- The paper demonstrates that the MSC framework combines masked point modeling with contrastive learning to address scalability challenges in unsupervised 3D representation learning.
- The methodology applies scene-level point cloud augmentations and view mixing to bypass inefficient RGB-D frame matching, accelerating pre-training by at least 3x.
- Experimental results on ScanNet and ArkitScenes reveal improved downstream performance, achieving state-of-the-art semantic segmentation with 75.5% mIoU.
Masked Scene Contrast for Unsupervised 3D Representation Learning
The paper "Masked Scene Contrast: A Scalable Framework for Unsupervised 3D Representation Learning" (2303.14191) introduces a novel approach to unsupervised 3D representation learning that addresses the limitations of previous methods, particularly in terms of scalability and efficiency. By generating contrastive views directly from scene-level point clouds and incorporating masked point modeling, the proposed Masked Scene Contrast (MSC) framework achieves significant improvements in pre-training speed and downstream task performance.
Addressing Inefficiencies in 3D Unsupervised Learning
Previous work, such as PointContrast, relied on matching RGB-D frames to generate contrastive views, which is inefficient due to redundant frame encoding, low learning efficiency, and dependency on raw RGB-D data. The MSC framework overcomes these limitations by directly operating on scene-level point clouds, eliminating the need for RGB-D frames and enabling more diverse scene representations. This approach accelerates the pre-training procedure by at least 3x while maintaining or improving performance on downstream tasks.
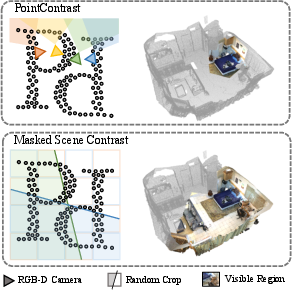
Figure 1: Comparison of unsupervised 3D representation learning. The previous method relies on raw RGB-D frames with restricted views for contrastive learning, resulting in low efficiency and inferior versatility. Our approach directly operates on scene-level views with contrastive learning and masked point modeling, leading to high efficiency and superior generality, further enabling large-scale pre-training across multiple datasets.
Masked Scene Contrast Framework
The MSC framework consists of two key components: contrastive learning and reconstructive learning. The contrastive learning component generates contrastive views of the input point cloud through a series of data augmentations, including photometric, spatial, and sampling transformations. A view mixing strategy further enhances the robustness of the learned representations. The reconstructive learning component employs masked point modeling, where a portion of the point cloud is masked and the model is trained to reconstruct the masked color and surfel normal information. This is achieved through the use of contrastive cross masks, which ensure that the masked regions in the two views are non-overlapping.
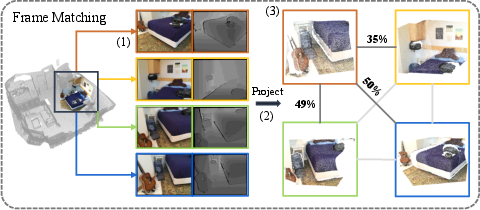
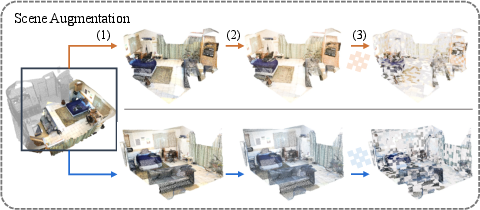
Figure 2: View generation. Compared with frame matching (FM), our scene augmentation (SA) is efficient and effective. 1. SA can end-to-end produce contrastive views on the original point cloud with ignorable latency, while FM requires preprocessing devouring enormous storage resources ( additional 1.5 TB storage for ScanNet) in step 2 and pairwise matching is time-consuming. 2. SA produces scene-level views, while FM can only produce frame-level views containing limited information. Benefiting from advanced photometric augmentations, SA has the capacity to simulate the same scene under different lighting.
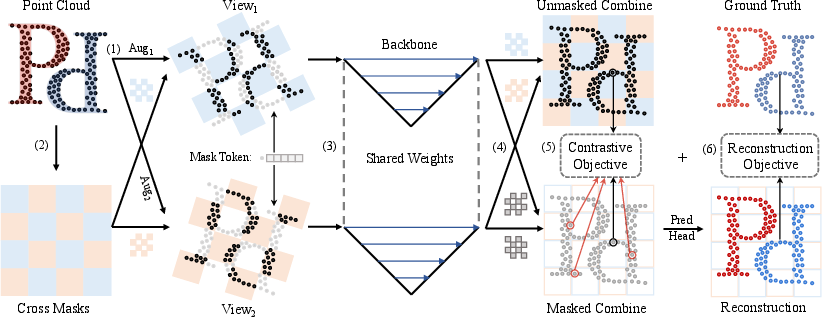
Figure 3: Our MSC framework. (1) Generating a pair of contrastive views with a well-curated data augmentation pipeline consisting of photometric, spatial, and sampling augmentations. (2) Generating a pair of complementary masks and applying them to the pair of contrastive views. Replacing masked point features with a learnable mask token vector. (3) Extracting point representation with a given U-Net style backbone for point cloud understanding. (4) Reassembling masked contrastive views to masked points combination and unmasked points combination. (5) Matching points share similar positional relationships in the two views as positive sample pairs and computing InfoNCE loss to optimize contrastive objective. (6) Predicting masked point color and normal and computing Mean Squared Error loss and Cosine Similarity Loss with ground truth respectively, to optimize the reconstruction objective.
Implementation Details
The framework utilizes a U-Net style backbone for feature extraction, specifically SparseUNet. The data augmentation pipeline includes spatial augmentations (random rotation, flipping, and scaling), photometric augmentations (brightness, contrast, saturation, hue, and Gaussian noise jittering), and sampling augmentations (random cropping and grid sampling). The contrastive loss is computed using InfoNCE, and the reconstruction loss is a combination of mean squared error for color reconstruction and cosine similarity loss for surfel normal reconstruction.
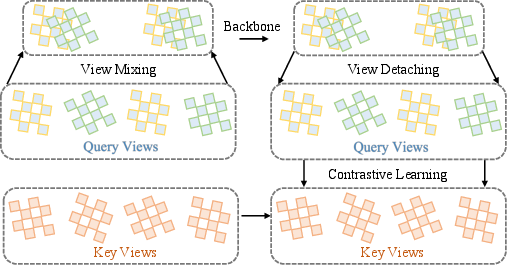
Figure 4: View Mixing. Randomly mix up query views while keeping key views unmixed for a given batch of pairwise contrastive views. Detaching mixed query view after feature extraction for contrastive comparison with matched key views.
Experimental Results
Extensive experiments on ScanNet and ArkitScenes datasets demonstrate the effectiveness of the MSC framework. The results show that MSC achieves state-of-the-art performance on semantic segmentation and instance segmentation tasks, surpassing previous unsupervised pre-training methods. Ablation studies validate the importance of each component of the framework, including the view generation pipeline, data augmentation strategy, view mixing technique, and masked point modeling approach. Notably, the framework achieves 75.5\% mIoU on the ScanNet semantic segmentation validation set.

Figure 5: Masked scenes and color reconstructions. We visualize one of the cross masks of each scene with a mask rate of 50\% (left) and color reconstruction of the masked point combinations (right). We pre-train our MSC with a mask patch size of 10cm and generalize to results to different mask sizes. Compared with the original point clouds, the loss of detail cannot be avoided, while boundary and texture are well preserved by our model.
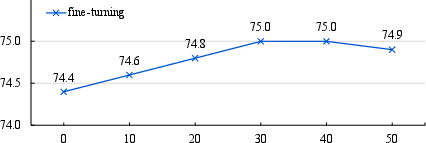
Figure 6: Masking ratio. A masking ratio ranging from 30\% to 40\% works well with our design, and a higher mask rate negatively influences contrastive learning. The y-axes represent ScanNet semantic segmentation validation mIoU (\%).

Figure 7: Photometric augmentation.
Conclusion
The MSC framework addresses key challenges in unsupervised 3D representation learning by introducing an efficient and scalable approach that combines contrastive learning and masked point modeling. The experimental results demonstrate that MSC achieves significant improvements in pre-training speed and downstream task performance, enabling large-scale pre-training across multiple datasets. This work opens up new possibilities for unsupervised 3D representation learning and paves the way for future research in this area.