- The paper proposes GPT4Rec, a framework that reframes recommendations as a generative query and retrieval task using GPT-2 and BM25.
- It demonstrates significant improvements in recommendation recall (up to 75.7%), diversity, and coverage across multiple datasets by generating diverse queries.
- The framework enhances interpretability by providing multi-query beam search outputs that reveal nuanced user interests and item semantics.
GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation
Introduction
The paper presents "GPT4Rec," a generative framework designed to enhance recommender systems using advanced NLP techniques. In traditional NLP-based recommendation frameworks, limitations often arise due to their treatment of items as mere IDs, and their reliance on discriminative models restricts the utilization of content data and the interpretability of user interests. GPT4Rec addresses these limitations by framing recommendations as a process involving query generation and retrieval, inspired by search engines. The system accomplishes this through the use of a generative LLM (GPT-2) and a BM25 search engine, enabling improved utilization of item semantic information and offering interpretable representations of user interests via multi-query beam search.
Methodology
Framework Architecture
GPT4Rec utilizes a two-stage process to generate personalized recommendations. The first stage involves constructing search queries from a user's historical item titles using a generative LLM. These queries then enable the retrieval of items through a search engine, thus resembling the function of a search engine in a recommendation context. The architecture's flexibility allows it to integrate advanced LLMs and search engines.
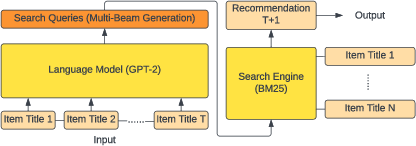
Figure 1: The architecture of the GPT4Rec framework.
Query Generation
GP4Rec generates multiple search queries to represent the diverse interests of users. The generative model leverages a fine-tuned GPT-2, utilizing item titles as prompts for query generation. The selected input formatting highlights users' past purchases and intentions for future consumption, enabling the representation of user interests with varying specificity and generality.
Item Retrieval
The items are retrieved using a BM25 search engine, which utilizes the generated queries to rank and select items. BM25's score functions measure the similarity in the language space, distinguishing relevant items based on their semantic content. A ranking-based strategy is used to ensure both the relevance and diversity of recommendations.
Experimental Evaluation
The framework's efficacy was evaluated using two public datasets, Beauty and Electronics, focusing on metrics such as Recall@K, Diversity@K, and Coverage@K. GPT4Rec was benchmarked against several baseline models, including FM-BPR, ContentRec, YouTubeDNN, and BERT4Rec.
Quantitative Results
GPT4Rec demonstrated superior performance, achieving significant improvements in Recall@K over baseline models by 75.7% in the Beauty dataset and 22.2% in the Electronics dataset. The analysis showed that increased query generation directly correlated with improved diversity and coverage of recommendations, affirming the framework's ability to cater to multifaceted user preferences.


Figure 2: Example of a test user with diverse interests in Beauty products, with target item circled in red.
Qualitative Analysis
Qualitative case studies highlighted GPT4Rec's effectiveness in generating comprehensive query sets that captured nuanced user interests. The examples illustrated how individualized interests, whether diverse or specific, were accurately represented, contributing to the framework's ability to offer interpretable user insights.


Figure 3: Example of a test user with specific interests in Electronics products, with target item circled in red.
Conclusion
GPT4Rec builds upon the capabilities of generative LLMs to enhance personalized recommendation systems. By treating recommendation as a query generation and retrieval task, this approach addresses several prominent issues in current models, such as the item cold-start problem and the challenge of user interest interpretation. The framework's adaptability to incorporate more sophisticated models suggests promising avenues for further research and potential improvements in recommendation strategy. Future work could explore integrating cutting-edge LLMs and retrieval strategies to further refine and enhance system performance.

