- The paper introduces DRPE, a novel framework using LLMs as diverse role-players to evaluate text summaries by combining objective and subjective criteria.
- It leverages static and dynamically generated roleplayers to assess linguistic aspects like coherence, grammar, and informativeness, aligning evaluations closer to human judgment.
- Experiments on benchmarks such as CNN2022 and BBC2022 show that DRPE outperforms traditional metrics with optimal performance achieved using four dynamic roles.
LLMs as Diverse Role-Players for Summarization Evaluation
The paper "LLMs are Diverse Role-Players for Summarization Evaluation" (2303.15078) explores the capacity of LLMs to serve as evaluators of text summarization tasks. Traditionally, metrics such as BLEU, ROUGE, BertScore, and MoverScore have been employed to quantitatively assess the quality of machine-generated summaries. However, these metrics focus on surface-level similarities, often lacking alignment with human evaluations which consider both linguistic accuracy and more abstract dimensions such as coherence, informativeness, and expression. To address the limitations of traditional metrics, the research proposes a novel approach utilizing diverse role-players via LLM-based prompting.

Figure 1: Two summarizations of CNN News, showcasing the limitations of traditional metrics like BLEU and ROUGE.
The study underscores the discrepancies between existing automated metrics (BLEU, ROUGE, BERTScore, etc.) and human judgments in the evaluation of text summarizations. These methods primarily assess lexical and semantic overlaps between generated texts and reference summaries. However, they often fall short in capturing more complex quality aspects, such as coherence and informativeness, that human evaluators consider (Figure 1). Leveraging the capabilities of LLMs to consider both objective and subjective dimensions presents a promising direction for aligning evaluation metrics with human judgment.
Figure 1: Two summarizations of CNN News, demonstrating the deficiencies of traditional metrics like BLEU/ROUGE, which fail to reflect complex text qualities.
Diverse Role-Players Prompting Mechanism
The paper introduces the Diverse Role-Player for Summarization Generation Evaluation (DRPE) framework that seeks to bridge the gap between automated metrics and human scoring. The system is designed to generate qualitative measures through an LLM-based mechanism that emulates human judgment across multiple dimensions by leveraging diversified role players (Figure 2).
Objective and Subjective Roleplayers
In DRPE's framework, a roleplayer-based system evaluates both objective and subjective text dimensions. Static roleplayers are predefined to focus on objective dimensions such as coherence and grammar, while dynamic roles are generated contextually to assess subjective language aspects like engagement and informativeness.
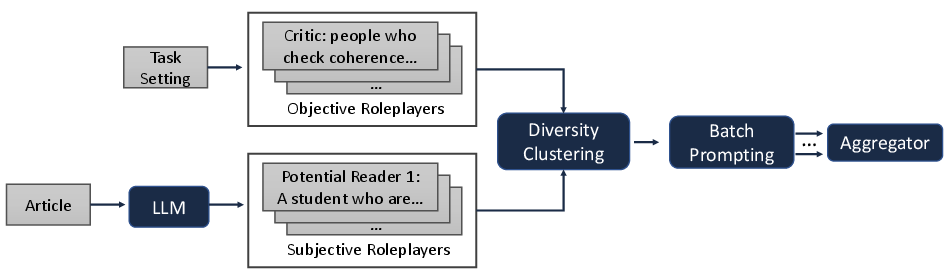
Figure 2: The overall framework of DRPE. Objective roleplayers are curated manually based on task setting, and subjective roleplayers are dynamically generated by LLMs. After diversity clustering, similar roles are eliminated, and all roles are played by LLMs to compare two candidates in batch prompting. Finally, results from multiple roles are aggregated.
Static roleplayers provide evaluation within agreed objective dimensions (Figure 3). These include general public, critics, and news authors, which ensure a foundational judgment of structural elements like grammar and consistency.

Figure 3: Various static roles for the summarization task including the general public, critics ensuring fluency, and coherence, and news authors verifying consistency with the original text.
For subjective criteria, DRPE employs dynamically generated user types. Illustrative examples include stereotype-based roles such as Politicians and Naomi Irion’s Family, each prioritizing different aspects of the summary (Figure 4). These roles are developed using a tailored prompting mechanism, taking the article context into account.

Figure 4: Coarse-grained and fine-grained prompting mechanism for comprehensive user profiles generation.
Methodology
The proposed framework comprises a two-fold roleplayer-based strategy that measures both objective and subjective quality aspects of generated summaries. As LLMs inherently capture rich semantics, they are leveraged in the unique roleplayer paradigm to perform dynamic and static evaluations.
Objective Roleplayer Generation
Objective roleplayers measure standardized linguistic criteria such as coherence, grammar, and fluency, which are broadly applicable across text generation tasks (Figure 3). Each role is expressed in a formal schema involving a Judger type and a corresponding Judger description. LLMs, in a static capacity, simulate real judges by adopting the described roles and voting on each text candidate.
Figure 3: Three different static roles for summarization task. For different generation tasks, different aspects need to be taken into consideration. A good summary usually requires fluent writing, proper wording and capturing key points of raw article.
Subjective Roleplayer Generation
Since human-written summaries hinge on subjective criteria, such as perceived comprehensiveness and usefulness, an LLM-based subjective roles generation mechanism is employed. LLMs are prompted to simulate diverse user type profiles, each characterized by unique informational preferences and perspectives on the text content, as detailed in the description <User type, User description>.
Figure 4: Coarse-grained and fine-grained prompting mechanism for comprehensive user profiles generation.

Figure 5: Compare generated summary and reference summary by multiple roleplayers with batch prompting.
DRPE Framework
The DRPE framework provides a comprehensive evaluation strategy by leveraging a combination of static objective and dynamic subjective roleplayers. Through batch prompting, DRPE consolidates evaluations from these role players, drastically reducing computational resources compared to traditional CoT approaches. Using a multi-roleplayer strategy allows for both refined analysis of text quality and higher consistency with human assessment.
Figure 2: The overall framework of DRPE. Objective roleplayers are curated manually based on task setting, and subjective roleplayers are dynamically generated by LLMs. After diversity clustering, similar roles are eliminated, and all roles are played by LLMs to compare two candidates in batch prompting. Finally, results from multiple roles are aggregated.
In Figure 2, the overall framework showcases the process where both static and dynamically generated roleplayers are engaged to evaluate candidate summaries against reference summaries. The multi-roleplayer system proves to be a promising alternative to traditional metrics by providing a comprehensive evaluation while being cost-efficient.

Figure 6: Evaluation procedure for two summaries given a piece of news. We use the green font to represent the content generated by the model. With suitable prompting, the LLM is able to generate relevant roles and generate judgment for these roles.
4.3. Experiments
Extensive experiments on datasets such as CNN2022 and BBC2022 were performed to evaluate the performance of the DRPE framework. The results, as depicted in Figure 5, illustrate that the proposed DRPE method attains superior performance over existing metrics and exhibits high congruity with human judgment across multiple datasets. Furthermore, as shown in (Figure 7), the effect of role number on the model performance reveals that the method achieves optimal performance with four dynamic roles for each case, emphasizing the impact of diversified role inclusivity.
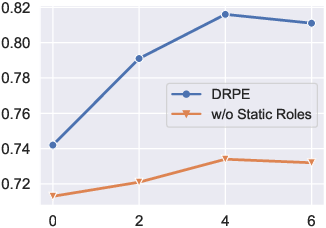
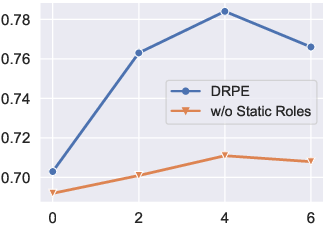
Figure 7: Effect of role number on model performance.
- Conclusion
The paper introduces the "LLMs are Diverse Role-Players for Summarization Evaluation," presenting a multi-roleplayer prompting strategy embedded in the novel DRPE framework for text summarization evaluation. By taking into account both static objective metrics and dynamically generated subjective roles, DRPE enhances the agreement with human evaluators across multiple dimensions, demonstrating strong numerical results on benchmark datasets including CNN2022 and BBC2022. This represents a compelling advancement over traditional lexical-based metrics. This work opens avenues for further exploration into adaptive role-based evaluation frameworks for various NLP tasks, beyond summarization, to better mimic human judgment and improve automatic metric reliability. (Figure 2)
Future research could explore optimization of dynamic roleplayer generation, fine-tune discrimination between high-quality and low-quality generated summaries, and extend this framework to other text generation tasks like machine translation or dialogue systems, addressing the multifaceted nature of human language understanding.

