- The paper introduces a novel meta-learning framework that constructs differentiable surrogate losses to optimize non-differentiable evaluation metrics.
- It demonstrates robust gains, achieving up to 39% improvement in edit distance and 4.25% relative F1 score improvement in text recognition and detection tasks.
- A quality-aware filtering strategy and differentiable ranking relaxations enhance optimization stability and scalability in complex neural network models.
Surrogates and Training Strategies for Neural Networks on Non-Differentiable Objectives
Introduction and Motivation
The dissertation "Neural Network Training and Non-Differentiable Objective Functions" (2305.02024) addresses the critical problem that arises when the evaluation metric of interest in computer vision, information retrieval, or similar tasks is non-differentiable and therefore not suitable for direct minimization using gradient-based learning. The standard approach in deep learning—training with back-propagation—necessitates gradients of the objective with respect to the model predictions. In practice, this has forced researchers to employ proxy losses (e.g., per-character cross-entropy, Lp-norms) that are differentiable but often suboptimally aligned with the metrics on which practical performance is actually quantified, such as edit distance, intersection-over-union (IoU), or ranking-based scores like recall@k.
To bridge this gap, the thesis develops general methodologies for constructing differentiable surrogate losses that more faithfully approximate the desired non-differentiable performance metrics, thus allowing end-to-end optimization of neural networks even when direct differentiation is not possible.
Learning Differentiable Surrogates for Decomposable Metrics
A principal contribution is a framework for learning differentiable surrogates for decomposable evaluation metrics. Here, the thesis introduces a meta-learning loop where a surrogate network is trained, often using a deep embedding, to approximate the target metric between pairs of predictions and ground-truth instances:
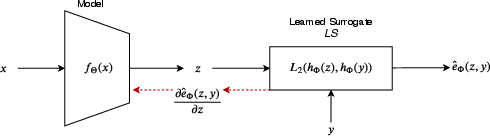
Figure 1: For the input x with the corresponding ground-truth y, the model being trained outputs z=fΘ(x). The learned surrogate provides a differentiable approximation of the evaluation metric: e^Φ(z,y)=∥hΦ(z)−hΦ(y)∥2, with hΦ parameterizing the embedding.
In this setting, training proceeds in an alternating fashion: the surrogate e^Φ is trained to minimize its error with respect to the true metric e(z,y), while the main model fΘ is trained using gradients from the surrogate loss. This setup is validated in domains such as scene text recognition (where edit distance is the relevant metric and proxy losses are typically per-character cross-entropy) and scene text detection (where IoU is used and proxies are Lp losses over box parameters).
Empirical results demonstrate substantial gains: scene text recognition models post-tuned with this learned surrogate achieve up to 39% relative improvement in total edit distance, and scene text detection models achieve 4.25% relative improvement in F1 score. This not only validates the alignment of the learned surrogate with the metric but also attests to the method’s generality and scalability.
Robust Optimization with Surrogate Quality-Aware Filtering
The thesis further recognizes that early in training or in out-of-distribution regimes, even a learned surrogate may produce noisy or unreliable metric approximations, potentially leading to training instability. To mitigate this, a filtered approach is proposed, whereby training samples are filtered—that is, excluded from back-propagation—if the surrogate's approximation error exceeds a threshold. Technically, this is implemented via a piecewise differentiable ramp or gating function:
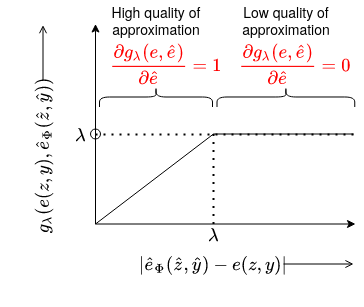
Figure 2: The filtering function enforces zero gradients for the samples that are hard for the surrogate (low quality of approximation). STR model is trained only on the samples where the quality of the approximation from the edit distance surrogate is high.
Such filtering ensures that model updates occur only when the surrogate is trustworthy, leading to substantially reduced label error and cleaner optimization. For instance, on scene text recognition benchmarks, this methodology was shown to yield average improvements of 11.2% in edit distance and 9.5% error reduction in accuracy over baselines without filtering.
Surrogates for Non-Decomposable Metrics: Differentiable Ranking
For non-decomposable, ranking-based metrics such as recall@k—prevalent in instance-level retrieval and metric learning—the work transitions from learned surrogates to hand-crafted, mathematically constructed differentiable approximations. Here, the core innovation is a soft relaxation of the sorting and counting inherent in recall@k, using smooth sigmoid-based approximations of Heaviside and ranking functions. This enables back-propagatable loss functions that correlate tightly with the standard evaluation:

Figure 3: A comparison between recall@k and rs@k, the proposed differentiable recall@k surrogate. Example shows the sensitivity of the surrogate to similarity score change, preserving alignment with the underlying ranking objective.
The approach is further augmented by a computationally efficient similarity mixup (SiMix) strategy—rather than mixing raw embeddings (which is expensive), pairwise similarities are mixed, virtually expanding the batch and increasing learning signal diversity with minimal computational overhead. These synergies allow, for the first time, training with true large-scale batch sizes (up to 16k images on a single GPU).
Results on standard fine-grained recognition and metric learning benchmarks, including iNaturalist and Stanford Online Products, demonstrate consistent state-of-the-art performance, surpassing loss functions based on cross-entropy and hand-crafted triplet or margin proxies. Integrating retrieval-based inference also allows kNN classifiers to outperform direct classification pipelines—notably in the large-scale, fine-grained regime.
Unified Contrastive Classification with Probabilistic Interpretation
The final major contribution is to incorporate the advantages of contrastive representation learning—robustness and generalizability—within a unified classification framework that maintains a clear probabilistic interpretation (i.e., calibrated posteriors). The proposed Extended Supervised Contrastive (ESupCon) loss establishes an explicit connection between supervised contrastive losses and softmax CE, introducing class prototypes as both embedding anchors and classifier weights, and combining them with contrastive and tightness terms:
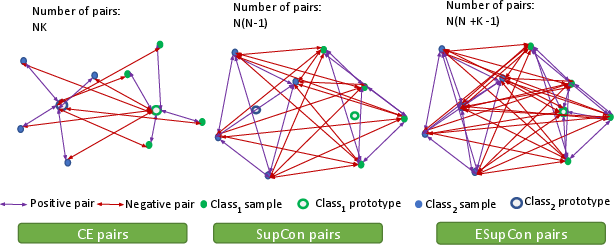
Figure 4: Illustration of the possible number of pairs that each loss accesses during training in the learned embedding space. ESupCon leverages both class prototypes and instance-level structure for robustness and probabilistic interpretability.
Empirical evaluation shows that ESupCon not only closes the gap to cross-entropy in typical regimes but demonstrates vastly superior robustness in low-data, class-imbalanced, and label-noise scenarios—settings where classical cross-entropy classifiers are brittle or prone to overfitting. Importantly, post-hoc calibration (via temperature scaling) demonstrates well-behaved predictive probability estimates.
Practical and Theoretical Implications
Practically, these contributions significantly reduce the engineering burden required to develop new tasks or adapt models to new domains: as long as the evaluation metric is known, the model can be trained on a suitable surrogate without manual crafting of task-specific loss functions. Theoretically, the work opens up the possibility of extending surrogate learning to more complex, structured, or black-box metrics (e.g., BLEU, RANSAC), potentially further reducing the gap between what deep networks optimize and what practitioners actually care about.
Future directions include compositional surrogates for more complex, integrated multi-task metrics, exploration of more expressive surrogate function classes, and greater automation in surrogate construction for arbitrary evaluation criteria.
Conclusion
This thesis articulates rigorous, scalable approaches for aligning deep neural network training to non-differentiable objectives, spanning both decomposable and ranking-based metrics. By combining meta-learned surrogates, robustness-enhancing filtering, differentiable relaxations, mixup, and unified probabilistic-contrastive classification, it delivers strong empirical gains across text, detection, and retrieval domains. The theoretical insights and practical recipes established here will underpin coming advances in making deep learning reliably serve end-user evaluative preferences, even when those are not expressible in closed-form differentiable objectives.