- The paper introduces AutoTrial, a novel method leveraging LLMs to generate nuanced clinical trial eligibility criteria.
- It employs a multi-stage training framework with hybrid prompting, integrating both discrete and neural mechanisms for dynamic instruction handling.
- Evaluation shows high clinical accuracy with an F1 score of 0.91 and over 60% human evaluation winning rate against GPT-3.5.
AutoTrial: Prompting LLMs for Clinical Trial Design
The paper "AutoTrial: Prompting LLMs for Clinical Trial Design" introduces a novel approach to leveraging LLMs in the construction of clinical trial eligibility criteria. This method, named AutoTrial, is designed to enhance the process of drafting inclusion and exclusion criteria critical for patient recruitment in clinical trials, a task known for its complexity and susceptibility to revisions.
Methodology
Architecture Overview
AutoTrial employs a multi-stage training framework (Figure 1), which consists of pretraining on a large corpus of unlabeled trial documents followed by a finetuning phase. This methodology allows for the incorporation of domain-specific knowledge and the ability to generate nuanced and actionable trial criteria based on given instructions.
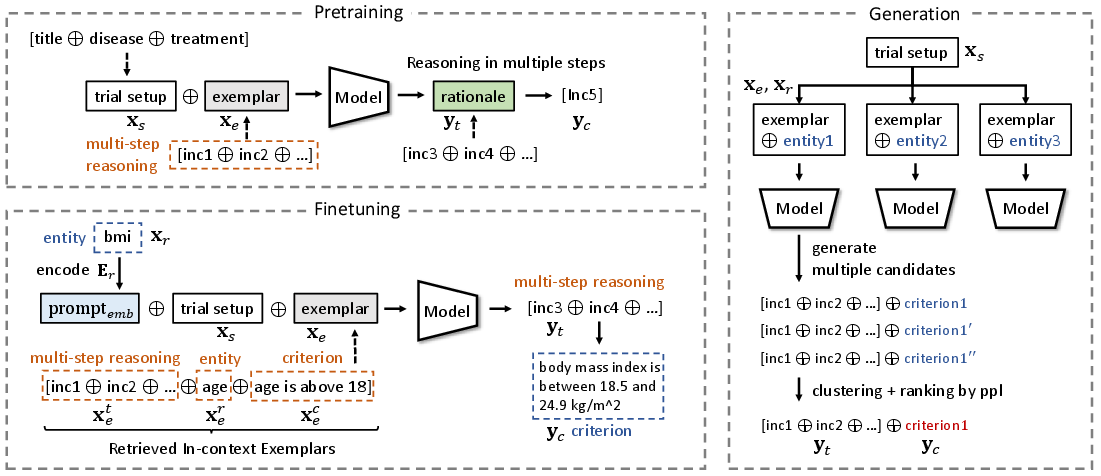
Figure 1: The workflow of the proposed AutoTrial showing the pretraining and finetuning stages.
Hybrid Prompting Technique
AutoTrial integrates both discrete and neural prompting mechanisms. Discrete prompts, imbued with specific trial instructions, enhance the model's comprehension and ability to replicate nuanced eligibility criteria using in-context examples. Neural prompts are adeptly used to manage instructions dynamically, allowing the system to accommodate expanding datasets without complete retraining—a crucial feature for applying LLMs in clinical settings.
Multi-step Reasoning and Knowledge Integration
By facilitating explicit multi-step reasoning and leveraging retrieval-augmented generation, AutoTrial achieves significant transparency and consistency in its outputs. A dense retriever model, Trial2Vec, enables the system to integrate external knowledge flexibly, further enriching the generation process. This capability is particularly beneficial in maintaining the model’s performance as new clinical insights and trial data become available.
Evaluation
The evaluation of AutoTrial reveals its superiority in both automatic metrics (e.g., BLEU, METEOR) and clinical accuracy when compared to established models including GPT-3.5. Its robust performance is affirmed by high precision and recall metrics, a testament to its capacity for generating relevant and comprehensive trial criteria. Notably, AutoTrial achieves an F1 score of 0.91 and a Jaccard score of 0.84 in clinical accuracy evaluations, significantly outperforming other methods.
Incremental Learning and Adaptation
AutoTrial demonstrates an effective incremental learning approach, retaining performance across expansions of the database with minimal degradation. The paper outlines a practical strategy for periodic updates to the system's knowledge base, emphasizing the balance between utility and operational cost.
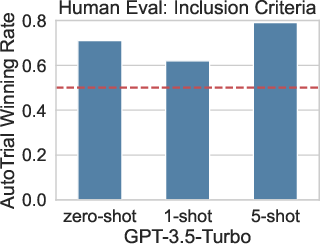
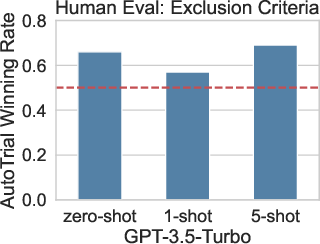
Figure 2: Human evaluations of the winning rate of AutoTrial against GPT-3.5.
Human Evaluation
When assessed against human-generated criteria, AutoTrial attains a winning rate of over 60% against GPT-3.5 in human evaluations, underscoring its practical relevance in real-world clinical trial planning. This performance reflects not only its technical proficiency but also the meaningfulness of its outputs when judged by expert standards.
Implications and Future Work
The introduction of AutoTrial into the clinical trial design process heralds significant implications for the integration of AI in medical research. By ensuring more accurate and comprehensive trial designs, AutoTrial could reduce the frequency of costly and time-consuming protocol amendments. The method's scalability and adaptability position it as a valuable tool for tackling evolving clinical challenges, ensuring that trial frameworks keep pace with advancements in medical science.
Looking forward, further research could explore enhancing the system's reasoning capabilities and integrating more sophisticated domain-specific knowledge bases. As AI continues to evolve, the potential for such systems to transform clinical research and development becomes increasingly feasible.
Conclusion
AutoTrial represents a significant advancement in the application of LLMs to clinical trial design, addressing critical challenges in trial criteria generation. By combining sophisticated prompting, robust reasoning mechanisms, and scalable updating strategies, AutoTrial lays the groundwork for more efficient and effective clinical trials, ultimately contributing to the broader field of AI-driven healthcare solutions.

