The emergence of clusters in self-attention dynamics
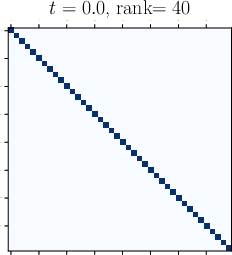
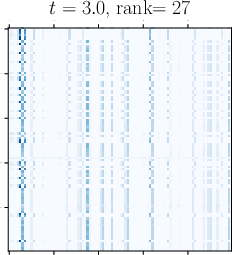
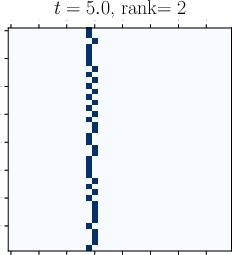
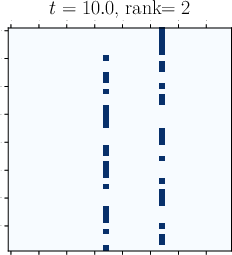
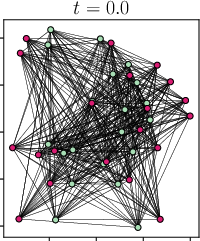
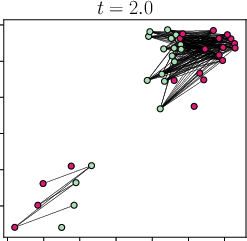
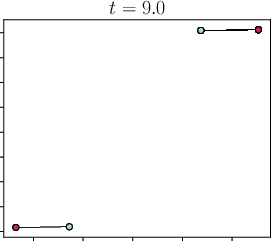
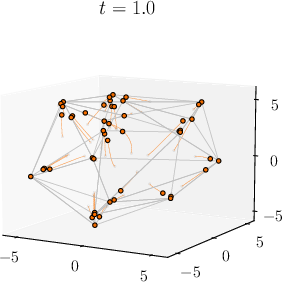
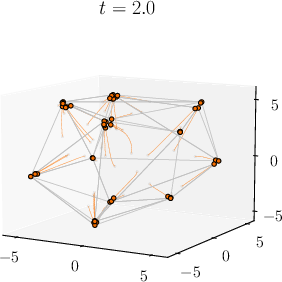
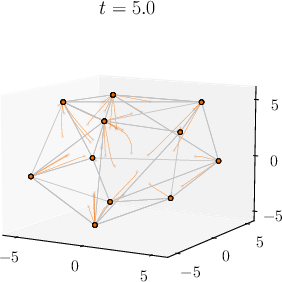
Abstract: Viewing Transformers as interacting particle systems, we describe the geometry of learned representations when the weights are not time dependent. We show that particles, representing tokens, tend to cluster toward particular limiting objects as time tends to infinity. Cluster locations are determined by the initial tokens, confirming context-awareness of representations learned by Transformers. Using techniques from dynamical systems and partial differential equations, we show that the type of limiting object that emerges depends on the spectrum of the value matrix. Additionally, in the one-dimensional case we prove that the self-attention matrix converges to a low-rank Boolean matrix. The combination of these results mathematically confirms the empirical observation made by Vaswani et al. [VSP'17] that leaders appear in a sequence of tokens when processed by Transformers.
- The Kuramoto model: A simple paradigm for synchronization phenomena. Reviews of modern physics, 77(1):137, 2005.
- K-plane clustering. Journal of Global optimization, 16:23–32, 2000.
- Yizong Cheng. Mean shift, mode seeking, and clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 17(8):790–799, 1995.
- Emergence of bi-cluster flocking for the Cucker–Smale model. Mathematical Models and Methods in Applied Sciences, 26(06):1191–1218, 2016.
- Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31, 2018.
- Emergent behavior in flocks. IEEE Transactions on Automatic Control, 52(5):852–862, 2007.
- Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In International Conference on Machine Learning, pages 2793–2803. PMLR, 2021.
- Roland L’vovich Dobrushin. Vlasov equations. Funktsional’nyi Analiz i ego Prilozheniya, 13(2):48–58, 1979.
- François Golse. Mean field kinetic equations. Course of Polytechnique, 2013.
- Matrix analysis. Cambridge University Press, 2012.
- Opinion dynamics and bounded confidence: models, analysis and simulation. Journal of Artifical Societies and Social Simulation (JASSS), 5(3), 2002.
- Complete cluster predictability of the Cucker–Smale flocking model on the real line. Archive for Rational Mechanics and Analysis, 231:319–365, 2019.
- Stable architectures for deep neural networks. Inverse problems, 34(1), 2017.
- LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Identity mappings in deep residual networks. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pages 630–645. Springer, 2016.
- Clustering and asymptotic behavior in opinion formation. Journal of Differential Equations, 257(11):4165–4187, 2014.
- Ulrich Krause. A discrete nonlinear and non-autonomous model of consensus. In Communications in Difference Equations: Proceedings of the Fourth International Conference on Difference Equations, page 227. CRC Press, 2000.
- Yoshiki Kuramoto. Self-entrainment of a population of coupled non-linear oscillators. In International Symposium on Mathematical Problems in Theoretical Physics: January 23–29, 1975, Kyoto University, Kyoto/Japan, pages 420–422. Springer, 1975.
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In International Conference on Learning Representations, 2020.
- Understanding and improving transformer from a multi-particle dynamic system point of view. In International Conference on Learning Representations, 2020.
- A survey of transformers. AI Open, 3:111–132, 2022.
- Heterophilious dynamics enhances consensus. SIAM Review, 56(4):577–621, 2014.
- Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020.
- Transport equation with nonlocal velocity in Wasserstein spaces: convergence of numerical schemes. Acta Applicandae Mathematicae, 124:73–105, 2013.
- Control to flocking of the kinetic Cucker–Smale model. SIAM Journal on Mathematical Analysis, 47(6):4685–4719, 2015.
- Extremal laws for the real Ginibre ensemble. The Annals of Applied Probability, 24(4):1621 – 1651, 2014.
- Sinkformers: Transformers with doubly stochastic attention. In International Conference on Artificial Intelligence and Statistics, pages 3515–3530. PMLR, 2022.
- Novel type of phase transition in a system of self-driven particles. Physical Review Letters, 75(6):1226, 1995.
- René Vidal. Subspace clustering. IEEE Signal Processing Magazine, 28(2):52–68, 2011.
- Fast transformers with clustered attention. Advances in Neural Information Processing Systems, 33:21665–21674, 2020.
- Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- E Weinan. A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics, 1(5):1–11, 2017.
- A mean-field optimal control formulation of deep learning. Research in Mathematical Sciences, 6(1):10, 2019.
- Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Are transformers universal approximators of sequence-to-sequence functions? In International Conference on Learning Representations, 2020.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.