- The paper demonstrates ART's ability to automatically generate structured multi-step reasoning programs that integrate external tool calls to solve complex tasks.
- It leverages task and tool libraries to retrieve relevant sub-tasks and achieve over a 22 percentage point improvement on benchmarks like BigBench and MMLU.
- Human feedback and an extensible design further refine ART, enhancing its adaptability and performance across diverse tasks.
Introduction
The paper introduces ART, a novel framework for enhancing multi-step reasoning and tool-use capabilities of LLMs in few- and zero-shot settings. Unlike existing methods that heavily rely on task-specific handcrafted prompts, ART leverages frozen LLMs to generate reasoning steps as structured programs and seamlessly integrate external tools. This approach addresses the inherent limitations of LLMs in executing complex reasoning tasks and expands their applicability across diverse benchmarks like BigBench and MMLU.
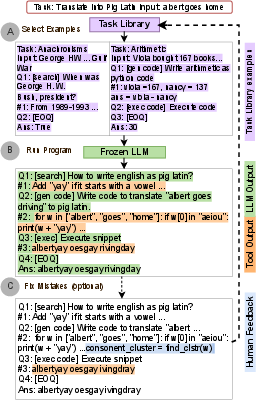
Figure 1: ART generates automatic multi-step decompositions for new tasks by selecting decompositions of related tasks in the task library and selecting and using tools in the tool library alongside LLM generation. Humans can optionally edit decompositions (eg. correcting and editing code) to improve performance.
ART Framework
ART operates by constructing a task library comprising programs with multi-step decompositions for various tasks, alongside a tool library containing functionalities like search and code execution. When presented with a new task, ART retrieves relevant demonstrations from the task library to inform the LLM how to decompose the task and utilize available tools efficiently. The programs are parsed using a custom grammar, facilitating the pausing and resumption of generation at tool calls.

Figure 2: A run-through of ART on a new task, Physics QA. (A) Programs of related tasks like anachronisms and Math QA provide few-shot supervision to the LLM --- related sub-steps and tools in these programs can be used by the LLM for cross-task generalization. (B) Tool use: Search is used to find the appropriate physics formula, and code generation and execution are used to substitute given values and compute the answer.
Program Generation and Execution
During execution, ART translates task instances into programs, parsing reasoning steps to invoke tools, thus enriching LLM capabilities without additional training. Each tool, be it a search engine or a code interpreter, is triggered at the sub-task level, and the results are incorporated back into the LLM-generated program before proceeding.
Human Feedback and Extensibility
ART also incorporates an extensible feedback mechanism, allowing human operators to refine the reasoning process by updating task and tool libraries. This feature drastically enhances task-specific performance with minimal human intervention, fostering adaptability and continual improvement.
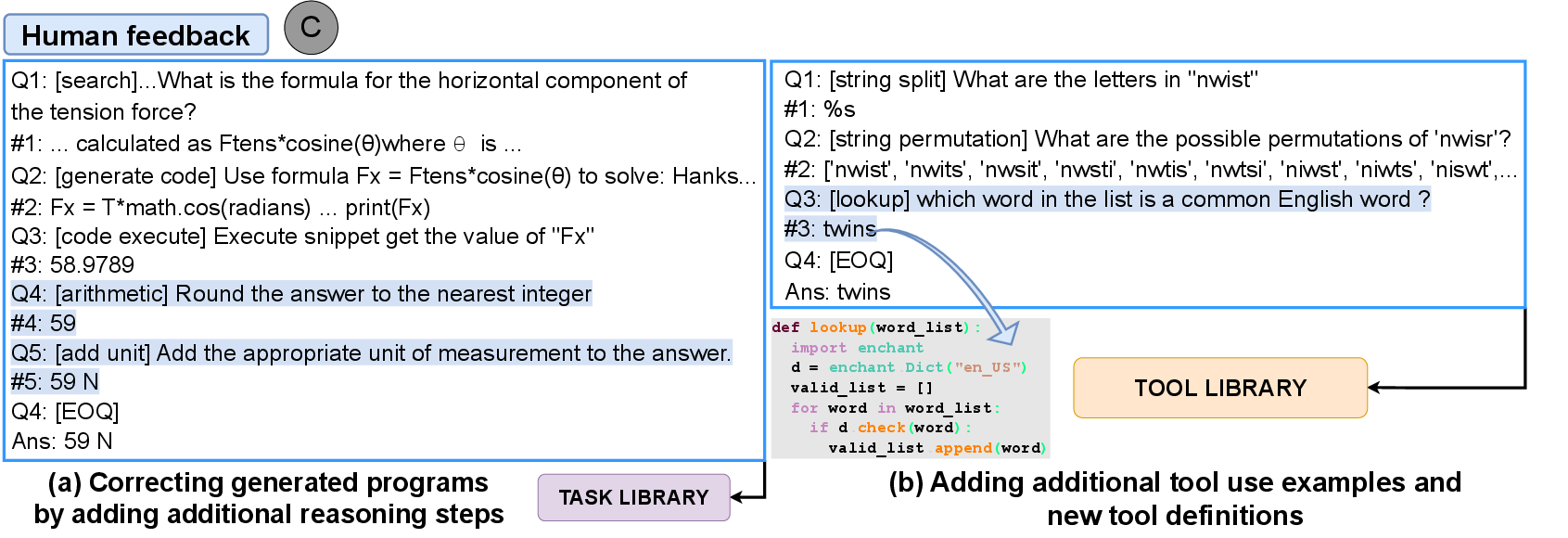
Figure 3: Human feedback to ART shown for (a) PQA where reasoning steps are added to the program and; (b) Word unscrambling where tool library is augmented with a new lookup tool.
Evaluation
Benchmarks and Results
ART was evaluated on tasks in the BigBench and MMLU benchmarks, demonstrating improvements over conventional few-shot prompting and other automatic CoT approaches. ART's integration of tool-use capabilities particularly benefitted arithmetic and algorithmic tasks, yielding an average performance increase of over 22 percentage points. It achieved enhanced results on unseen tasks, matching or surpassing hand-crafted CoT prompts on several instances.
Comparison with Existing Methods
Compared to state-of-the-art techniques like Auto-CoT and Toolformer, ART exhibited superior performance due to its structured approach to multi-step reasoning and its effective use of external tools. By mitigating the need for finely-tuned task-specific prompts, ART maintains flexibility and robustness across varied tasks, setting a new standard for adaptability in LLM applications.
Conclusion
ART stands as a comprehensive framework that significantly enhances the reasoning and tool-use capabilities of LLMs. By automating the generation of reasoning programs and seamlessly incorporating external computational tools, ART presents a substantial leap in the application of LLMs to complex, multi-step tasks. Its modular architecture and receptiveness to human feedback posit it as a flexible and adaptive solution, promising further advancements with developments in LLM training methodologies and tool augmentations.

