- The paper introduces a novel BEVFusion4D framework that fuses LiDAR and camera data via LGVT and TDA for precise 3D object detection.
- It employs a LiDAR-guided view transformer to enhance camera feature mapping and a temporal deformable alignment module to correct motion blur.
- Evaluation on the nuScenes dataset shows improved mAP and NDS, demonstrating its efficacy in dynamic, real-world autonomous driving scenarios.
"BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird's-Eye-View via Cross-Modality Guidance and Temporal Aggregation" (2303.17099)
Introduction to BEVFusion4D
BEVFusion4D is designed to enhance 3D object detection by integrating LiDAR and camera data in the BEV space, crucial for autonomous driving applications. The framework includes the LiDAR-Guided View Transformer (LGVT) and Temporal Deformable Alignment (TDA), achieving state-of-the-art results on 3D detection tasks. The primary advantage is the robust fusion of spatial and temporal data across modalities, leveraging the strengths of LiDAR for accurate spatial descriptions while incorporating rich, semantic camera information.
Methodology
Bird's-Eye-View Spatial Fusion
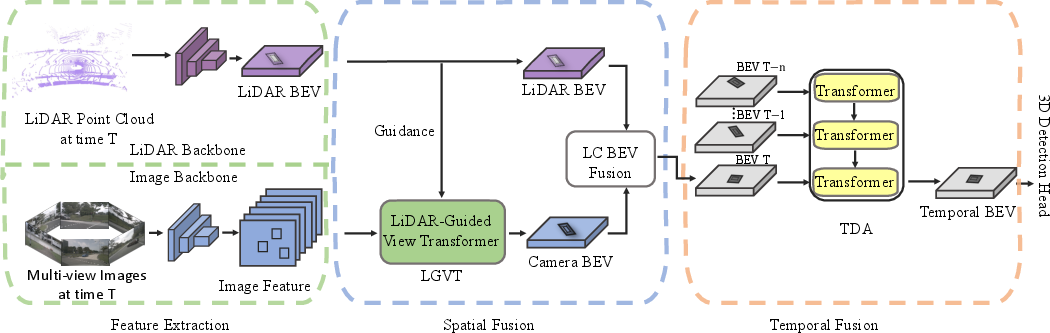
Figure 1: The overall pipeline of our spatiotemporal fusion framework consists of feature extraction, spatial fusion, and temporal fusion stages.
The spatial fusion starts with extracting LiDAR and camera features, where LiDAR offers high-accuracy spatial data, and cameras contribute dense semantic content. The LGVT is introduced to transform camera data effectively into BEV space by utilizing spatial cues from LiDAR. This approach contrasts previous methods like LSS by providing reliable depth guidance through LiDAR, overcoming challenges in semantic camera integration and thus enhancing feature fusion.
Temporal Fusion via TDA

Figure 2: Temporal BEV features fusion module, illustrating moving and stationary objects alignment.
Temporal fusion employs the TDA module to address historical BEV feature aggregation issues. It corrects motion smears and aligns moving objects efficiently without excessive computation cost. The deformable attention mechanism selectively captures salient movement features, optimizing alignment between temporal frames. Thus, BEVFusion4D utilizes spatiotemporal data to reinforce detection accuracy.
Experimental Results
BEVFusion4D demonstrates superior performance metrics on the nuScenes dataset, notably with 72.0\% mAP and 73.5\% NDS on the validation set. The framework effectively competes with prior works by enhancing detection in both spatial-only and spatiotemporal scenarios. LGVT aids in refining camera feature representation, while TDA boosts temporal feature alignment, leading to notable gains in challenging scenarios like detecting distant or occluded objects and managing dynamic environments.
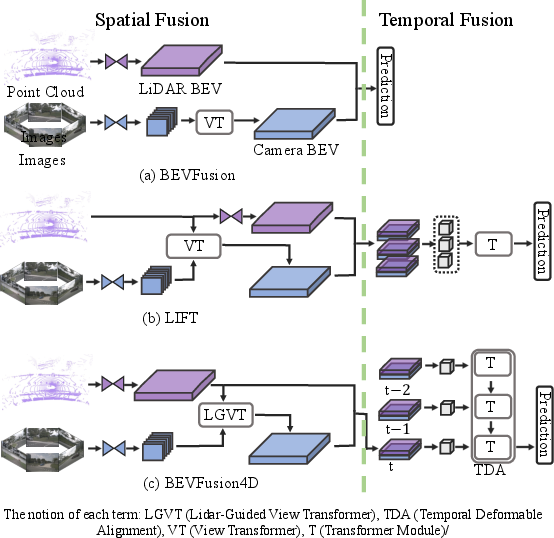
Figure 3: Comparison of BEVFusion4D with relevant works.
Ablation Studies
The framework’s components LGVT and TDA were subject to rigorous evaluation. LGVT, using LiDAR spatial priors for camera BEV generation, proved crucial in improving performance across different detection heads, offering significant mAP enhancements. TDA consistently improved object detection at varying moving speeds, especially under challenging high-speed conditions by reducing motion smear. These ablations underscore the importance of each module's contribution to the overall efficacy of BEVFusion4D.
Implications and Future Work
BEVFusion4D sets a new benchmark for integrating multi-modal, spatiotemporal data in 3D object detection systems. The approach opens avenues for further research into multi-sensor fusion techniques, emphasizing robust temporal information management. Future developments could explore deeper temporal integration and incorporation of additional sensor data, refining both the computational efficiency and detection accuracy in real-world autonomous settings.
Conclusion
BEVFusion4D exemplifies a methodological advance in 3D object detection by addressing multi-modal fusion within BEV space efficiently. Its framework combines spatial precision and temporal dynamics adeptly, elevating detection performance. By doing so, it significantly contributes to the field of autonomous driving, guiding forthcoming multi-modal fusion endeavors.