- The paper introduces a data synthesis framework that leverages LLMs and Wikipedia document relationships to generate multi-hop QA pairs.
- It fine-tunes smaller language models using fewer than ten annotated QA pairs, achieving significant performance gains.
- Evaluation on benchmarks like HotpotQA and FEVER demonstrates improvements of up to 19.9 points, highlighting practical efficacy.
Few-Shot Data Synthesis for Open Domain Multi-Hop Question Answering
Introduction
This paper addresses the challenge of few-shot learning for open domain multi-hop question answering (MQA) by introducing a data synthesis framework designed to improve smaller LLMs, requiring less than ten human-annotated QA pairs. The proposed framework leverages naturally-occurring document relationships and LLMs for data generation, enabling the synthesis of millions of multi-hop questions and claims used for fine-tuning smaller LLMs.
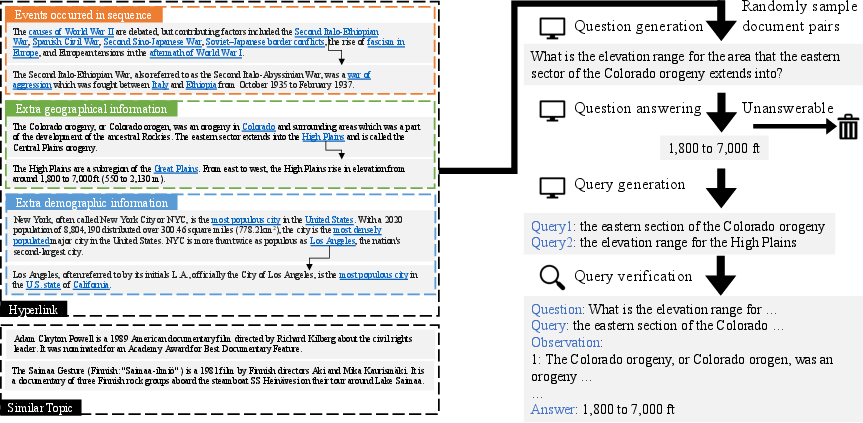
Figure 1: An illustration of the overall pipeline of our proposed approach. Each data instance in our synthesized dataset consists of a question, queries and their corresponding retrieved documents, and an answer. We first prompt LLMs to synthesize questions and queries, finetune models on the synthesized data, and then evaluate the finetuned models on downstream tasks that require iteratively querying retrieval corpora.
Data Synthesis Framework
The data synthesis process involves generating MQA data using Wikipedia documents that exhibit varying forms of relationships—similar topics, hyperlinked entities, or events in sequence. This approach is minimally dependent on hand-crafted features, relying on LLMs for generating questions, answers, and queries through prompts.
Data Preparation: Wikipedia, chosen for comprehensive knowledge coverage, is used to create document pairs. Topics are extracted using a finetuned RoBERTa model, and document pairs are sampled based on hyperlink connections or topic clusters. Answers are randomly chosen from named entities or document titles.
Question Generation: LLMs generate questions using prepared document pairs and assigned answers. Different prompt examples cater to varying generation tasks, ensuring diversity in reasoning types—comparison and nested.

Figure 2: Prompt excerpts for the question generation task for the ``hyper'' setting. The red text is the expected model generation for the given prompt. The complete prompt contains four examples and is included in \Cref{appendix-sec:prompts.
Question Answering: To ensure generated questions accurately reflect document content, LLMs predict answers and verify with a threshold F1 score. The process distinguishes between single- and two-hop questions, leveraging adequacy checking prompts.

Figure 3: Prompt excerpts for the question answering task for the ``hyper'' setting. The red text is the expected model generation for the given prompt.
Query Generation and Verification: Candidate queries for retrieval verification are generated using LLMs, validated against Wikipedia documents using a retriever. Queries are filtered to retain those effectively retrieving source or related documents.

Figure 4: Prompt excerpts for the query generation task for the ``hyper'' setting.
Experimental Evaluation
Experiments demonstrate the framework's effectiveness by finetuning models on synthesized multi-hop QA data and evaluating performance against established benchmarks such as HotpotQA and FEVER.
Results: Finetuned LLaMA models outperform prior work’s results and prove competitive with larger models like GPT-3.5, showing gains of 19.9 points for 7B models and 13.2 points for the 65B models, underscoring the efficacy of the synthesized data—especially in self-training scenarios.
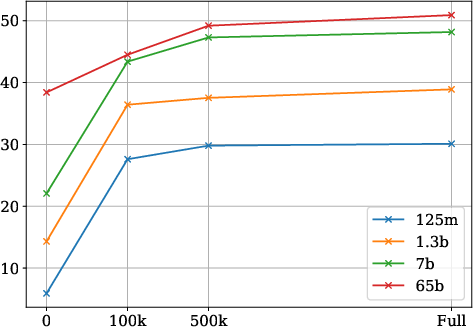
Figure 5: Average dataset performance for HotpotQA, MuSiQue, 2WikiQA, and FEVER. We vary the amount of finetuning data and model sizes. We report model performance using SelfAsk when the amount of finetuning data equals to zero.
Analysis: Further analysis reveals data quantity's impact on model performance, noting diminishing returns beyond a certain volume. Diversity in document relationships appears essential for enriching training data and supporting model efficacy across reasoning tasks.
Conclusion
The research presents a robust framework for few-shot data synthesis for MQA, showing substantial performance improvements for LLMs sized smaller than contemporary industry leaders. The practical applicability extends to various reasoning tasks, with promising outcomes across diverse benchmarks. Future investigations could refine finetuning data strategies or extend generalization capabilities to other domains, supporting broader AI developments.
Limitations
Though effective, the approach incurs substantial data synthesis costs, necessitates powerful LLMs, and hinges on model finetuning—constraints that may limit applicability to closed-source models or smaller research initiatives.
Overall, the paper underscores the importance of leveraging LLMs for efficacious data synthesis, advancing the capabilities of smaller models in multi-hop QA scenarios through innovative prompt-based strategies and minimal reliance on handcrafted input.