- The paper introduces a novel embedding-based domain-adaptive pre-training method that updates only the embedding layer, preventing catastrophic forgetting.
- It employs meta-embedding strategies, using both averaging and attention mechanisms, to integrate domain-specific information effectively.
- Experimental results across 14 domains demonstrate improved performance in tasks like NER and NLI, particularly in few-shot and low-resource settings.
Efficient Task-Agnostic Domain Adaptation for Transformers
Introduction
The paper "TADA: Efficient Task-Agnostic Domain Adaptation for Transformers" (2305.12717) introduces a modular and parameter-efficient approach for domain adaptation using transformer-based LLMs. This method, called TADA, focuses on improving the efficiency of domain adaptation without introducing additional parameters, while maintaining robust performance across multiple NLP tasks and domains.
The motivation for developing TADA arises from the challenges associated with traditional domain-adaptive pre-training methods, which are often resource-intensive and prone to catastrophic forgetting. The paper proposes a novel embedding-based intermediate training method that addresses these issues by updating only the embedding layer, while freezing the other transformer parameters, thus retaining the pre-existing knowledge in the model.
TADA Framework
The TADA framework consists of two main steps as depicted in the overview figure (Figure 1).
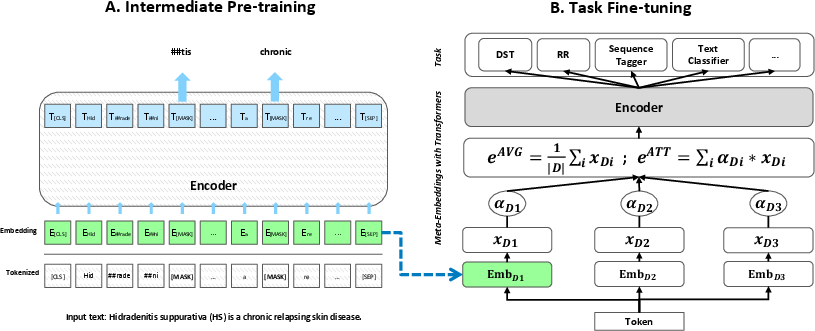
Figure 1: Overview of the TADA framework consisting of two steps. Part A: Domain specialization is performed via embedding-based domain-adaptive intermediate pre-training with Masked Language Modeling (MLM) objective on in-domain data. Part B: The domain-specialized embeddings are then fine-tuned for downstream tasks in single- or multi-domain scenarios with two meta-embeddings methods: average (AVG) and attention-based (ATT).
Domain Specialization
Domain specialization in TADA is achieved through an embedding-based domain-adaptive pre-training approach. Unlike full domain-adaptive pre-training that updates all parameters of the pre-trained transformer-based LLMs (PTLMs), TADA updates only the domain-specialized embeddings, keeping the rest of the model parameters fixed. This prevents negative interference and catastrophic forgetting while injecting domain-specific knowledge into the model.
After obtaining the domain-specialized embeddings, TADA employs meta-embedding techniques to combine information from multiple domain sources. Two variants of meta-embeddings are explored: averaging (AVG) and attention-based (ATT). AVG utilizes a simple unweighted mean of embeddings, while ATT employs dynamic attention weights for a more nuanced integration based on the current input context.
TADA introduces meta-tokenization as a way to handle domain-specific tokenization using multiple tokenizers. This method aggregates tokenized outputs from different domain-specialized tokenizers with three strategies: space-based aggregation, dynamic aggregation, and truncation. This ensures consistent input representations across different domains, enhancing the robustness of multi-domain models.
Results and Discussion
The evaluation of TADA on four downstream tasks—dialog state tracking (DST), response retrieval (RR), named entity recognition (NER), and natural language inference (NLI)—across 14 domains demonstrates its effectiveness. TADA not only competes with state-of-the-art domain adaptation methods but also shows advantages in few-shot and low-resource settings, making it highly applicable for real-world scenarios where data constraints are prevalent.
The experimental results highlight that TADA, with its parameter-efficient design, achieves substantial performance improvements, particularly in the RR and DST tasks where domain-specific context is crucial. Additionally, the incorporation of meta-tokenizers shows promising results, although further refinement and study are suggested to fully leverage domain-specialized tokenizers in such a setup.
Implications and Future Work
The implications of TADA are significant for improving the efficiency and applicability of domain-adaptive transformer models in NLP. By reducing the computational requirements and alleviating the need for extensive pre-training, TADA positions itself as a sustainable option for both academic research and industry deployment.
Future work could focus on expanding the scope of TADA to encoder-decoder transformer models for tasks like text generation and summarization. Additionally, exploring multilingual setups and enhancing meta-tokenizer methodologies could provide further insights and improvements in domain adaptation.
Conclusion
Overall, "TADA: Efficient Task-Agnostic Domain Adaptation for Transformers" introduces an innovative approach to domain adaptation with a focus on efficiency and modularity. By leveraging domain-specialized embeddings without altering the model parameters significantly, TADA offers a robust platform for deploying NLP models across varied domains effectively and sustainably.

