- The paper introduces NS3D, a framework that combines semantic parsing, 3D object-centric encoding, and neural execution to ground objects and relations in 3D scenes.
- The methodology employs a Codex-based semantic parser and PointNet++ encoder to efficiently learn and execute symbolic programs from minimal training data.
- Experimental results show significant improvements in data efficiency, generalization, and zero-shot transfer in complex 3D scene understanding tasks.
NS3D: Neuro-Symbolic Grounding of 3D Objects and Relations
Overview
The paper presents NS3D, a neuro-symbolic framework designed to tackle challenges associated with 3D scene understanding by efficiently grounding 3D objects and relations. The primary focus lies in improving data efficiency, generalization, and zero-shot transfer abilities in tasks involving complex 3D grounded language, such as the ReferIt3D view-dependence task and 3D question-answering tasks. NS3D incorporates semantic parsing, 3D object-centric encoding, and neural execution of symbolic programs to achieve significant performance improvements over existing methods.
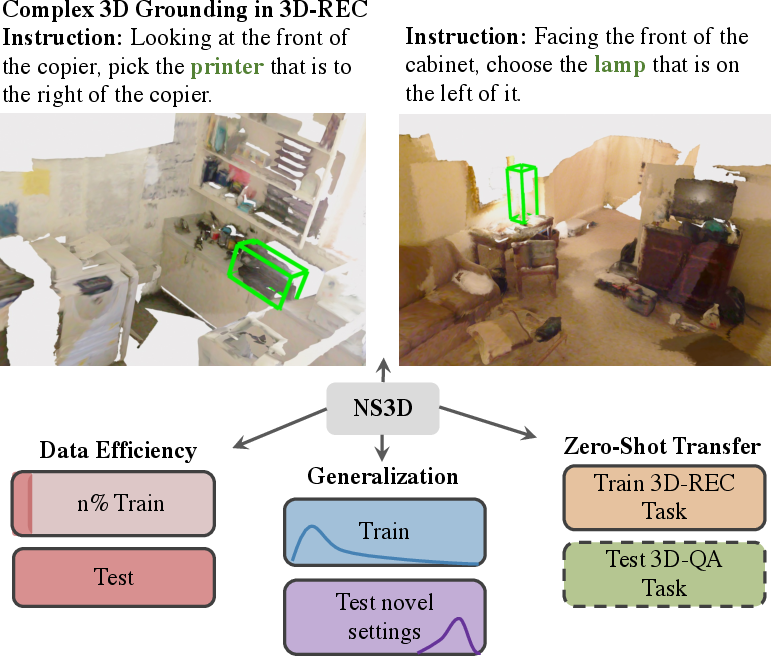
Figure 1: NS3D achieves grounding of 3D objects and relations in complex scenes, while showing state-of-the-art results in data efficiency, generalization, and zero-shot transfer.
System Architecture
NS3D comprises three main components:
- Semantic Parser: This module translates language inputs into symbolic programs using Codex, a large language-to-code model. It allows efficient parsing with minimal examples, overcoming limitations of predefined grammars.
- 3D Object-Centric Encoder: This encoder learns features from input object point clouds using PointNet++ networks, distinguishing object features from relational ones. The separation assists in precise relational reasoning, especially in high-arity relations essential for 3D scene comprehension.

Figure 2: NS3D is composed of three main components. a) A semantic parser parses the input language into a symbolic program. b) A 3D object-centric encoder takes input objects and learns object, relation, and ternary relation features. c) A neural program executor executes the symbolic program with the learned features to retrieve the target referred object.
- Neural Program Executor: Implements hierarchical execution of parsed programs based on learned object-centric features, tackling operations like filtering, relating objects, and executing ternary relations in the scene to identify the target object accurately.
Implementation Details
Semantic Parsing
NS3D employs Codex for semantic parsing, capable of constructing detailed hierarchical program structures from language input with minimal prompting examples. This advancement facilitates parsing across unseen categories and relations without specific training.
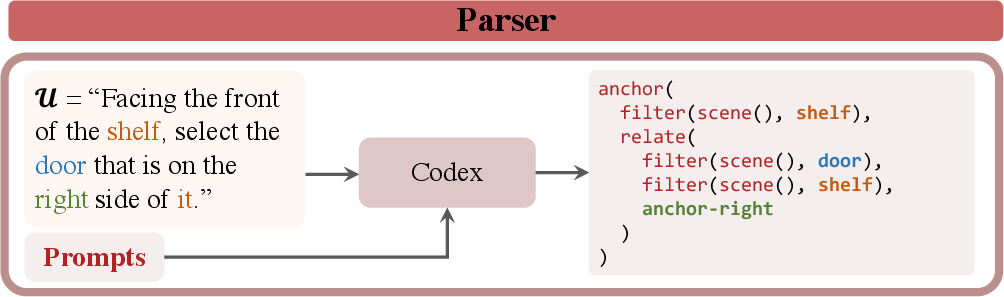
Figure 3: The NS3D semantic parser leverages Codex to parse input language into symbolic programs.
3D Feature Encoding
The object-centric encoder derives features from the position and color of object point clouds, using distinct networks for object-related and relation-related features. Separate encoders specialize in modeling spatial relations, crucial for addressing complex scene configurations.
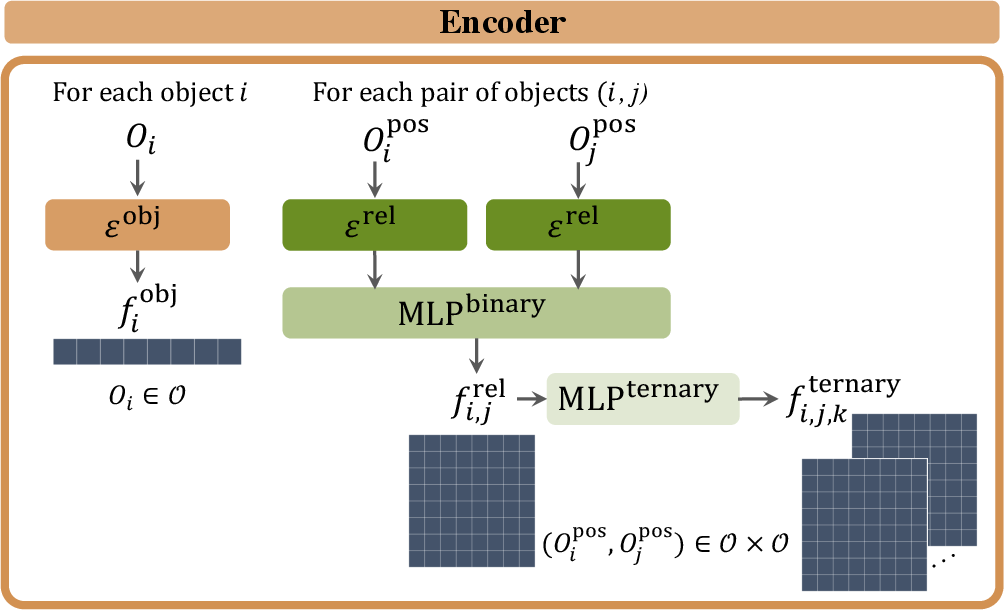
Figure 4: The NS3D object-centric encoder learns object, relation, and ternary relation features from input object point clouds.
Program Execution
The executor handles object score vectors in log space, manipulating them through operations such as filter, relate, and ternary_relate. It recursively composes these operations to resolve referring expressions.
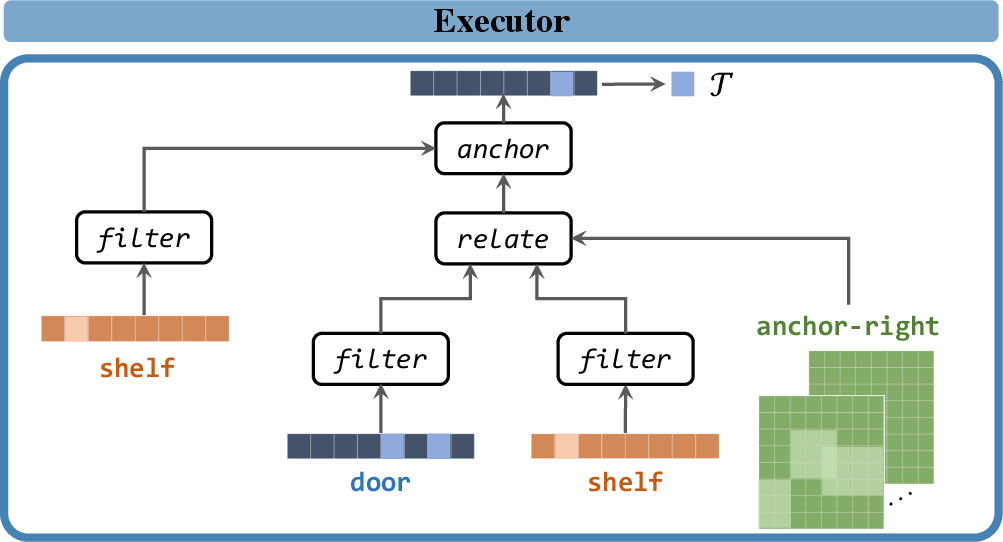
Figure 5: The NS3D neural program executor executes the symbolic program recursively with the learned 3D features, and returns the target referred object T.
Experimental Results
Data Efficiency and Generalization
NS3D demonstrates superior data efficiency, achieving high accuracy with only a fraction of the training data compared to state-of-the-art methods. It maintains performance across unseen data distributions and scene types, proving its generalization capabilities.
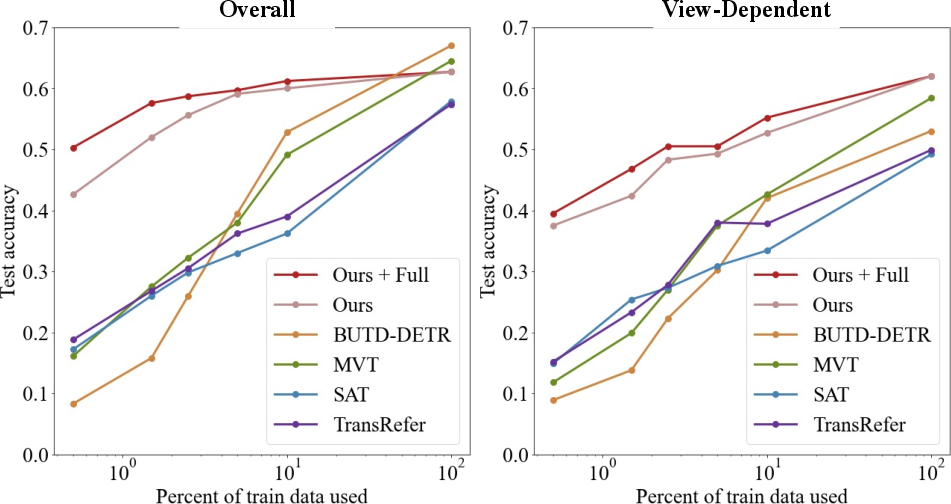
Figure 6: NS3D outperforms prior works by a large margin with 0.5\%, 1.5\%, 2.5\%, 5\%, and 10\% of train data.
Zero-Shot Transfer
A notable feature of NS3D is its ability to transfer learned object features to new tasks, showcased by its strong performance in a novel 3D-QA task without any additional data or tuning, attesting to the robustness and versatility of its modular design.

Figure 7: Examples of 4 questions types from the 3D-QA task.
Conclusion
NS3D introduces a powerful neuro-symbolic model for 3D scene grounding, significantly enhancing performance in challenging 3D-REC and generalization tasks through modular and compositional approaches. Future work could explore integration with advanced object localization models to extend capabilities to directly learn from full 3D scenes. The method strengthens the foundation for efficient and interpretable 3D scene understanding in AI applications.