- The paper demonstrates that multilingual LLMs underperform on code-switched inputs compared to fine-tuned models across several tasks.
- It benchmarks CSW tasks including sentiment analysis, machine translation, summarization, and language identification using diverse language pair datasets.
- The study advocates for improved CSW data representation and training strategies to enhance the robustness and inclusivity of multilingual LLMs.
Multilingual LLMs Are Not (Yet) Code-Switchers
The paper "Multilingual LLMs Are Not (Yet) Code-Switchers" (2305.14235) provides an empirical analysis aimed at evaluating the current capabilities of multilingual LLMs in processing code-switching (CSW) tasks. Despite LLMs exhibiting proficiency in multilingual settings using zero-shot and few-shot prompting, their effectiveness in dealing with CSW remains suboptimal.
Introduction to Code-Switching and Multilingual LLMs
Code-switching involves the alternating use of multiple languages within a conversation, posing a challenge for NLP due to its highly colloquial nature and the scarcity of annotated data. Multilingual LLMs, although effective in monolingual contexts, often struggle with CSW due to the absence of specialized training. This paper benchmarks various LLMs across tasks like sentiment analysis, machine translation, summarization, and language identification to explore their CSW proficiency.
Experimental Setup
Datasets and Tasks
The study investigates four CSW task categories:
- Sentiment Analysis: Examines datasets from Spanish-English, Malayalam-English, and Tamil-English, focusing on binary sentiment classification.
- Machine Translation: Utilizes Hinglish-English sentence pairs to evaluate translation performance.
- Summarization: Leverages the Gupshup dataset for Hinglish to English summaries.
- Word-Level Language Identification (LID): Includes tasks involving Hindi-English and Standard-Egyptian Arabic data.
Models Evaluated
The study considers numerous multilingual LLMs, including BLOOMZ, mT0, XGLM, and ChatGPT, examining their performance in zero-shot, few-shot, and fine-tuning contexts. The comparison reveals a substantial performance deficit in LLMs when handling code-switched inputs as opposed to monolingual tasks.
Results and Discussion
Despite scaling advantages, multilingual LLMs fall short compared to smaller fine-tuned models across various tasks.
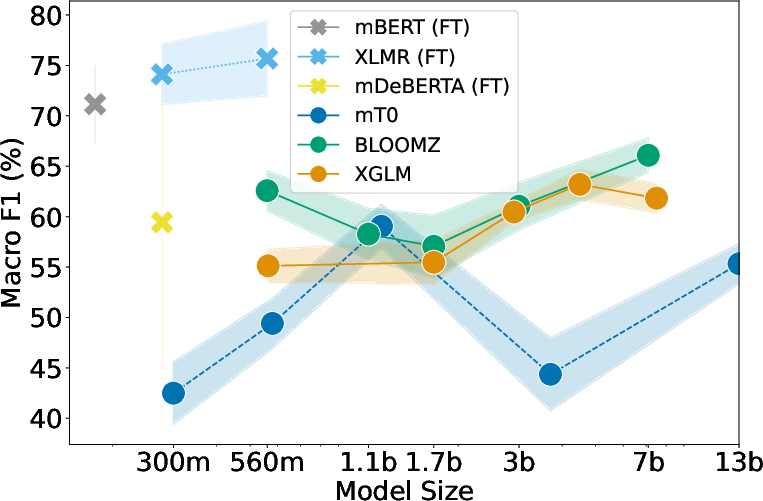
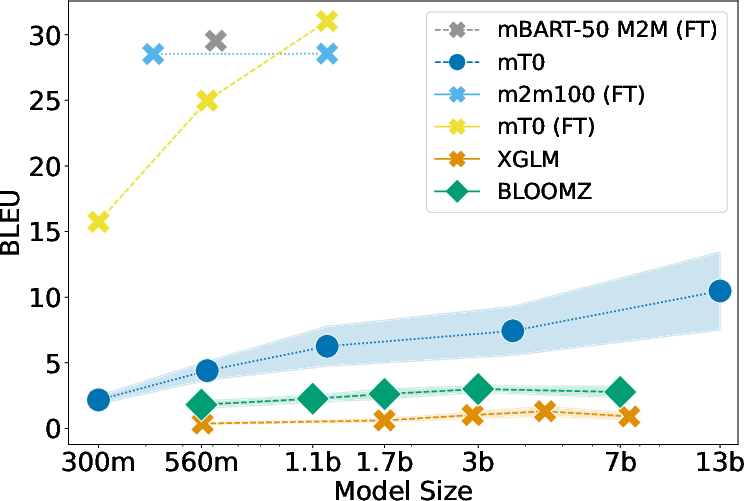
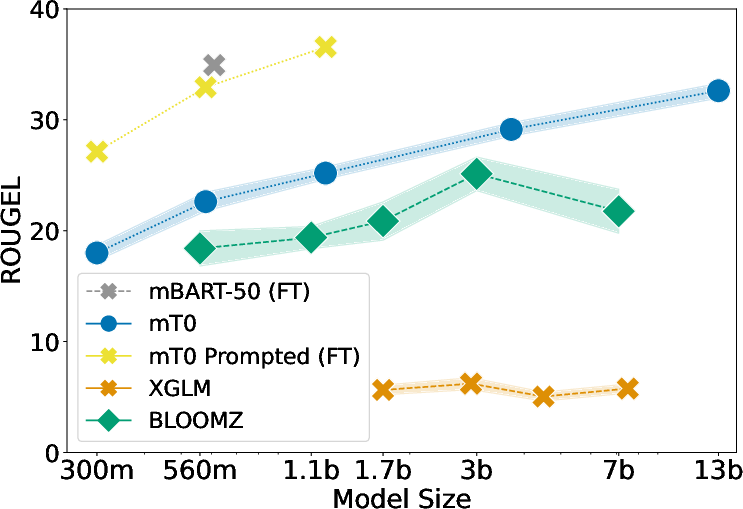
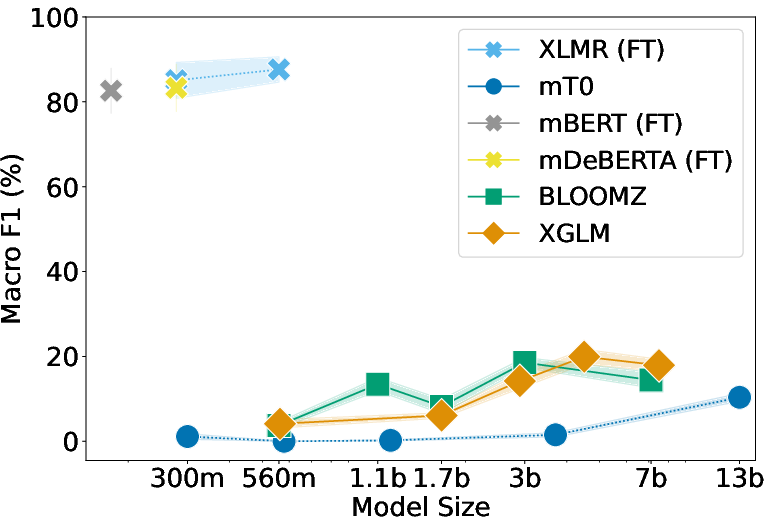
Figure 1: Evaluation results of fine-tuning and prompting LLMs of different scales on various CSW tasks. (top left) F1-score on the sentiment analysis task, (top right) BLEU score on the machine translation task, (bottom left) ROUGE-L on the summarization task, and (bottom right) F1-score on the word-level language identification task. (FT) means results are from fine-tuned models.
Sentiment Analysis
Fine-tuned models outperform larger LLMs across all sentiment datasets, indicating a struggle for mT0 and other models to grasp sentiment in CSW contexts.
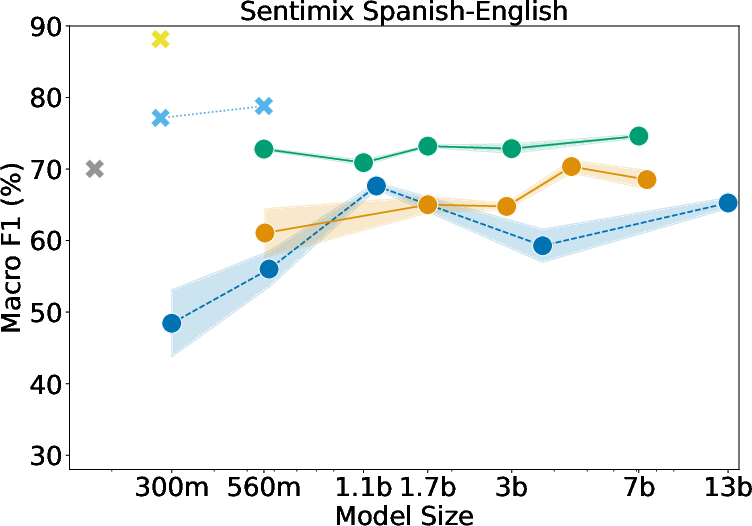
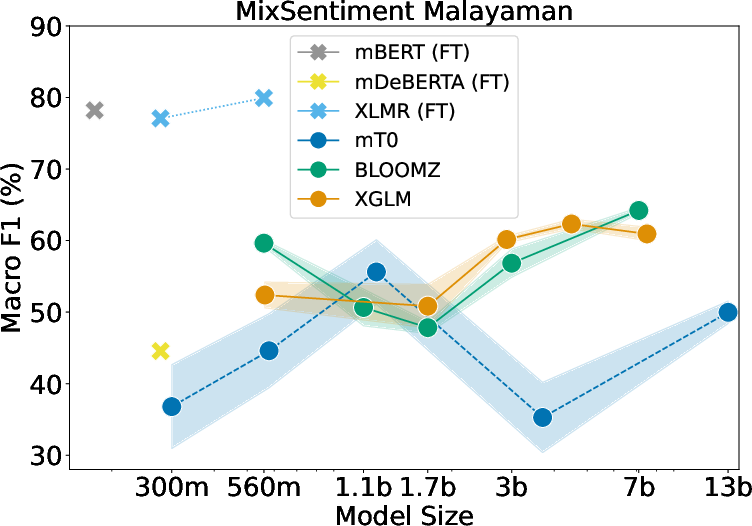
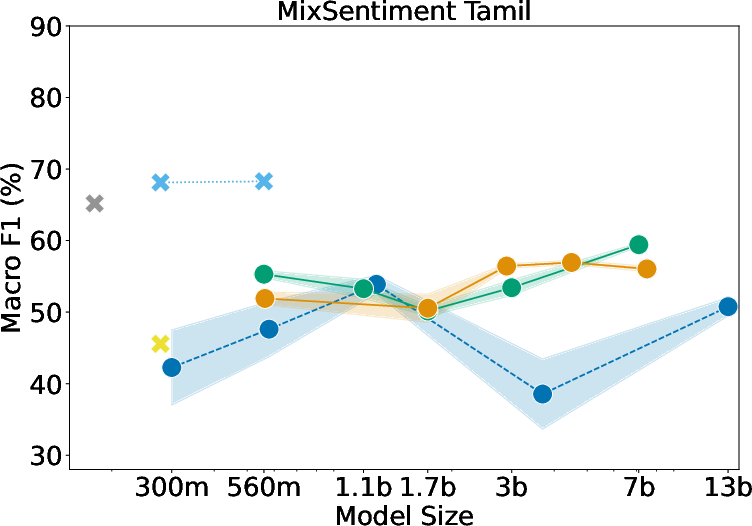
Figure 2: LLMs' sentiment analysis evaluation on (left) Sentimix Spanish-English, (center) MixSentiment Malayaman-English, and (right) MixSentiment Tamil-English.
Machine Translation
The performance gap is particularly noticeable in Hinglish-English translation tasks, with fine-tuned models achieving significantly higher BLEU scores.
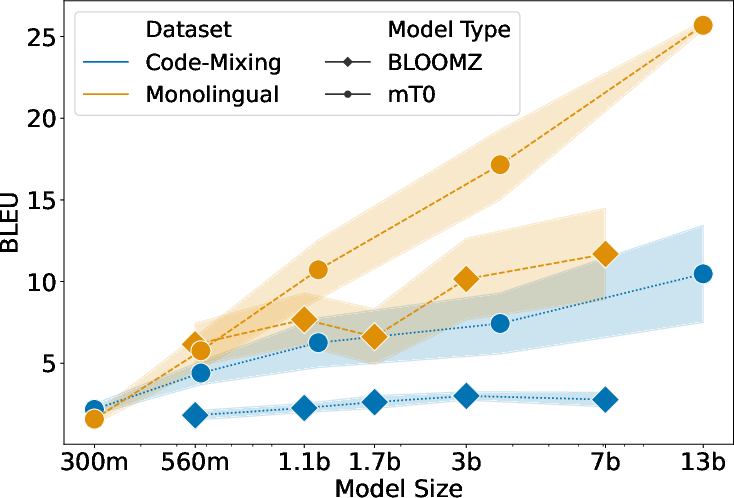
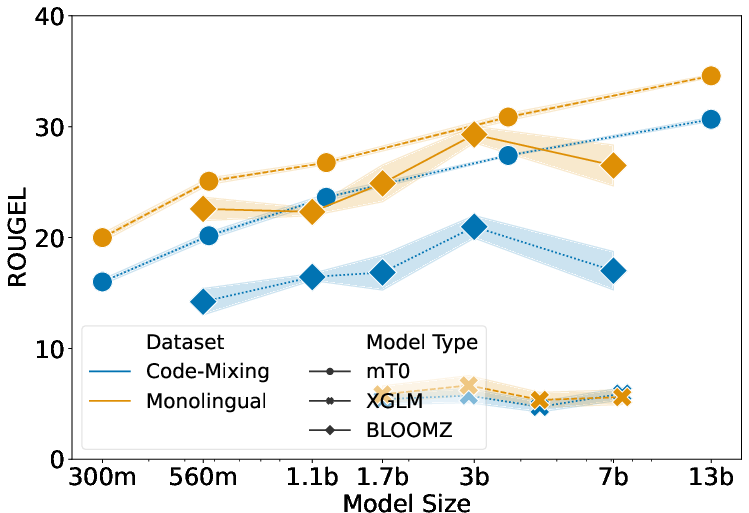
Figure 3: Performance comparison on (top) Hindi→English vs Hinglish→English translation and (bottom) Hinglish→English vs English→English summarization.
Summarization and Language Identification
Fine-tuned strategies remain superior in both summarization and LID tasks. Zero-shot and few-shot performances indicate LLMs' difficulties with CSW text structures, requiring more input examples to approach fine-tuned performance levels.
Implications for Future Research
For LLMs to excel in CSW contexts, enhancements are necessary in several areas:
- Data Representation: Better representation of CSW data is required during multilingual pretraining.
- Optimization Objectives: Adapting meta transfer learning and token-span LID objectives may enrich LLMs with more robust CSW capabilities.
- Inclusive Language Technology: Incorporating CSW features into LLMs could improve LLMs' inclusivity, reflecting users' authentic linguistic identities.
Conclusion
This study underscores the inadequacies of current multilingual LLMs in handling CSW scenarios, stressing the need for improved data and training strategies aimed at integrating CSW as a core feature. Future work should aim to develop comprehensive evaluation frameworks and create richer CSW datasets to advance LLM capabilities in this domain.

