguistic constructs such as sarcasm. These approaches hold promise for broader applications in Computational Social Science and beyond, where synthetic data has the potential to revolutionize how linguistic data is utilized and analyzed.

