Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training
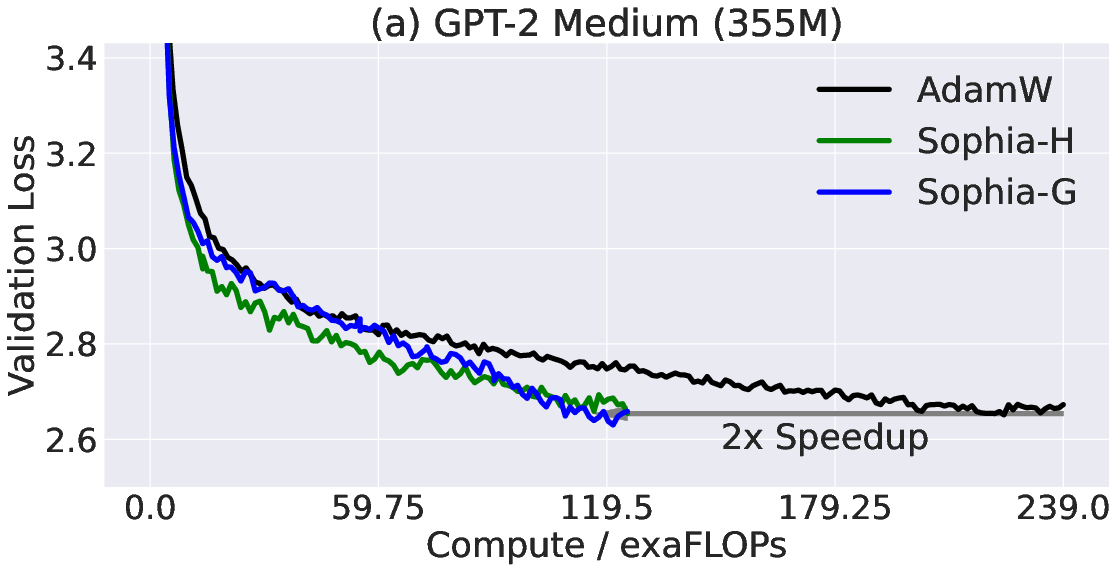
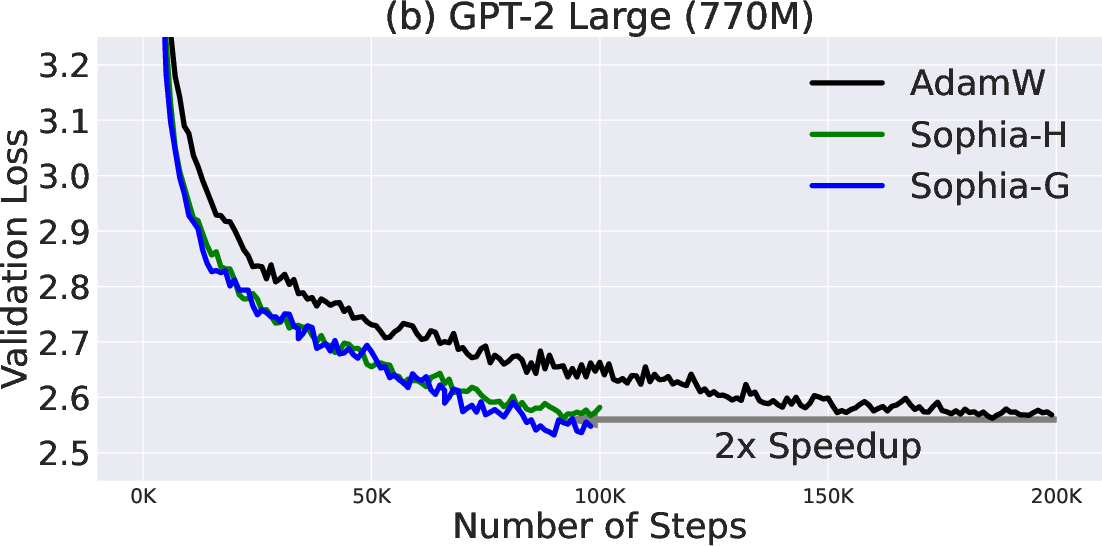
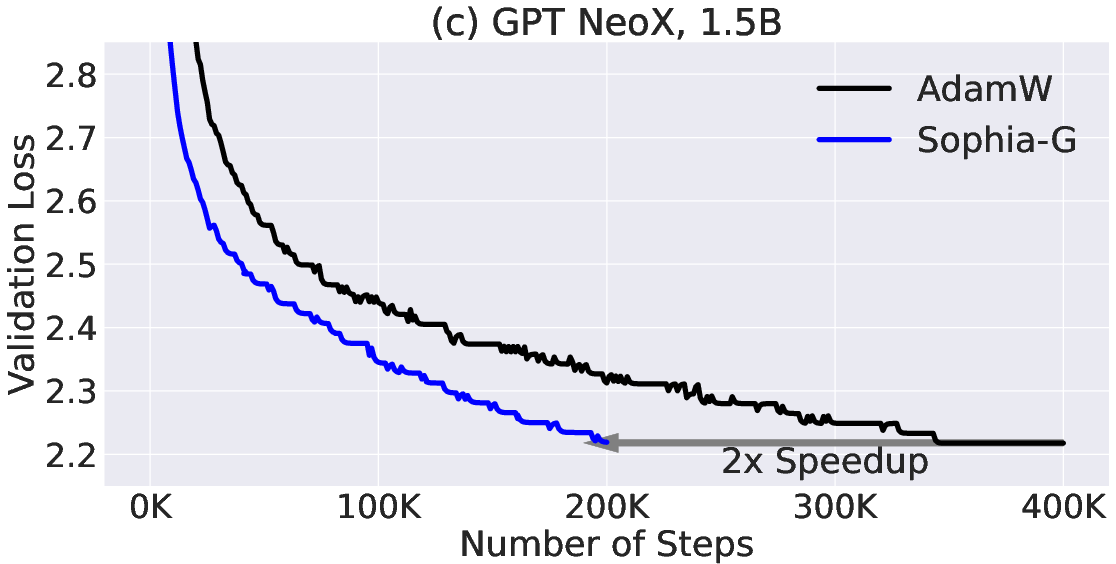
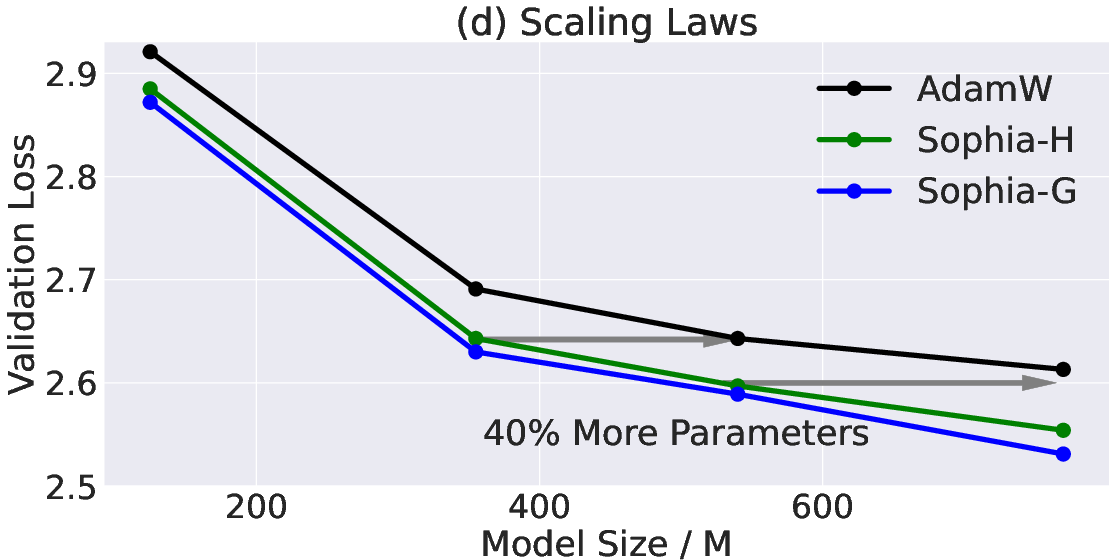
Abstract: Given the massive cost of LLM pre-training, a non-trivial improvement of the optimization algorithm would lead to a material reduction on the time and cost of training. Adam and its variants have been state-of-the-art for years, and more sophisticated second-order (Hessian-based) optimizers often incur too much per-step overhead. In this paper, we propose Sophia, Second-order Clipped Stochastic Optimization, a simple scalable second-order optimizer that uses a light-weight estimate of the diagonal Hessian as the pre-conditioner. The update is the moving average of the gradients divided by the moving average of the estimated Hessian, followed by element-wise clipping. The clipping controls the worst-case update size and tames the negative impact of non-convexity and rapid change of Hessian along the trajectory. Sophia only estimates the diagonal Hessian every handful of iterations, which has negligible average per-step time and memory overhead. On language modeling with GPT models of sizes ranging from 125M to 1.5B, Sophia achieves a 2x speed-up compared to Adam in the number of steps, total compute, and wall-clock time, achieving the same perplexity with 50% fewer steps, less total compute, and reduced wall-clock time. Theoretically, we show that Sophia, in a much simplified setting, adapts to the heterogeneous curvatures in different parameter dimensions, and thus has a run-time bound that does not depend on the condition number of the loss.
- Memory efficient adaptive optimization. Advances in Neural Information Processing Systems, 32, 2019.
- Scalable second order optimization for deep learning. arXiv preprint arXiv:2002.09018, 2020.
- Distributed second-order optimization using kronecker-factored approximations. In International Conference on Learning Representations, 2017.
- Dissecting adam: The sign, magnitude and variance of stochastic gradients. In International Conference on Machine Learning, pp. 404–413. PMLR, 2018.
- Bartlett, M. Approximate confidence intervals. Biometrika, 40(1/2):12–19, 1953.
- Improving the convergence of back-propagation learning with. 1988.
- signsgd: Compressed optimisation for non-convex problems. In International Conference on Machine Learning, pp. 560–569. PMLR, 2018.
- Gpt-neox-20b: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745, 2022.
- Practical gauss-newton optimisation for deep learning. In International Conference on Machine Learning, pp. 557–565. PMLR, 2017.
- Convex optimization. Cambridge university press, 2004.
- JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/google/jax.
- Rprop: a fast adaptive learning algorithm. In Proceedings of the International Symposium on Computer and Information Science VII, 1992.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Broyden, C. G. The convergence of a class of double-rank minimization algorithms 1. general considerations. IMA Journal of Applied Mathematics, 6(1):76–90, 1970.
- Improved preconditioner for hessian free optimization. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning, volume 201. Citeseer, 2011.
- Chen, P. Hessian matrix vs. gauss–newton hessian matrix. SIAM Journal on Numerical Analysis, 49(4):1417–1435, 2011.
- Symbolic discovery of optimization algorithms. arXiv preprint arXiv:2302.06675, 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Trust-region methods, siam. MPS, Philadelphia, 2000.
- Robustness to unbounded smoothness of generalized signsgd. arXiv preprint arXiv:2208.11195, 2022.
- Numerical methods for unconstrained optimization and nonlinear equations. SIAM, 1996.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dozat, T. Incorporating nesterov momentum into adam. 2016.
- Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul):2121–2159, 2011.
- The Pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
- On the promise of the stochastic generalized gauss-newton method for training dnns. arXiv preprint arXiv:2006.02409, 2020.
- Fast approximate natural gradient descent in a kronecker factored eigenbasis. Advances in Neural Information Processing Systems, 31, 2018.
- An investigation into neural net optimization via hessian eigenvalue density. In International Conference on Machine Learning, pp. 2232–2241. PMLR, 2019.
- Openwebtext corpus, 2019.
- Grosse, R. Neural Network Training Dynamics. 2022.
- A kronecker-factored approximate fisher matrix for convolution layers. In International Conference on Machine Learning, pp. 573–582. PMLR, 2016.
- Shampoo: Preconditioned stochastic tensor optimization. In International Conference on Machine Learning, pp. 1842–1850. PMLR, 2018.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Neural networks for machine learning lecture 6a overview of mini-batch gradient descent. Cited on, 14(8):2, 2012.
- Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Hutchinson, M. F. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines. Communications in Statistics-Simulation and Computation, 18(3):1059–1076, 1989.
- How to train bert with an academic budget. arXiv preprint arXiv:2104.07705, 2021.
- Doubly adaptive scaled algorithm for machine learning using second-order information. arXiv preprint arXiv:2109.05198, 2021.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Mistral – a journey towards reproducible language model training. https://crfm.stanford.edu/2021/08/26/mistral.html, 2021.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Limitations of the empirical fisher approximation for natural gradient descent. Advances in neural information processing systems, 32, 2019.
- Noise is not the main factor behind the gap between sgd and adam on transformers, but sign descent might be. arXiv preprint arXiv:2304.13960, 2023.
- Understanding the difficulty of training transformers. arXiv preprint arXiv:2004.08249, 2020.
- Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Stability and convergence of stochastic gradient clipping: Beyond lipschitz continuity and smoothness. In International Conference on Machine Learning, pp. 7325–7335. PMLR, 2021.
- Martens, J. New insights and perspectives on the natural gradient method. The Journal of Machine Learning Research, 21(1):5776–5851, 2020.
- Optimizing neural networks with kronecker-factored approximate curvature. In International conference on machine learning, pp. 2408–2417. PMLR, 2015.
- Kronecker-factored curvature approximations for recurrent neural networks. In International Conference on Learning Representations, 2018.
- Martens, J. et al. Deep learning via hessian-free optimization. In ICML, volume 27, pp. 735–742, 2010.
- Regularizing and optimizing lstm language models. arXiv preprint arXiv:1708.02182, 2017.
- Cubic regularization of newton method and its global performance. Mathematical Programming, 108(1):177–205, 2006.
- OpenAI. Gpt-4 technical report. arXiv, 2023.
- Iterative solution of nonlinear equations in several variables. SIAM, 2000.
- Revisiting natural gradient for deep networks. arXiv preprint arXiv:1301.3584, 2013.
- Pytorch: An imperative style, high-performance deep learning library. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 32, pp. 8024–8035. Curran Associates, Inc., 2019. URL http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21:1–67, 2020.
- On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237, 2019.
- Improved bounds on sample size for implicit matrix trace estimators. Foundations of Computational Mathematics, 15(5):1187–1212, 2015.
- Eigenvalues of the hessian in deep learning: Singularity and beyond. arXiv preprint arXiv:1611.07476, 2016.
- A deeper look at the hessian eigenspectrum of deep neural networks and its applications to regularization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 9481–9488, 2021.
- No more pesky learning rates. In International conference on machine learning, pp. 343–351. PMLR, 2013.
- Schraudolph, N. N. Fast curvature matrix-vector products for second-order gradient descent. Neural computation, 14(7):1723–1738, 2002.
- Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning, pp. 4596–4604. PMLR, 2018.
- Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
- Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32, 2019.
- The implicit and explicit regularization effects of dropout. arXiv preprint arXiv:2002.12915, 2020.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.
- Pyhessian: Neural networks through the lens of the hessian. In 2020 IEEE international conference on big data (Big data), pp. 581–590. IEEE, 2020.
- Adahessian: An adaptive second order optimizer for machine learning. In proceedings of the AAAI conference on artificial intelligence, volume 35, pp. 10665–10673, 2021.
- Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv:1904.00962, 2019.
- Why gradient clipping accelerates training: A theoretical justification for adaptivity. arXiv preprint arXiv:1905.11881, 2019.
- Why are adaptive methods good for attention models? Advances in Neural Information Processing Systems, 33:15383–15393, 2020.
- Eva: Practical second-order optimization with kronecker-vectorized approximation. In The Eleventh International Conference on Learning Representations, 2022a.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022b.
- Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. Advances in neural information processing systems, 33:18795–18806, 2020.
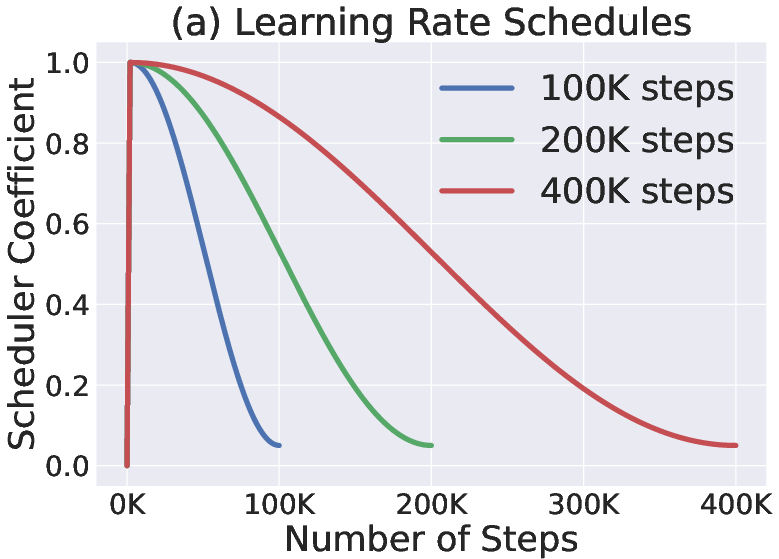
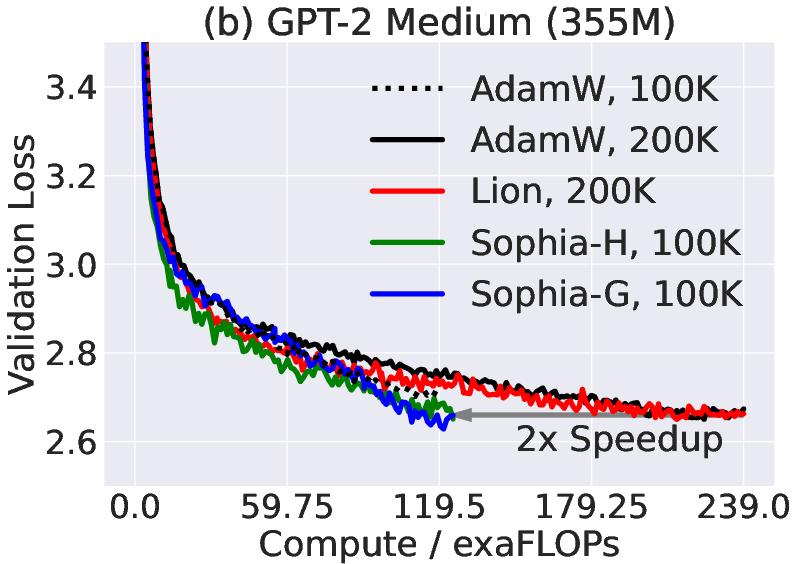
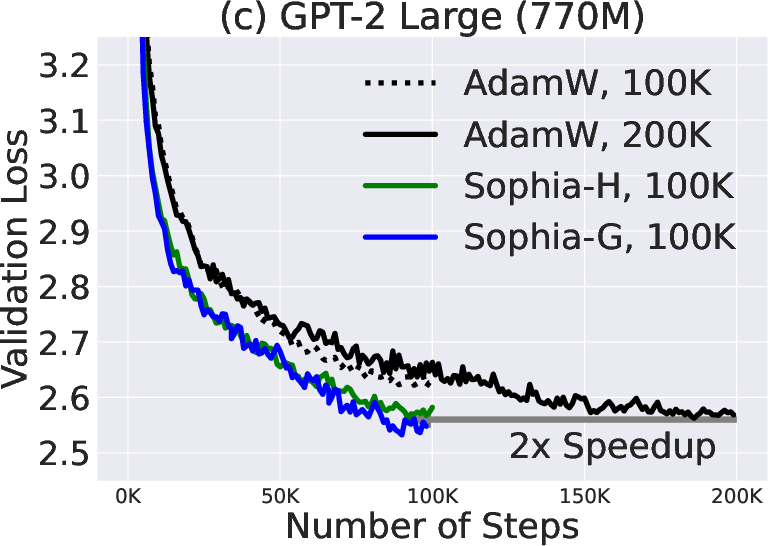
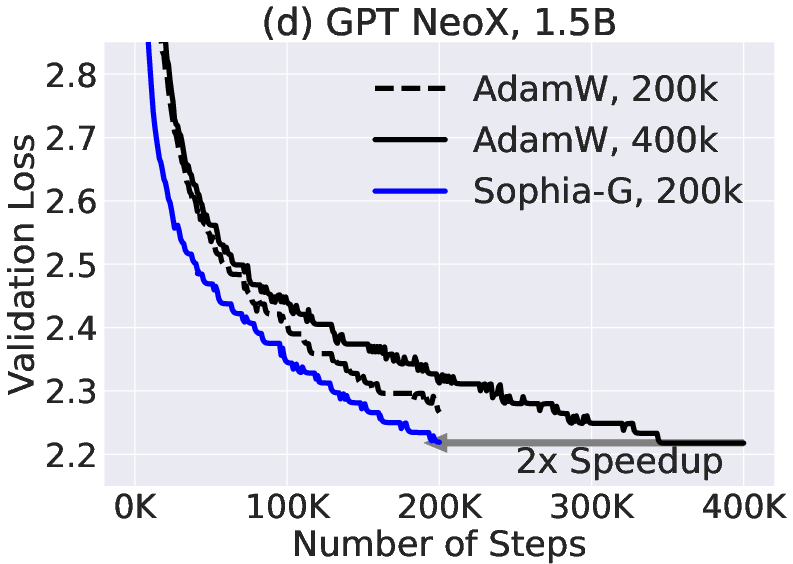
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.