LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
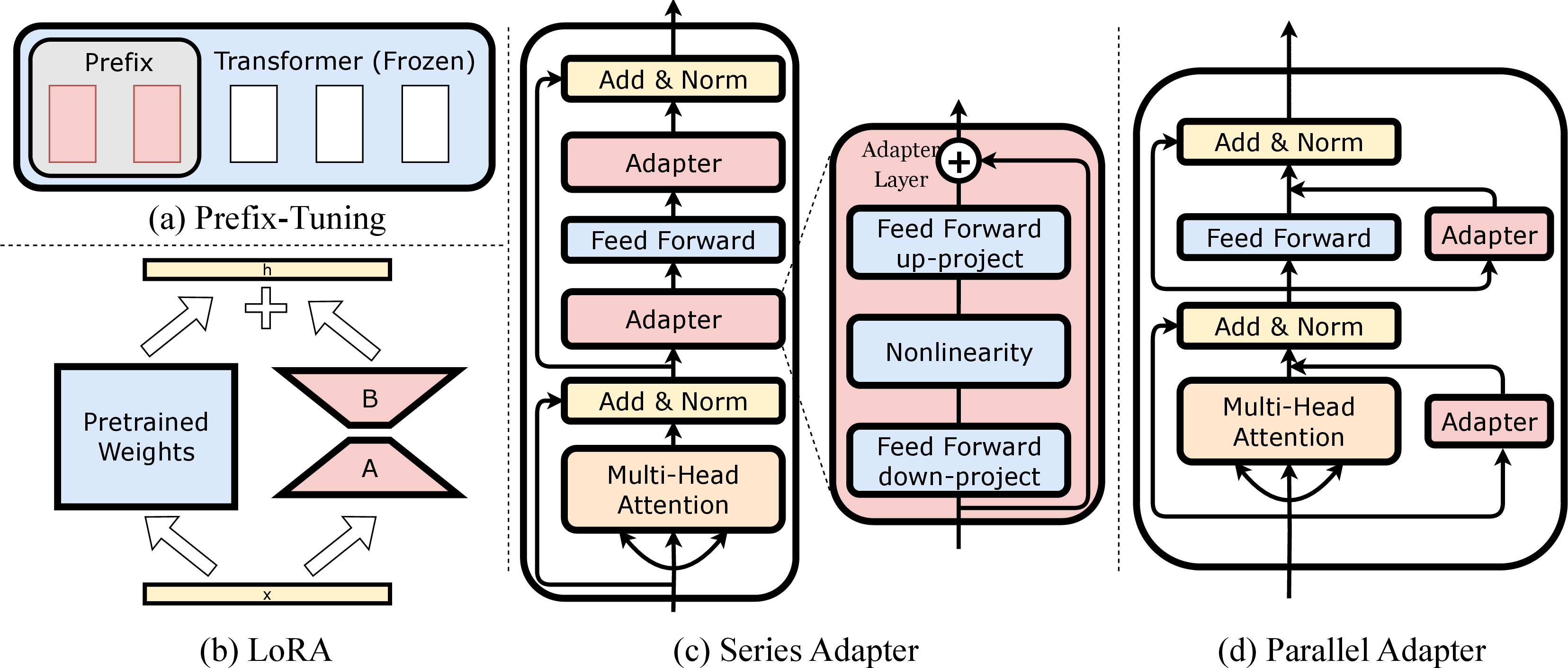
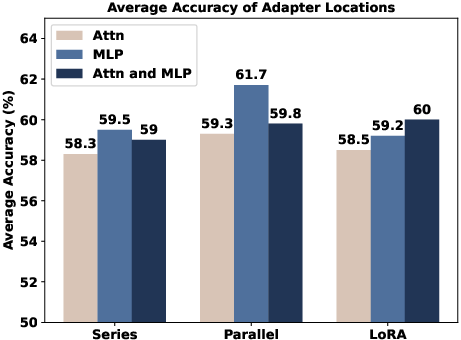
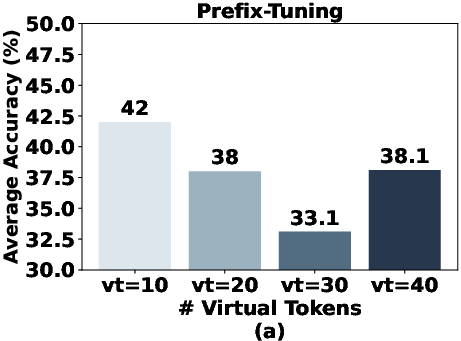
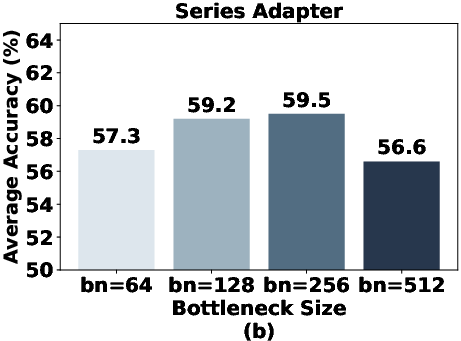
Abstract: The success of LLMs, like GPT-4 and ChatGPT, has led to the development of numerous cost-effective and accessible alternatives that are created by finetuning open-access LLMs with task-specific data (e.g., ChatDoctor) or instruction data (e.g., Alpaca). Among the various fine-tuning methods, adapter-based parameter-efficient fine-tuning (PEFT) is undoubtedly one of the most attractive topics, as it only requires fine-tuning a few external parameters instead of the entire LLMs while achieving comparable or even better performance. To enable further research on PEFT methods of LLMs, this paper presents LLM-Adapters, an easy-to-use framework that integrates various adapters into LLMs and can execute these adapter-based PEFT methods of LLMs for different tasks. The framework includes state-of-the-art open-access LLMs such as LLaMA, BLOOM, and GPT-J, as well as widely used adapters such as Series adapters, Parallel adapter, Prompt-based learning and Reparametrization-based methods. Moreover, we conduct extensive empirical studies on the impact of adapter types, placement locations, and hyper-parameters to the best design for each adapter-based methods. We evaluate the effectiveness of the adapters on fourteen datasets from two different reasoning tasks, Arithmetic Reasoning and Commonsense Reasoning. The results demonstrate that using adapter-based PEFT in smaller-scale LLMs (7B) with few extra trainable parameters yields comparable, and in some cases superior, performance to powerful LLMs (175B) in zero-shot inference on both reasoning tasks.
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Annual Meeting of the Association for Computational Linguistics.
- Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence.
- Parameter-efficient fine-tuning design spaces. arXiv preprint arXiv:2301.01821.
- BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936, Minneapolis, Minnesota. Association for Computational Linguistics.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Krona: Parameter efficient tuning with kronecker adapter. ArXiv, abs/2212.10650.
- Learn-to-share: A hardware-friendly transfer learning framework exploiting computation and parameter sharing. In Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 3469–3479. PMLR.
- Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366.
- Towards a unified view of parameter-efficient transfer learning. In International Conference on Learning Representations.
- SparseAdapter: An easy approach for improving the parameter-efficiency of adapters. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2184–2190, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Compacter: Efficient low-rank hypercomplex adapter layers. In Advances in Neural Information Processing Systems.
- Learning to solve arithmetic word problems with verb categorization. In EMNLP, pages 523–533.
- Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning.
- Lora: Low-rank adaptation of large language models. ArXiv, abs/2106.09685.
- Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916.
- Parsing algebraic word problems into equations. Transactions of the Association for Computational Linguistics, 3:585–597.
- MAWPS: A math word problem repository. In Proceedings of NAACL, pages 1152–1157.
- The power of scale for parameter-efficient prompt tuning. ArXiv, abs/2104.08691.
- Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 158–167.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft.
- Unipelt: A unified framework for parameter-efficient language model tuning. ArXiv, abs/2110.07577.
- Crosslingual generalization through multitask finetuning. arXiv preprint arXiv:2211.01786.
- OpenAI. 2022. Introducing chatgpt. https://openai.com/blog/chatgpt.
- OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- Are NLP models really able to solve simple math word problems? In Proceedings of NAACL, pages 2080–2094.
- Mad-x: An adapter-based framework for multi-task cross-lingual transfer. In Conference on Empirical Methods in Natural Language Processing.
- Is chatgpt a general-purpose natural language processing task solver? arXiv preprint arXiv:2302.06476.
- Exploring universal intrinsic task subspace via prompt tuning. arXiv e-prints, pages arXiv–2110.
- Subhro Roy and Dan Roth. 2016. Solving general arithmetic word problems. arXiv preprint arXiv:1608.01413.
- Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728.
- Hugginggpt: Solving AI tasks with chatgpt and its friends in huggingface. CoRR, abs/2303.17580.
- Lst: Ladder side-tuning for parameter and memory efficient transfer learning. ArXiv, abs/2206.06522.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Spot: Better frozen model adaptation through soft prompt transfer. arXiv preprint arXiv:2110.07904.
- Ben Wang and Aran Komatsuzaki. 2021. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax.
- Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091.
- Adamix: Mixture-of-adapter for parameter-efficient tuning of large language models. ArXiv, abs/2205.12410.
- Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge. arXiv preprint arXiv:2303.14070.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

