- The paper introduces PMC-LLaMA, demonstrating a novel approach of integrating 4.8M biomedical papers and 30K medical textbooks for domain-specific performance.
- The methodology combines data-centric knowledge injection with medical-specific instruction tuning to improve accuracy in medical QA, reasoning, and dialogue tasks.
- Experimental evaluations reveal that PMC-LLaMA outperforms conventional models in both zero-shot and fine-tuned scenarios on benchmarks like PubMedQA, MedMCQA, and USMLE.
PMC-LLaMA: Towards Building Open-source LLMs for Medicine
The paper introduces PMC-LLaMA, an open-source LLM specifically designed for medical applications, addressing limitations in existing LLMs when dealing with domain-specific tasks, particularly in medicine. The model leverages two key processes—data-centric knowledge injection and medical-specific instruction tuning—to enhance the applicability and precision of LLMs within the medical domain.
Introduction to PMC-LLaMA
PMC-LLaMA is developed by adapting a general-purpose LLM for the medical domain. The adaptation process involves:
- Data-centric Knowledge Injection: Utilizing a large corpus of de-duplicated and pre-processed medical data, including 4.8 million biomedical papers and 30,000 medical textbooks, to imbue the model with domain-specific knowledge.
- Medical-specific Instruction Tuning: This process aligns the model with the requirements of domain-specific tasks through comprehensive fine-tuning using a large-scale medical dataset encompassing tasks such as medical QA, reasoning rationale, and conversational dialogues.
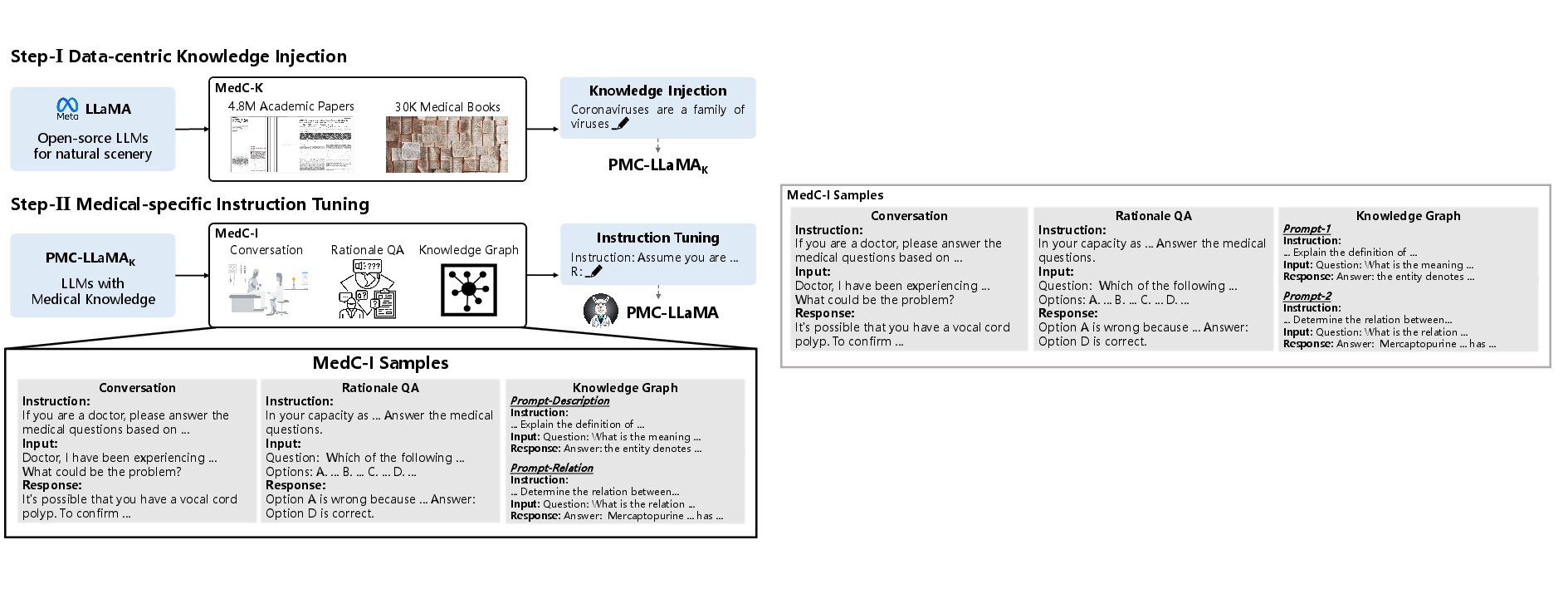
Figure 1: The training pipeline of PMC-LLaMA, demonstrating knowledge injection and instruction tuning stages.
The practical implementation of PMC-LLaMA involves careful injection of domain-specific knowledge, ensuring the model comprehends complex medical terminology and reasoning processes.
Knowledge Injection
The initial stage of training PMC-LLaMA includes a data-centric focus to expose the model to comprehensive medical information. This foundational training is driven by two primary data sources:
The knowledge injection aids in creating a robust embedding space for handling complex medical terminologies, essential for the model's effectiveness in precise medical scenarios.
Instruction Tuning
Following knowledge injection, PMC-LLaMA undergoes instruction tuning to refine its ability to process medical instructions accurately. This involves:
- Medical Conversation Data: Using patient-physician dialogue datasets to simulate realistic interactions and responses.
- Reasoning QA Data: Enhancing reasoning capabilities by integrating datasets that require detailed rationale beyond simple question answering.
- Knowledge Graph Data: Using structured data to improve the model's familiarity and handling of explicit medical term definitions and relationships.
These processes allow PMC-LLaMA to operate proficiently in zero-shot scenarios, offering substantial improvements over existing models like ChatGPT in terms of accuracy and domain adaptation (Figure 3).



Figure 3: Patient-Physician Conversation, showcasing PMC-LLaMA’s proficiency in practical dialogue settings.
Experimental Evaluation
PMC-LLaMA's performance evaluation spans multiple medical QA benchmarks such as PubMedQA, MedMCQA, and USMLE, using accuracy as the primary metric. Comparisons with existing models demonstrate PMC-LLaMA's superior performance, attributed to the detailed domain-specific tuning and extensive dataset integration.
- Task-specific Fine-tuning Evaluation: Models without instruction tuning are further refined on medical QA datasets, showcasing marked improvements in specialized scenarios.
- Zero-shot Instruction Evaluation: Demonstrates PMC-LLaMA's capability to generate accurate responses without additional fine-tuning, emphasizing its robust foundational knowledge in medicine.
Conclusion
PMC-LLaMA successfully addresses the limitations of generic LLMs in medical domains by integrating specific domain knowledge and instruction tuning, making it a versatile tool for handling intricate medical tasks. Its development sets a precedent for future LLM adaptations, particularly in critical fields requiring high precision and specialized knowledge. The release of PMC-LLaMA models, codes, and datasets (available at https://github.com/chaoyi-wu/PMC-LLaMA) offers an invaluable resource for further advancements in medical AI applications.
Overall, PMC-LLaMA exemplifies a significant step towards enhancing LLM capabilities within medicine, showcasing practical improvements that surpass conventional models in both scope and accuracy across medical-related tasks.
