- The paper introduces a CNN that integrates phase and derivative features to estimate room volume and RT60 from noisy, reverberant speech samples.
- It demonstrates significant improvements over magnitude-only methods, with lower MSE and higher correlation metrics for parameter estimation.
- The methodology enables joint estimation and suggests potential extensions to multi-band RT60 and other acoustic parameters in practical systems.
Blind Acoustic Room Parameter Estimation Using Phase Features
Introduction
This work presents a data-driven approach for blind estimation of acoustic room parameters—specifically, room volume and reverberation time (RT60)—from noisy, reverberant single-channel speech recordings. The methodology uniquely incorporates phase-related features into a convolutional neural network (CNN) architecture for parameter estimation. Prior art largely focuses on magnitude-based spectral features, particularly energy in specific frequency bands, which overlook the representational power of the phase domain. Inspired by recent advances in speech enhancement that utilize phase features, this paper systematically evaluates the additive efficacy of phase and phase-derivative features. The experimental design leverages a diversified dataset including measured and synthesized room impulse responses (RIRs).
Data and Audio Generation Pipeline
The authors assemble a heterogeneous corpus leveraging four public RIR datasets—ACE, AIR, BUT ReverbDB, and OpenAIR—covering a wide dynamic range of room sizes and RT60 values, augmented with custom in-house RIR measurements spanning critically undersampled mid-sized acoustic spaces. To further densify the dataset and increase variability, 30 geometrically diverse synthetic RIRs are generated via the image-source method using pyroomacoustics. The data distribution for room volumes and RT60 achieved by this assembly is shown below.
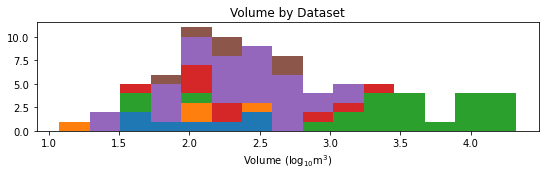
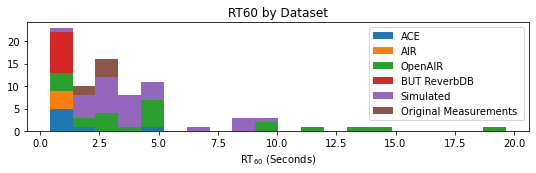
Figure 1: Histogram of room impulse responses across a spectrum of volumes and RT60 from all contributing datasets.
Reverberant audio samples are synthesized by convolving anechoic speech from the ACE dataset with RIRs, further combined with spatially consistent noise at varying SNR levels. The data is stratified into mutually exclusive train, validation, and test splits by room, ensuring strict generalization assessment to unseen environments.
Featurization and Model Architecture
Two-dimensional time-frequency representations are constructed using a 20-band Gammatone filterbank (50 Hz–2 kHz), following STFT computation. Key variants explored include classic log-magnitude features, phase spectrograms, phase derivatives, and higher-order continuity descriptors. Derivative features approximate local phase variations across spectral and temporal neighborhoods, and the phase continuity metric operationalizes second partial derivatives to encode the smoothness of phase evolution, potentially sensitive to boundary effects and modal behavior induced by room acoustics.
The core architectural backbone is a moderate-depth CNN with four time-domain and two frequency-domain convolutional layers, interleaved by pooling, followed by dropout and a final fully connected mapping. The architecture is visualized below, emphasizing input dimensionality coupling to feature modality.

Figure 2: Schematic of the 2D CNN architecture; input layer height dynamically adjusts to the feature type dimensionality.
Training optimizes MSE on the log-transformed target parameters, addressing the high dynamic range in room characteristics. Input feature combinations are varied with hyperparameter constancy to isolate the effect of feature augmentation.
Results
The comparative results between baseline (magnitude-only) and proposed phase-augmented models are robustly quantified using MSE, Pearson correlation, multiplicative mean error (MM), and normalized variance ratio (VR). The inclusion of phase features (+Phase) yields clear improvements in both room volume and RT60 estimation across all metrics. For instance, on volume estimation, MSE drops from 0.4184 (baseline) to 0.3630 (+Phase), and correlation rises correspondingly from 0.5736 to 0.6479. Phase continuity features (+Continuity) provide marginal further benefit for RT60, but do not enhance volume estimation—a likely consequence of sample and model size limitations, as higher-order derivatives demand greater expressive capacity and regularization.
Performance is further illustrated by confusion matrices on the train/validation/test splits for the +Phase model, demonstrating accurate recovery of ground-truth volume over the sampled range, with largest errors concentrated in poorly sampled or outlier-sized rooms.
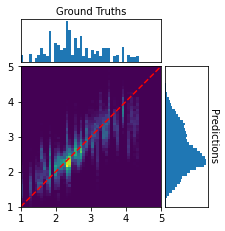
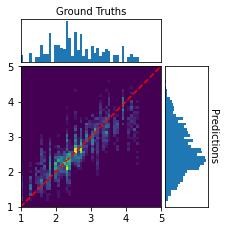
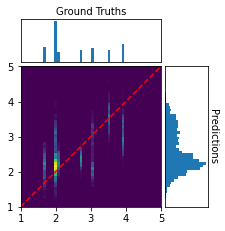
Figure 3: Confusion matrices for predicted vs. true log-volume, demonstrating stable estimation over most volume ranges.
The joint prediction of both volume and RT60 using a single output head does not appreciably compromise accuracy, with negligible loss in correlation compared to independently trained models. The authors attribute this to strong latent feature overlap: both parameters are encoded in the low-frequency temporal phase structure retained in the proposed representations.
Implications and Future Work
This study empirically establishes the informativeness of phase and derivative features for blind estimation of global room parameters in reverberant speech. The gains are especially significant given the single-microphone constraint, which enhances practical viability for consumer and embedded applications. The methodology readily generalizes to joint estimation tasks, simplifying deployment.
For future work, the paper suggests several promising directions: extension to multi-band RT60, absorption coefficients, or full surface area estimation, as well as leveraging richer or complementary phase representations through deep, wider, or multichannel CNN architectures. The potential for 3D convolutional input spanning spectral, temporal, and feature dimensions is highlighted, paralleling trends in sound event detection literature.
Conclusion
By incorporating phase-related features, including numerical derivatives and continuity, into the CNN-based framework, this work advances the state of the art in blind acoustic parameter inference from single-channel speech data. Quantitative benefits are demonstrated over prior magnitude-only methods on both synthesized and real RIRs. The approach promises greater representational fidelity for reverberation fingerprint estimation, unlocking improved speech enhancement and immersive audio rendering capabilities for practical systems.
(2303.07449)

