AI-Augmented Surveys: Leveraging Large Language Models and Surveys for Opinion Prediction
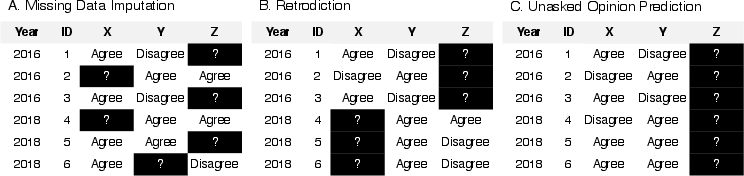
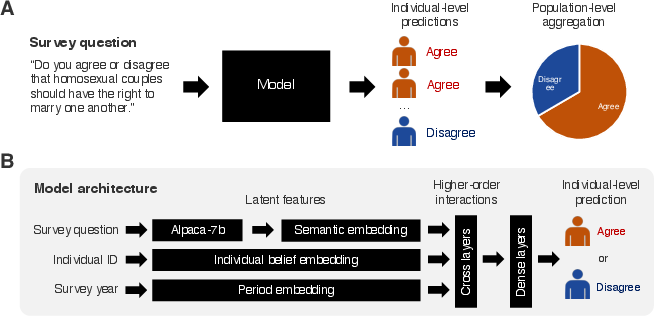
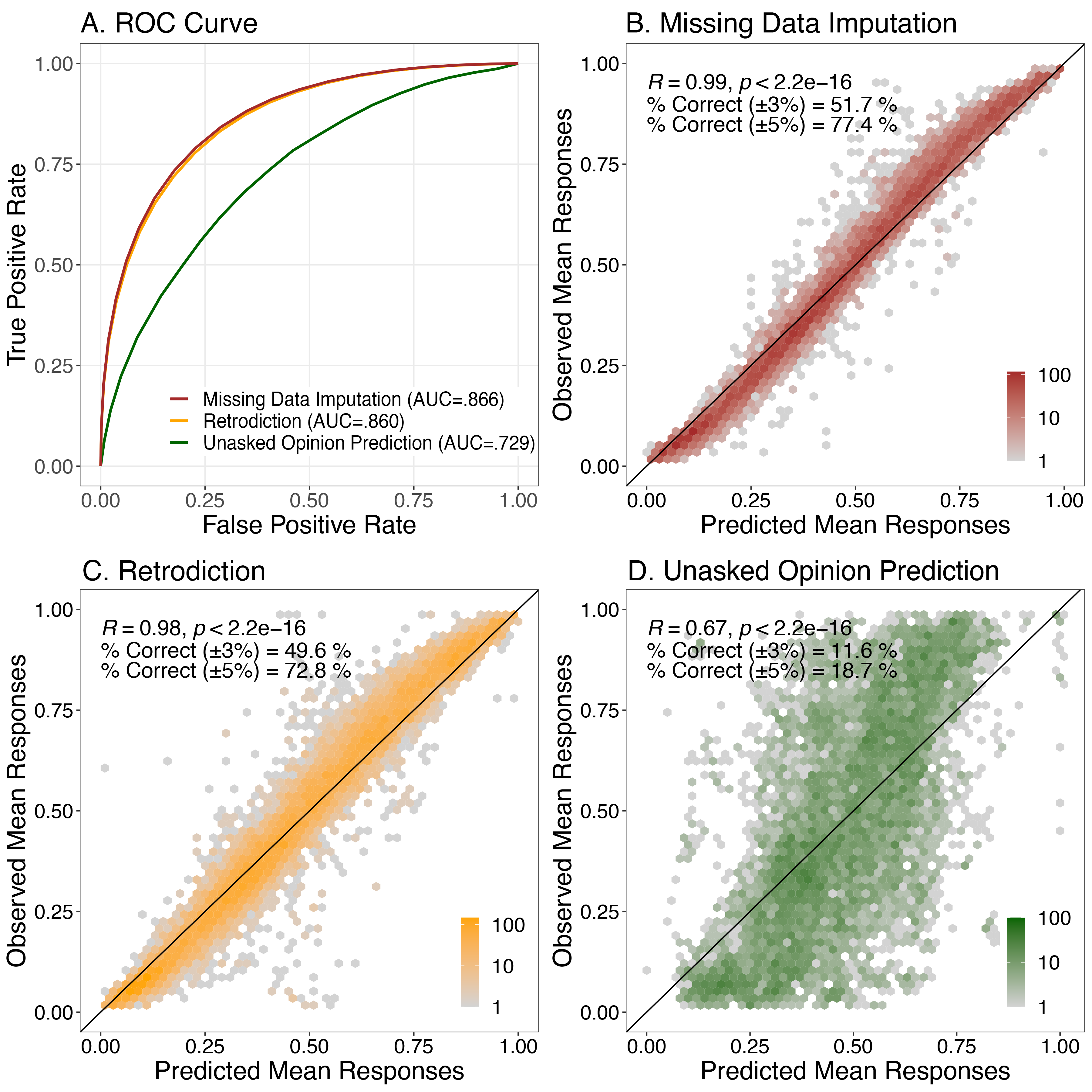
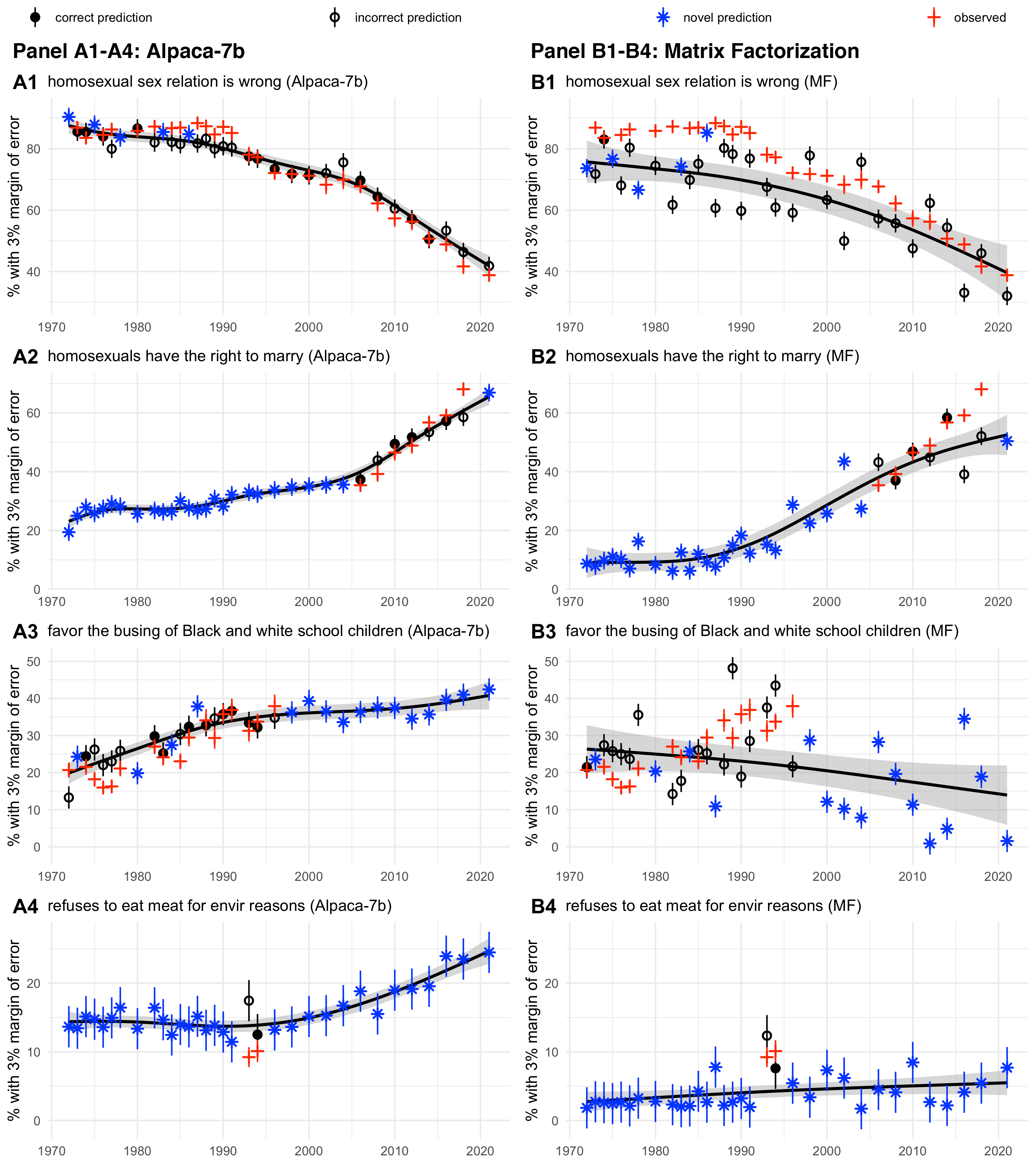
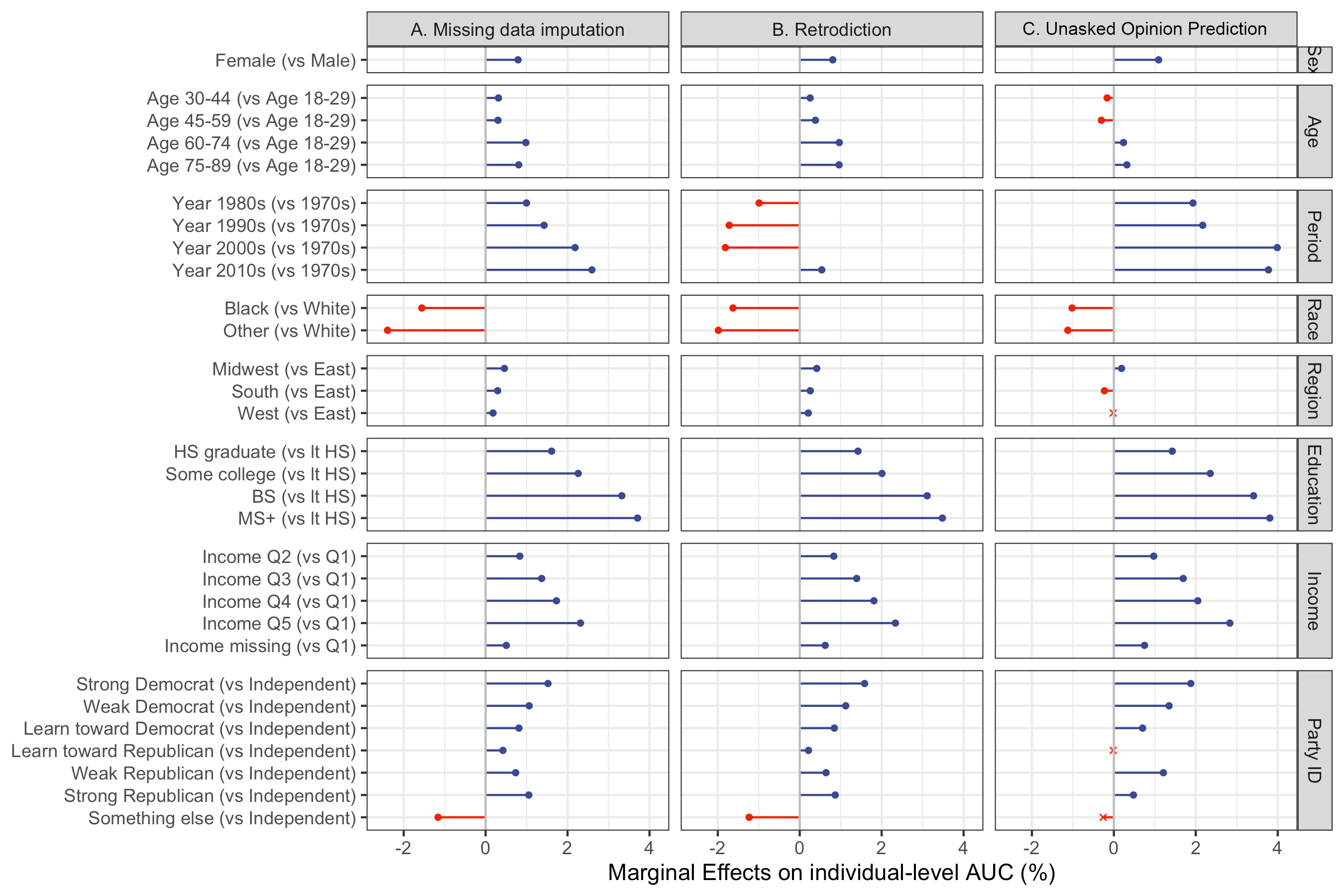
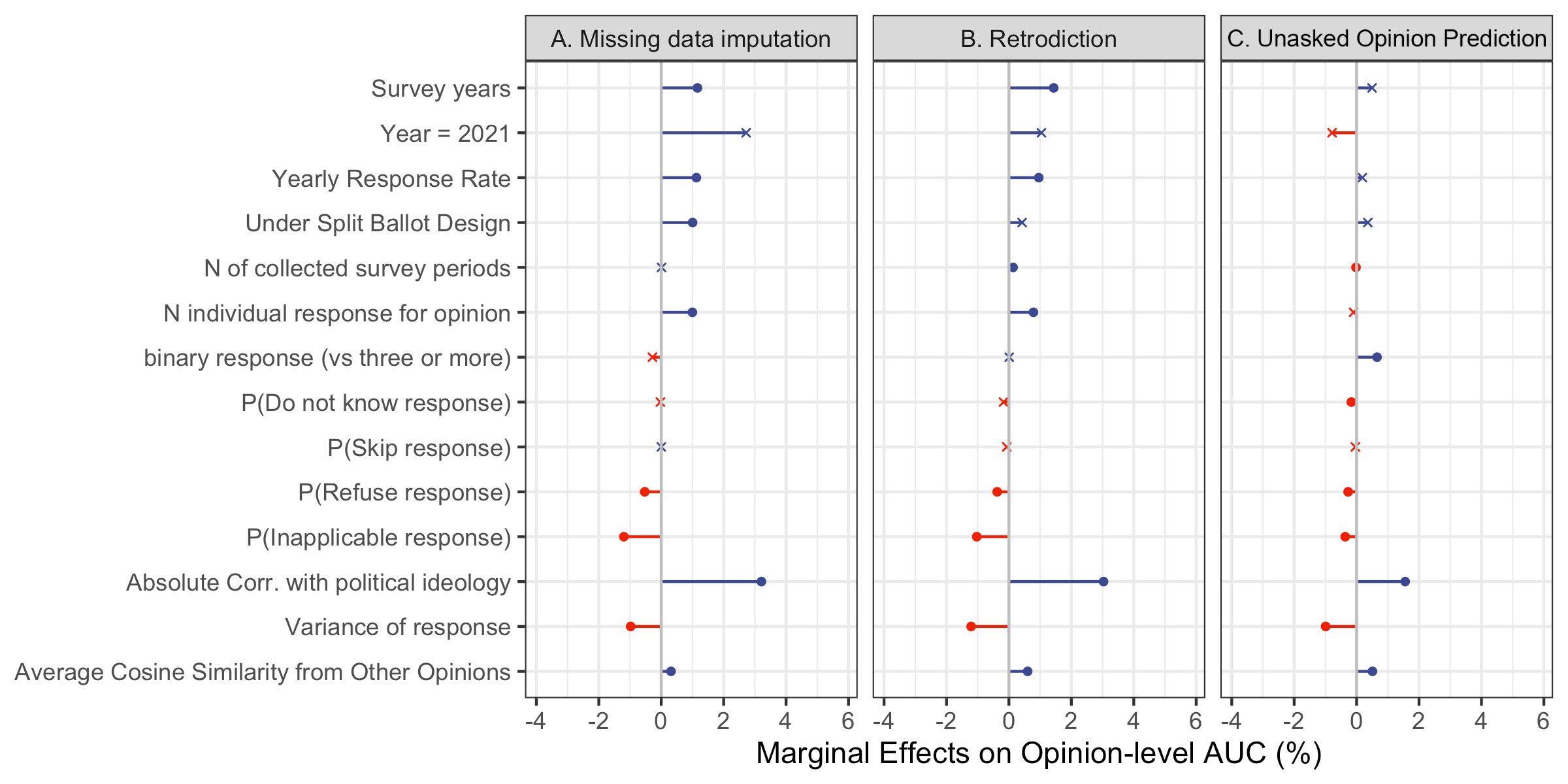
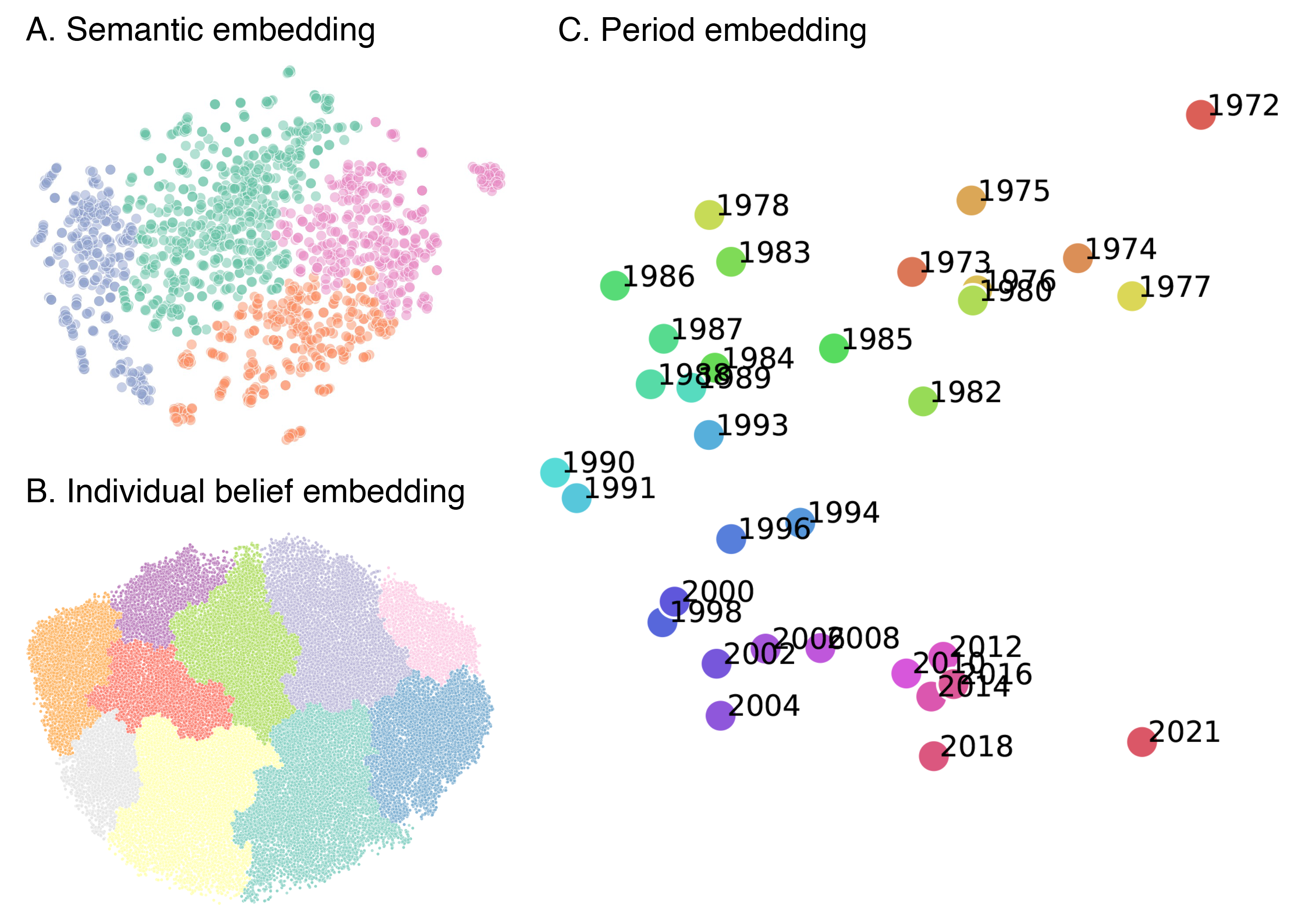
Abstract: LLMs that produce human-like responses have begun to revolutionize research practices in the social sciences. We develop a novel methodological framework that fine-tunes LLMs with repeated cross-sectional surveys to incorporate the meaning of survey questions, individual beliefs, and temporal contexts for opinion prediction. We introduce two new emerging applications of the AI-augmented survey: retrodiction (i.e., predict year-level missing responses) and unasked opinion prediction (i.e., predict entirely missing responses). Among 3,110 binarized opinions from 68,846 Americans in the General Social Survey from 1972 to 2021, our models based on Alpaca-7b excel in retrodiction (AUC = 0.86 for personal opinion prediction, $\rho$ = 0.98 for public opinion prediction). These remarkable prediction capabilities allow us to fill in missing trends with high confidence and pinpoint when public attitudes changed, such as the rising support for same-sex marriage. On the other hand, our fine-tuned Alpaca-7b models show modest success in unasked opinion prediction (AUC = 0.73, $\rho$ = 0.67). We discuss practical constraints and ethical concerns regarding individual autonomy and privacy when using LLMs for opinion prediction. Our study demonstrates that LLMs and surveys can mutually enhance each other's capabilities: LLMs can broaden survey potential, while surveys can improve the alignment of LLMs.
- “Persistent Anti-Muslim Bias in Large Language Models.” In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 298–306. Association for Computing Machinery.
- “Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. arXiv:2208.10264 [cs.CL].”
- “Can We Trust the Evaluation on ChatGPT? arXiv:2303.12767 [cs.CL].”
- “The Strength of Issues: Using Multiple Measures to Gauge Preference Stability, Ideological Constraint, and Issue Voting.” The American Political Science Review 102:215–232.
- “Out of One, Many: Using Language Models to Simulate Human Samples.” Political Analysis https://doi.org/10.1017/pan.2023.2.
- Bail, Christopher A. 2023. “Can Generative AI Improve Social Science? SocArXiv.” https://doi.org/10.31235/osf.io/rwtzs.
- Baldassarri, Delia and Andrew Gelman. 2008. “Partisans without Constraint: Political Polarization and Trends in American Public Opinion.” American Journal of Sociology 114:408–446.
- Baldassarri, Delia and Amir Goldberg. 2014. “Neither Ideologues nor Agnostics: Alternative Voters’ Belief System in an Age of Partisan Politics.” American Journal of Sociology 120:45–95.
- Baldassarri, Delia and Barum Park. 2020. “Was There a Culture War? Partisan Polarization and Secular Trends in US Public Opinion.” The Journal of Politics 82:809–827.
- Baunach, Dawn Michelle. 2012. “Changing Same-Sex Marriage Attitudes in America from 1988 Through 2010.” Public Opinion Quarterly 76:364–378.
- Beauchamp, Nicholas. 2017. “Predicting and Interpolating State-Level Polls Using Twitter Textual Data.” American Journal of Political Science 61:490–503.
- Behr, Roy L. and Shanto Iyengar. 1985. “Television News, Real-World Cues, and Changes in the Public Agenda.” Public Opinion Quarterly 49:38.
- Berinsky, Adam J. 2017. “Measuring Public Opinion with Surveys.” Annual Review of Political Science 20:309–329.
- “Predicting Poverty and Wealth from Mobile Phone Metadata.” Science 350:1073–1076.
- Boutyline, Andrei and Stephen Vaisey. 2017. “Belief Network Analysis: A Relational Approach to Understanding the Structure of Attitudes.” American journal of sociology 122:1371–1447.
- “Using gpt for market research.” Available at SSRN 4395751 .
- Brayne, Sarah. 2020. Predict and Surveil: Data, Discretion, and the Future of Policing. Oxford University Press.
- Brooks, Clem and Jeff Manza. 2006. “Social Policy Responsiveness in Developed Democracies.” American Sociological Review 71:474–494.
- “Language Models Are Few-Shot Learners.” Advances in neural information processing systems 33:1877–1901.
- Burstein, Paul. 2003. “The Impact of Public Opinion on Public Policy: A Review and an Agenda.” Political Research Quarterly 56:29–40.
- “Promises and Pitfalls of Using Digital Traces for Demographic Research.” Demography 55:1979–1999.
- “Language Models Trained on Media Diets Can Predict Public Opinion. arXiv:2303.16779 [cs.CL].”
- Converse, P. 1964. “The Nature of Belief Systems in Mass Publics.” In Ideology and Discontent, edited by Apter, D. E., pp. 206–261. The Free Press.
- Couper, Mick P. 2017. “New Developments in Survey Data Collection.” Annual Review of Sociology 43:121–145.
- ‘‘General Social Surveys, 1972-2021 Cross-section [machine-readable data file, 68,846 cases]. Principal Investigator, Michael Davern; Co-Principal Investigators, Rene Bautista, Jeremy Freese, Stephen L. Morgan, and Tom W. Smith; Sponsored by National Science Foundation. – NORC ed. – Chicago: NORC, 2021: NORC at the University of Chicago [producer and distributor]. Data accessed from the GSS Data Explorer website at gssdataexplorer.norc.org.”
- “Why Do Liberals Drink Lattes?” American Journal of Sociology 120:1473–1511.
- “Can AI Language Models Replace Human Participants?” Trends in Cognitive Sciences https://doi.org/10.1016/j.tics.2023.04.008.
- “Digital Inequality: From Unequal Access to Differentiated Use.” In Social Inequality, edited by Kathryn M. Neckerman, pp. 355–400. Russell Sage Foundation.
- Downs, Anthony. 1972. “Up and down with Ecology: The Issue-Attention Cycle.” The public 28:38–50.
- “GPTs Are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models. arXiv:2303.10130 [econ.GN].”
- Ferraro, Kenneth F. and Melissa M. Farmer. 1999. “Utility of Health Data from Social Surveys: Is There a Gold Standard for Measuring Morbidity?” American Sociological Review 64:303–315.
- “AI4People—An Ethical Framework for a Good AI Society: Opportunities, Risks, Principles, and Recommendations.” Minds and Machines 28:689–707.
- Goldberg, Amir. 2011. “Mapping Shared Understandings Using Relational Class Analysis: The Case of the Cultural Omnivore Reexamined.” American Journal of Sociology 116:1397–1436.
- “Yes but.. Can ChatGPT Identify Entities in Historical Documents? arXiv:2303.17322 [cs.DL].”
- “Jury Learning: Integrating Dissenting Voices into Machine Learning Models.” In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp. 1–19. Association for Computing Machinery.
- Text as Data: A New Framework for Machine Learning and the Social Sciences. Princeton University Press.
- “AI and the transformation of social science research.” Science 380:1108–1109.
- “Evaluating Large Language Models in Generating Synthetic HCI Research Data: A Case Study.” In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pp. 1–19. Association for Computing Machinery.
- Hastie, Trevor J. 1992. “Generalized Additive Models.” In Statistical Models in S. Routledge.
- Hilgartner, Stephen and Charles L Bosk. 1988. “The Rise and Fall of Social Problems: A Public Arenas Model.” American journal of Sociology 94:53–78.
- Holm, Elizabeth A. 2019. “In Defense of the Black Box.” Science 364:26–27.
- “Amelia II: A Program for Missing Data.” Journal of Statistical Software 45:1–47.
- Horton, John J. 2023. “Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus? arXiv:2301.07543 [econ.GN].”
- Igo, Sarah E. 2008. The Averaged American: Surveys, Citizens, and the Making of a Mass Public. Harvard University Press.
- Jefferson, Hakeem. 2020. “The Curious Case of Black Conservatives: Construct Validity and the 7-Point Liberal-Conservative Scale.” Available at SSRN: https://ssrn.com/abstract=3602209 or http://dx.doi.org/10.2139/ssrn.3602209.
- “CommunityLM: Probing Partisan Worldviews from Language Models.” In Proceedings of the 29th International Conference on Computational Linguistics, pp. 6818–6826. International Committee on Computational Linguistics.
- Joo, Won-Tak and Jason Fletcher. 2020. “Out of Sync, out of Society: Political Beliefs and Social Networks.” Network Science 8:445–468.
- “Highly Accurate Protein Structure Prediction with AlphaFold.” Nature 596:583–589.
- Jurafsky, Daniel and James Martin. 2023. Speech and Language Processing, 3rd Edition Draft.
- Kiley, Kevin and Stephen Vaisey. 2020. “Measuring Stability and Change in Personal Culture Using Panel Data.” American Sociological Review 85:477–506.
- ‘‘Personalisation within Bounds: A Risk Taxonomy and Policy Framework for the Alignment of Large Language Models with Personalised Feedback. arXiv:2303.05453 [cs.CL].”
- “Matrix Factorization Techniques for Recommender Systems.” Computer 42:30–37. Conference Name: Computer.
- “The Geometry of Culture: Analyzing the Meanings of Class through Word Embeddings.” American Sociological Review 84:905–949.
- Latour, Bruno. 2007. Reassembling the Social: An Introduction to Actor-Network-Theory. OUP Oxford.
- Lersch, Philipp M. 2023. “Change in Personal Culture over the Life Course.” American Sociological Review 88:220–251.
- “Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv:1907.11692 [cs.CL].” .
- “A Pretrainer’s Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity. arXiv:2305.13169 [cs.CL].” .
- ‘‘Tracking US Social Change Over a Half-Century: The General Social Survey at Fifty.” Annual Review of Sociology 46:109–134.
- Martin, John Levi. 2010. “Life’s a Beach but You’re an Ant, and Other Unwelcome News for the Sociology of Culture.” Poetics 38:229–244.
- “Human-Level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning.” Science 378:1067–1074.
- “Aligning Multidimensional Worldviews and Discovering Ideological Differences.” Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing pp. 4832–4845.
- “Rapidly Declining Remarkability of Temperature Anomalies May Obscure Public Perception of Climate Change.” Proceedings of the National Academy of Sciences 116:4905–4910.
- “StereoSet: Measuring Stereotypical Bias in Pretrained Language Models. arXiv:2004.09456 [cs.CL].”
- “From Tweets to Polls: Linking Text Sentiment to Public Opinion Time Series.” In Proceedings of the Fourth International Conference on Weblogs and Social Media, pp. 122–129. AAAI Press.
- “Detecting Community Sensitive Norm Violations in Online Conversations.” Findings of the Association for Computational Linguistics: EMNLP 2021 pp. 3386–3397.
- “Machine Behaviour.” Nature 568:477–486.
- Reimers, Nils and Iryna Gurevych. 2019. “Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks arXiv:1908.10084 [cs.CL].”
- Rubin, Donald B. 1976. “Inference and Missing Data.” Biometrika 63:581–592.
- “Lexical Shifts, Substantive Changes, and Continuity in State of the Union Discourse, 1790–2014.” Proceedings of the National Academy of Sciences 112:10837–10844.
- “Measuring the Predictability of Life Outcomes with a Scientific Mass Collaboration.” Proceedings of the National Academy of Sciences 117:8398–8403.
- ‘‘Whose Opinions Do Language Models Reflect? arXiv:2303.17548 [cs.CL].”
- “Large Pre-Trained Language Models Contain Human-like Biases of What Is Right and Wrong to Do.” Nature Machine Intelligence 4:258–268.
- “Sparse Data Reconstruction, Missing Value and Multiple Imputation through Matrix Factorization.” Sociological Methodology 53:72–114.
- Shapiro, Robert Y. 2011. “Public Opinion and American Democracy.” Public Opinion Quarterly 75:982–1017.
- “Model evaluation for extreme risks arXiv:2305.15324 [cs.AI].”
- Stephens-Davidowitz, Seth. 2017. Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really Are. Dey Street Books.
- “Alpaca: A Strong, Replicable Instruction-Following Model.” https://github.com/tatsu-lab/stanford_alpaca.
- van Buuren, Stef and Karin Groothuis-Oudshoorn. 2011. “Mice: Multivariate Imputation by Chained Equations in R.” Journal of Statistical Software 45:1–67.
- “Attention Is All You Need arXiv:1706.03762 [cs.CL].”
- “GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model.” https://github.com/kingoflolz/mesh-transformer-jax/.
- “DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems.” In Proceedings of the Web Conference 2021, pp. 1785–1797. Association for Computing Machinery.
- Yan, Ting. 2021. “Consequences of Asking Sensitive Questions in Surveys.” Annual Review of Statistics and Its Application 8:109–127.
- Zaller, John and Stanley Feldman. 1992. “A Simple Theory of the Survey Response: Answering Questions versus Revealing Preferences.” American Journal of Political Science 36:579–616.
- “Can Large Language Models Transform Computational Social Science? arXiv:2305.03514 [cs.CL].”
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.