- The paper introduces ChatGPT’s zero-shot approach for detecting factual inconsistencies via entailment inference, summary ranking, and consistency rating.
- It demonstrates improved performance with chain-of-thought prompting, although limitations arise from lexical bias and shallow semantic understanding.
- The study highlights the need for future research in fine-tuning, enhancing semantic reasoning, and refining prompt strategies for factual evaluation.
ChatGPT as a Factual Inconsistency Evaluator for Text Summarization
Introduction
The paper "ChatGPT as a Factual Inconsistency Evaluator for Text Summarization" (2303.15621) explores the potential of using ChatGPT for evaluating factual inconsistency in text summarization under zero-shot settings. The primary focus is on tasks such as binary entailment inference, summary ranking, and consistency rating. The investigation highlights ChatGPT's performance, pointing out limitations and suggesting areas for future exploration.
Coarse- and Fine-Grained Evaluation Tasks
The authors detail three specific tasks to evaluate factual inconsistency: entailment inference, summary ranking, and consistency rating.
- Entailment Inference: This task is framed as a binary classification problem where the goal is to determine if a summary is consistent with the associated document. Two prompts were used: a zero-shot prompt and a zero-shot chain-of-thought (CoT) prompt. The latter includes step-by-step reasoning to enhance consistency detection.
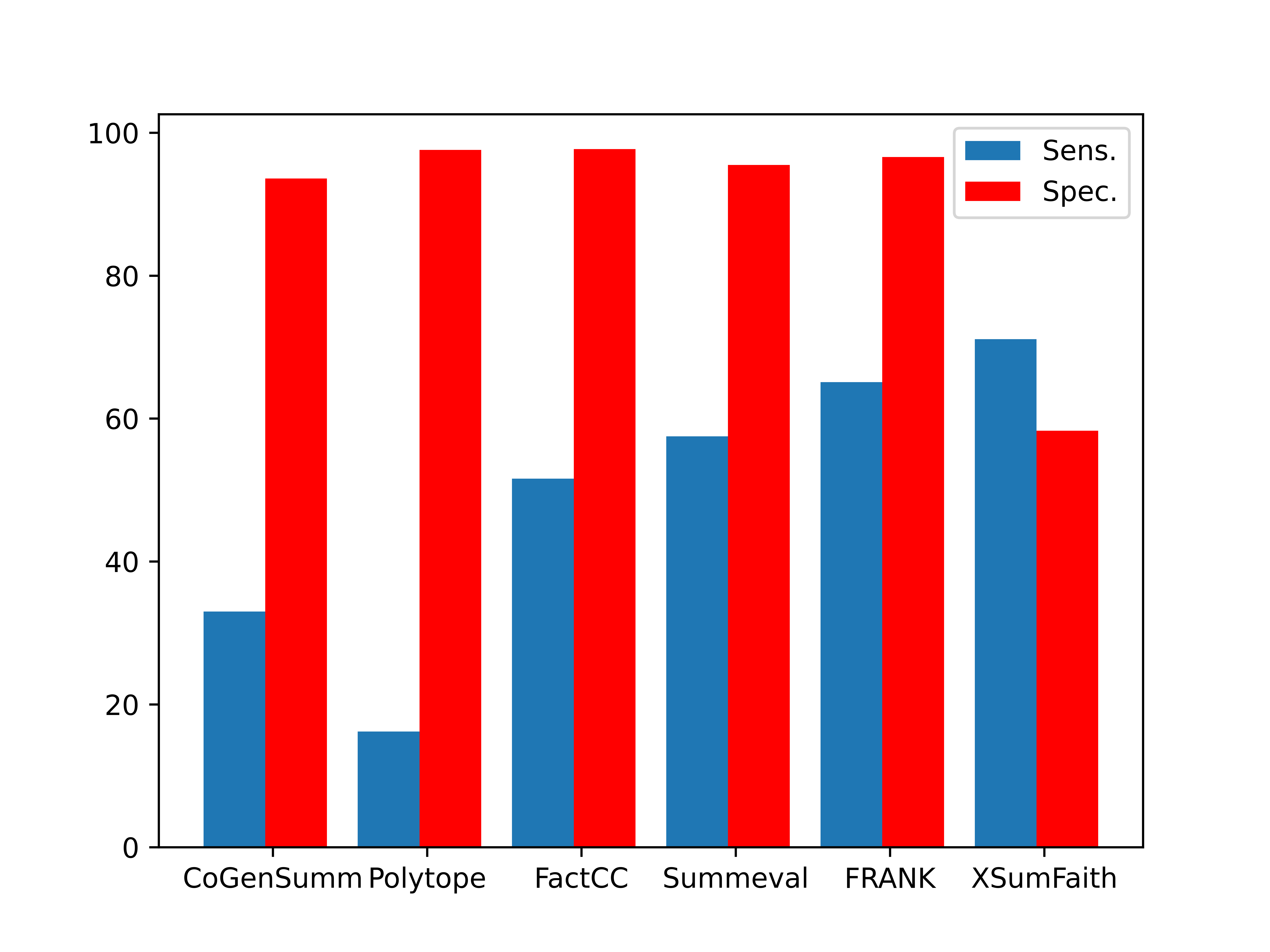
Figure 1: The results of sensitivity and specificity of ChatGPT\textsubscript{ZS-COT}.
- Summary Ranking: In contrast to binary entailment, this task evaluates whether a model can rank a consistent summary higher than an inconsistent one based on a given document. The zero-shot prompt is similar but asks ChatGPT to choose between two summaries.
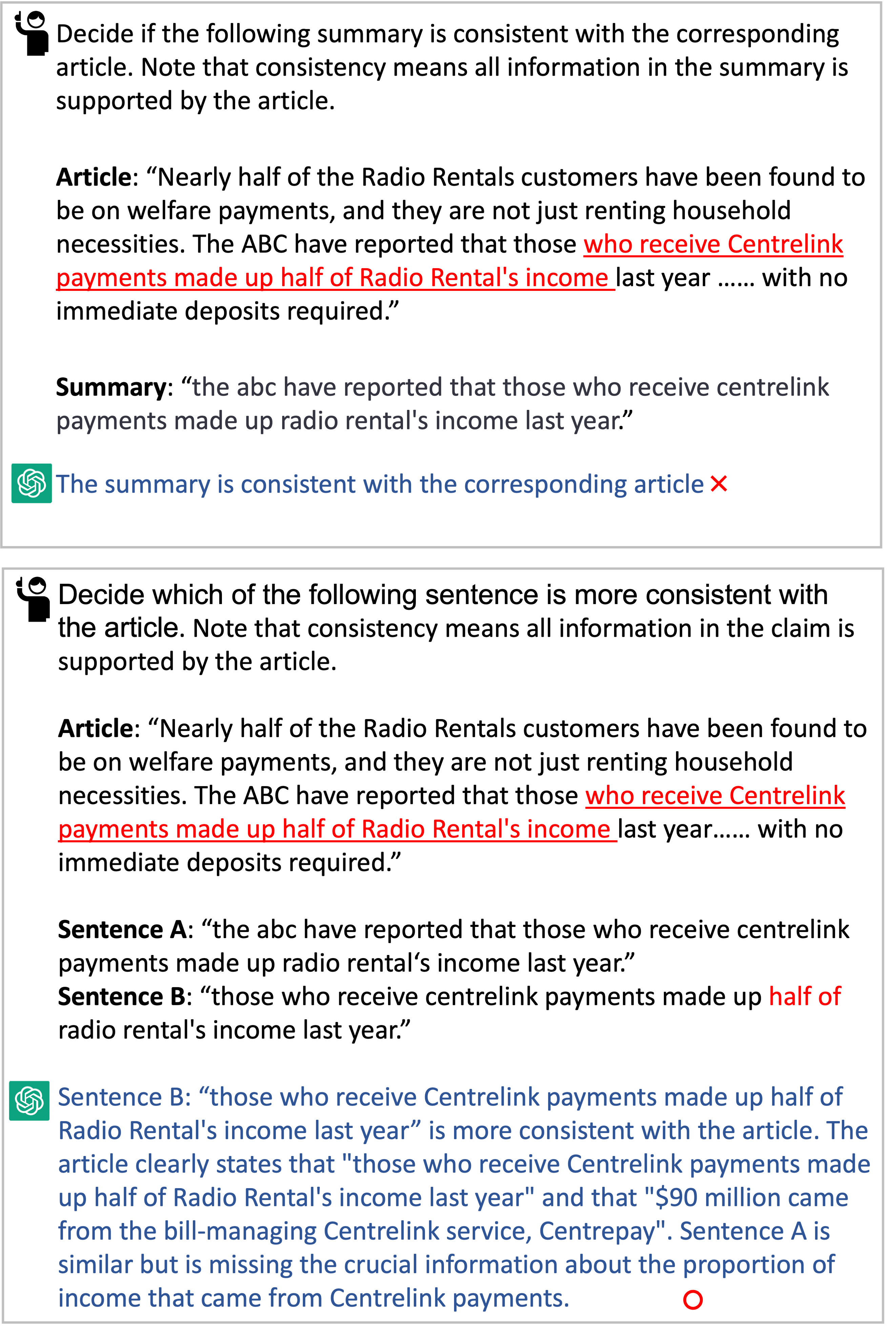
Figure 2: ChatGPT's actions when given the same source document and an inconsistent summary but with and without a consistent one. The red underlined text in the article is content highly related to the candidate summaries.
- Consistency Rating: This involves rating the consistency of a summary with the source article on a numeric scale. This task assesses ChatGPT's ability to provide fine-grained ratings of factual accuracy.
Evaluation and Findings
The evaluation on benchmark datasets reveals the following key findings:
- ChatGPT shows promising potential for zero-shot factual inconsistency detection, outperforming prior state-of-the-art metrics across most datasets in the entailment inference task.
- The zero-shot CoT prompting significantly improves performance by encouraging a more reasoned decision-making process.
- However, ChatGPT demonstrates a preference for predicting high lexical similarity as consistency, sometimes lacking deeper semantic understanding, as evidenced by lower sensitivity to subtle factual inconsistencies.
Error Analysis
The paper also presents several limitations in ChatGPT's performance:
- Lexical Bias: ChatGPT tends to misclassify semantically incorrect summaries as correct if they have high lexical similarity to the source text.

Figure 3: An example of ChatGPT fails to stick to the given definition of consistency.
- False Reasoning: Instances were found where ChatGPT made incorrect logical inferences under CoT-style prompting, especially where explanations were influenced by initial conclusions.

Figure 4: An example of ChatGPT conducts false reasoning.
Conclusion
The preliminary results indicate that ChatGPT could serve as a viable tool for evaluating factual inconsistency in text summarization. Chain-of-thought style prompts notably enhance the model's capabilities. Despite its strengths, areas such as fine-tuning, understanding semantic entailment, and refining prompt structures remain open for future research to address current biases and reasoning shortcomings. These endeavors can lead to more reliable adoption of ChatGPT in practical summarization systems.