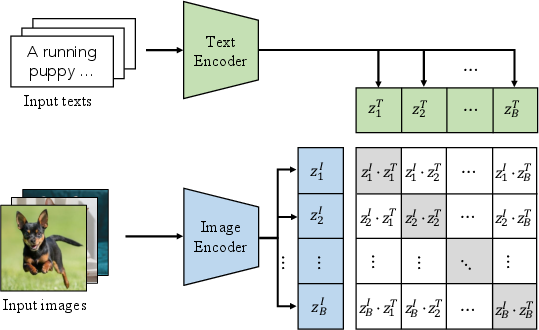
- The paper demonstrates a paradigm shift in visual recognition by using VLMs to enable zero-shot predictions with minimal task-specific fine-tuning.
- It details the use of architectures like ViT and Transformer, employing contrastive and generative pre-training to align image-text pairs.
- The survey highlights challenges in fine-grained vision-language correlations and outlines future directions for data-efficient, unified modeling.
Vision-LLMs for Vision Tasks: A Survey
The paper "Vision-LLMs for Vision Tasks: A Survey" provides a comprehensive analysis of the impact and development of Vision-LLMs (VLMs), particularly emphasizing their application to visual recognition tasks. Visual recognition is a cornerstone of computer vision applications such as autonomous driving, remote sensing, and robotics. However, traditional machine learning paradigms often require large, task-specific, labeled datasets, which can be labor-intensive to generate. This essay explores how VLMs offer an alternative through large-scale, weakly-labeled, web-sourced data and innovative training methodologies.
Development and Paradigms of Visual Recognition
Over the years, visual recognition has evolved from feature-engineering-centric approaches to deep learning paradigms. The most recent advancement is the Vision-LLM Pre-training and Zero-shot Prediction paradigm.
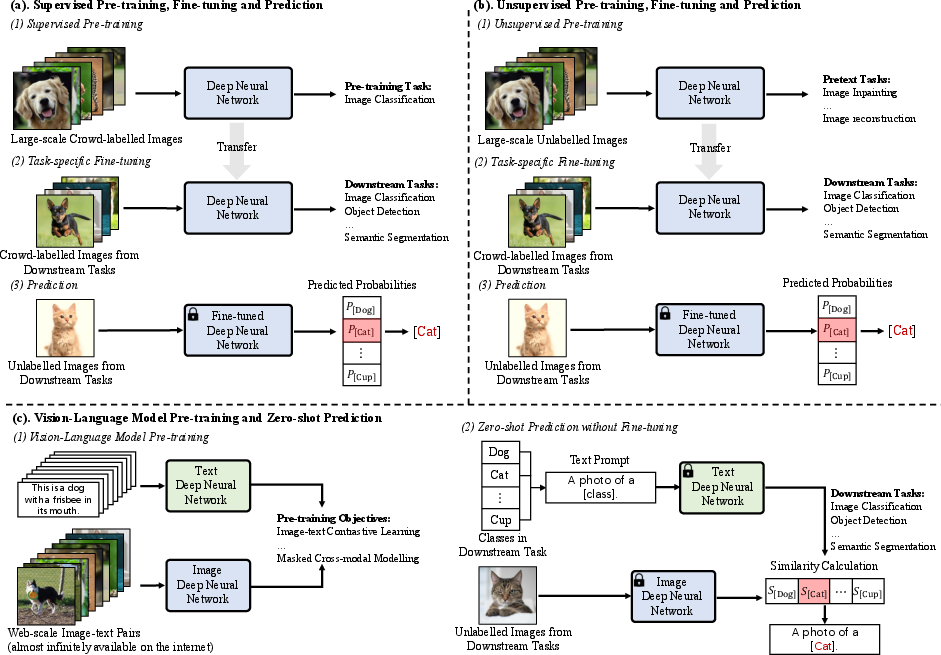
Figure 1: Three DNN training paradigms in visual recognition. Compared with the paradigms in (a) and (b) that requires fine-tuning for each specific task with task-specific labelled data, the new learning paradigm with VLMs in (c) enables effective usage of web data and zero-shot predictions without task-specific fine-tuning.
Compared to the conventional paradigms that require extensive fine-tuning for specific tasks using labeled data, VLMs such as CLIP facilitate zero-shot predictions and capitalize on web resources effectively.
Foundations and Architectures
VLMs leverage architectures like ViT for image encoding and Transformer for text encoding to derive meaningful embeddings from image-text pairs. A crucial part of VLM pre-training is the formulation of objectives that encourage models to capture the interplay between visual and textual modalities.
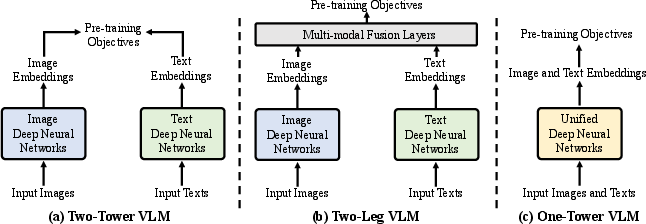
Figure 2: Illustration of typical VLM pre-training frameworks.
VLM architectures typically adopt separate pathways for image and text processing, exemplified by the two-tower framework. However, integration efforts like a unified vision-language learning framework offer improved inter-modal communication, thus enhancing feature alignment and subsequent task performance.
Pre-training Objectives
Crucial to VLMs are the diverse pre-training objectives that govern the learning phase. These include:
Challenges and Future Directions
While VLMs present a transformative approach to visual recognition, significant challenges remain, particularly in fine-grained vision-language correlation modeling and resource-efficient scaling. Future research is expected to focus on:
- Data-Efficient Models: Reducing reliance on vast datasets without sacrificing performance.
- Unified Modeling: Further integration of vision and language pathways to improve intra-modal communication and reduce computational overhead.
- Multilingual and Cultural Representation: Enhancing the diversity of training datasets to accommodate a greater variety of languages and cultural contexts.
Conclusion
Vision-LLMs open promising avenues for visual recognition research by mitigating the dependency on large labeled data specific to every task. Their foundational shift toward web-scale data and cross-modal embedding learning represents a significant leap in AI-driven vision solutions. As the research community addresses the extant challenges, VLMs stand poised to redefine many real-world computer vision applications with enhanced efficacy and efficiency.