- The paper presents a novel shared encoder model that unifies text, image, and multimodal tasks, reducing complexity and resource usage.
- It employs a stage-wise training methodology, starting with image pretraining and advancing to text and combined modalities, improving overall learning efficiency.
- Experimental results demonstrate competitive performance, including a 35% faster inference in Visual Question Answering compared to models like FLAVA.
MoMo: A Shared Encoder Model for Multimodal Representations
MoMo introduces a novel approach in multimodal representation learning by employing a shared encoder model that proficiently handles text, image, and image-text tasks within a unified architecture. As multimodal models strive to minimize resource consumption and maximize efficiency, MoMo leverages a streamlined yet robust framework to achieve competitive performance across diverse benchmarks, demonstrating substantial gains in efficiency.
Model Architecture and Training Strategy
MoMo's architecture revolves around a singular transformer encoder, capable of processing unimodal inputs (either text or image) and cross-modal inputs (text-image combined). This shared encoder framework contrasts with traditional architectures that typically separate encoders by modality. The advantage of MoMo's design lies in its efficiency: it reduces the need for multiple specialized models while simultaneously decreasing runtime and memory demands.
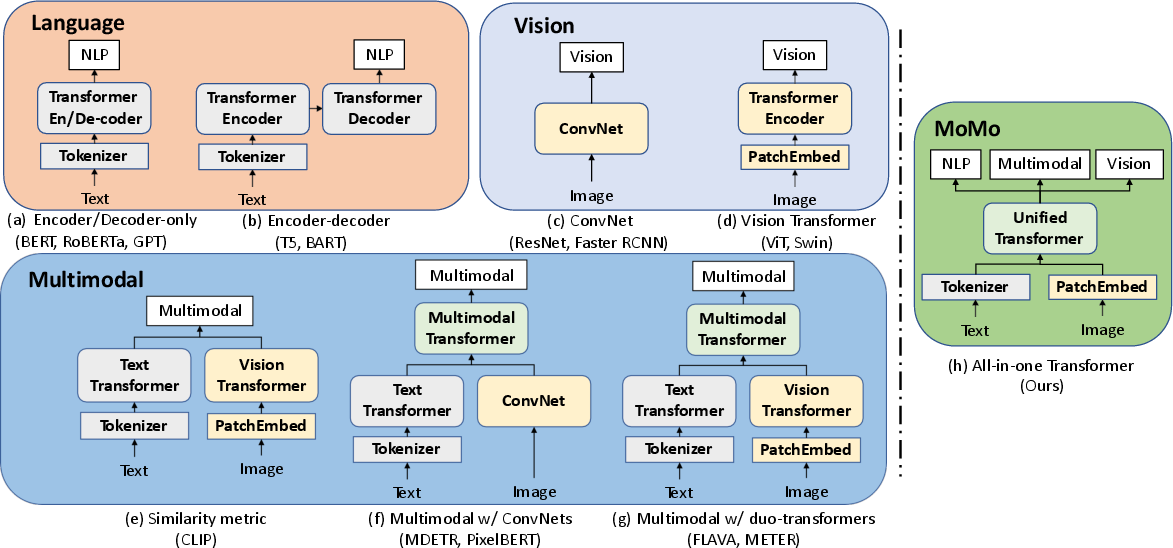
Figure 1: Illustrations of model architectures processing various modalities, highlighting MoMo's unified transformer approach.
Stage-wise Training Methodology
The training process for MoMo is meticulously structured into three distinct stages, facilitating efficient learning across modalities. Initially, MoMo is pretrained on image datasets, employing a masked image modeling (MIM) objective to enhance understanding of visual structures. Subsequent stages involve concurrent text and image dataset training, followed by a multimodal focus combining text and image-text datasets. This multi-stage training method assists in mitigating information loss that often occurs when modalities are independently processed, enabling the model to accumulate gradients from diverse datasets efficiently.
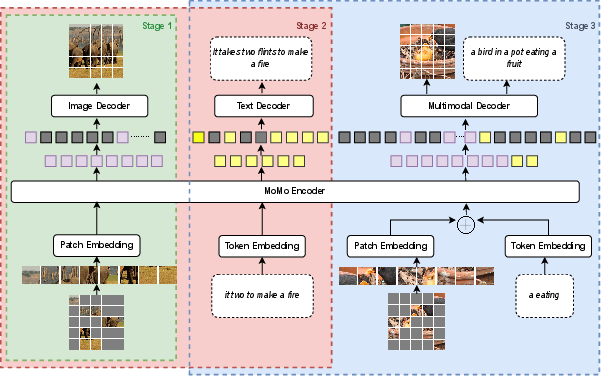
Figure 2: MoMo's sequential training stages, illustrating progressive unified learning across modalities.
Experimental Results and Discussion
MoMo is evaluated across a spectrum of unimodal (language, image) and multimodal tasks, demonstrating its competitive edge. In direct comparisons with models such as FLAVA and CLIP, MoMo showcases notable achievements with reduced parameter counts and dataset sizes. Specifically, MoMo achieves Macros Average accuracy improvements in multimodal tasks, exemplifying its effectiveness and efficiency in handling the complexity of cross-modality interactions.
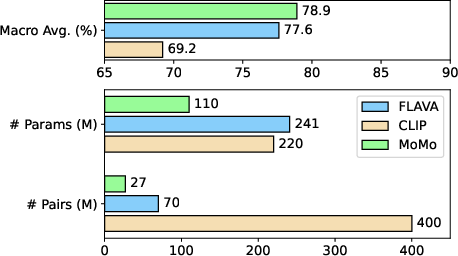
Figure 3: Comparison with FLAVA, indicating MoMo's superior macro accuracy with reduced parameters and training data.
Model Efficiency
The model's shared encoder architecture lowers computational costs considerably, presenting up to a 35% speedup in inference tasks, such as Visual Question Answering. MoMo's shared parameters and efficient training pipeline reduce operational overhead, making it a pragmatic choice for deployment scenarios that require versatility across text, image, and multimodal tasks.
Ablation Studies
A thorough ablation study reveals critical insights into MoMo's architecture and training decisions. Separating training stages for unimodal and multimodal tasks validates the efficacy of MoMo's staged approach. Maintaining separate decoders for each training stage optimizes representation learning for distinct modalities, corroborating the impact of design choices on performance metrics.
Conclusion
MoMo represents a significant step forward in multimodal representation learning, offering a unified model that balances efficiency with competitive performance. Its shared encoder model reduces complexity and enhances deployment flexibility, fostering advancements in multimodal AI applications. Future research prospects include scaling model architectures and datasets to further harness MoMo's potential in expansive multimodal tasks. As AI technologies gravitate towards integrating varied data types, MoMo's contributions underscore the critical importance of adaptable, resource-efficient models in advancing the field.

