- The paper introduces a novel Rank model that quantifies both inter- and intra-class emotion intensities to enhance expressiveness in TTS systems.
- It integrates the Rank model with FastSpeech2, employing an Intensity Extractor to adjust phoneme-level features like pitch, energy, and duration.
- Experimental evaluations using subjective tests and objective metrics demonstrate improved controllability and naturalness over baseline models.
Fine-grained Emotional Control of Text-To-Speech Models
The paper presents a novel approach for controlling emotional intensity in Text-To-Speech (TTS) systems by leveraging inter- and intra-class emotion distances. This method enhances the granularity and expressiveness of emotional speech synthesis, addressing the limitations of current TTS models that struggle with fine-grained emotion control.
Introduction
The introduction highlights the need for advanced emotional control in TTS models, which traditionally generate neutral speech with limited emotional variation. Current models, such as GST and RFTacotron, attempt to inject emotion using global labels or style tokens. However, they often fail to capture subtle emotional nuances, leading to challenges in producing speech that matches the user's intentions or contextual needs.
The proposed solution suggests using intensity labels to manually adjust emotion at the phoneme level, which enhances control and expressiveness in synthesized speech. The Rank model introduced in this paper addresses the deficiency in discerning intra-class differences, which is crucial for producing speech with varying levels of emotional intensity.
Approach
The approach utilizes two integral components: a Rank model and a TTS model (FastSpeech2).
Rank Model
The Rank model is designed to map speech into intensity representations, extracting emotion intensity information and outputting scores that reflect these intensities. The model leverages Mixup techniques to create augmented speech samples, allowing it to identify both inter-class and intra-class emotion distances.
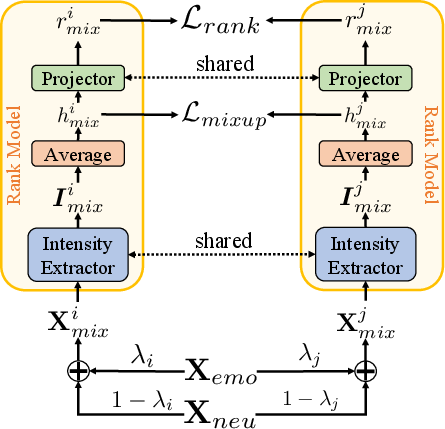
Figure 1: The training of our Rank model. Xemo represents speech samples from non-neutral emotion classes, processed by the Intensity Extractor to generate intensity representations.
The Rank model uses intensity representations to compute a scalar rank, which is then evaluated using rank loss. This loss ensures the model can differentiate between samples with varying levels of non-neutral emotion.
FastSpeech2 is employed to convert phonemes to speech, incorporating an Intensity Extractor to determine pitch, energy, and duration based on input phonemes and intensity representations.
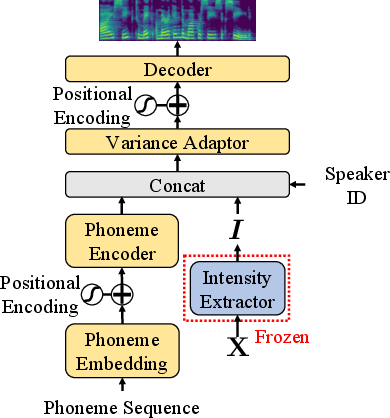
Figure 2: The training of FastSpeech2, a trained Intensity Extractor is combined to provide intensity representations.
The integration of the Intensity Extractor ensures that synthesized speech reflects the desired emotion intensity, allowing for detailed control over emotional expression at runtime.
Experiments
Emotion Intensity Controllability
The paper provides subjective evaluations, highlighting the model’s ability to distinguish between varying intensity levels (Min, Median, Max) in synthesized speech. The results indicate superior controllability compared to baseline models such as RFTacotron and FEC.
Emotion Expressiveness
Preference tests assess the clarity of emotional expression in speech. The results demonstrate that the proposed model effectively conveys emotions more distinctly than existing methods.
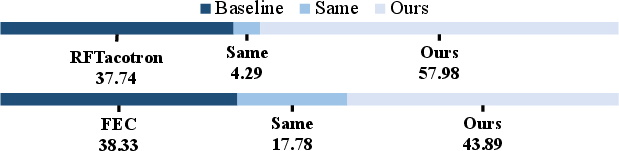
Figure 3: Preference test for emotion expressiveness.
Quality and Naturalness Evaluation
Objective measures (Mean Cepstral Distortion) and subjective evaluations (Mean Opinion Score) further validate the improved speech quality and naturalness offered by the proposed model.
Conclusion
The paper contributes significantly to the field of emotional speech synthesis by introducing a model that captures nuanced emotion expressiveness in speech at a fine-grained level. By considering both inter- and intra-class distances, the Rank model enables more precise emotional control, surpassing two state-of-the-art baselines in terms of emotional intensity controllability, expressiveness, and naturalness. This approach sets a foundation for future advancements in personalized and context-aware speech synthesis applications.