Adding Conditional Control to Text-to-Image Diffusion Models
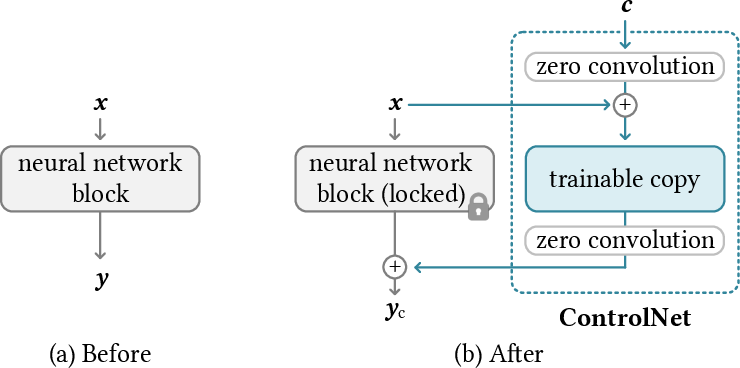
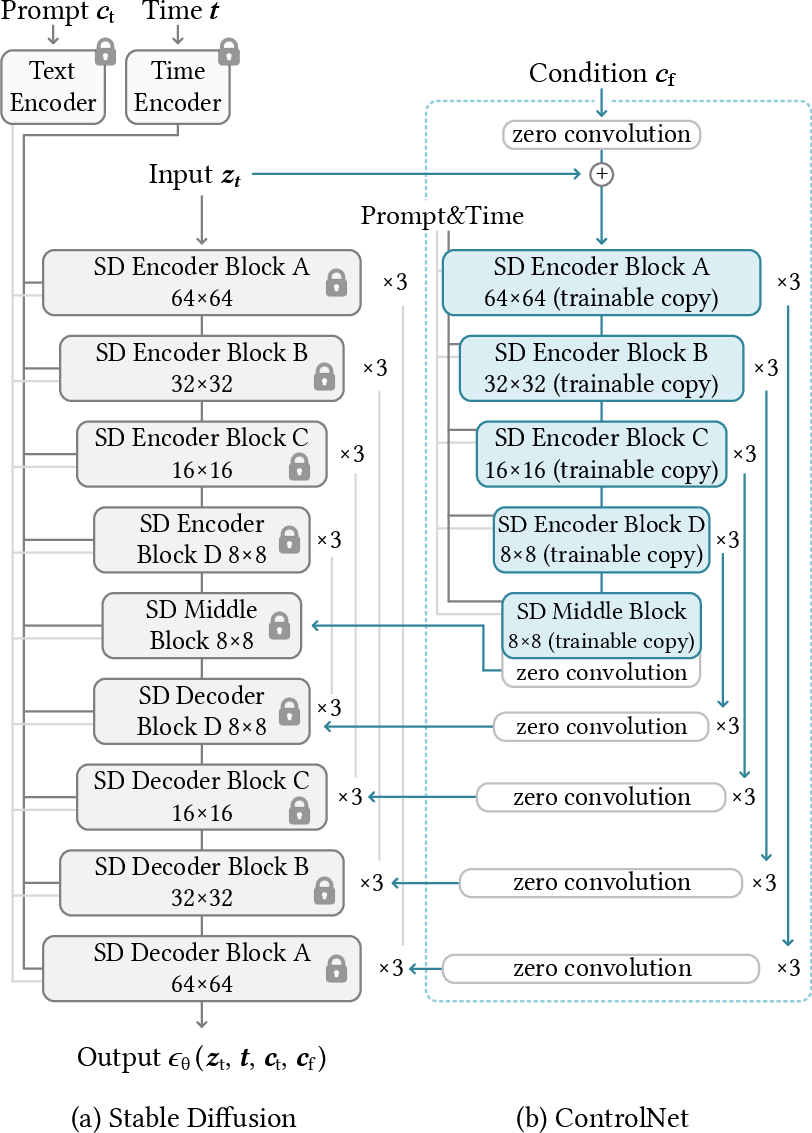
Abstract: We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text-to-image diffusion models. ControlNet locks the production-ready large diffusion models, and reuses their deep and robust encoding layers pretrained with billions of images as a strong backbone to learn a diverse set of conditional controls. The neural architecture is connected with "zero convolutions" (zero-initialized convolution layers) that progressively grow the parameters from zero and ensure that no harmful noise could affect the finetuning. We test various conditioning controls, eg, edges, depth, segmentation, human pose, etc, with Stable Diffusion, using single or multiple conditions, with or without prompts. We show that the training of ControlNets is robust with small (<50k) and large (>1m) datasets. Extensive results show that ControlNet may facilitate wider applications to control image diffusion models.
- Sadia Afrin. Weight initialization in neural network, inspired by andrew ng, https://medium.com/@safrin1128/weight-initialization-in-neural-network-inspired-by-andrew-ng-e0066dc4a566, 2020.
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 7319–7328, Online, Aug. 2021. Association for Computational Linguistics.
- Only a matter of style: Age transformation using a style-based regression model. ACM Transactions on Graphics (TOG), 40(4), 2021.
- Hyperstyle: Stylegan inversion with hypernetworks for real image editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18511–18521, 2022.
- Alembics. Disco diffusion, https://github.com/alembics/disco-diffusion, 2022.
- Spatext: Spatio-textual representation for controllable image generation. arXiv preprint arXiv:2211.14305, 2022.
- Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- Multidiffusion: Fusing diffusion paths for controlled image generation. arXiv preprint arXiv:2302.08113, 2023.
- Masksketch: Unpaired structure-guided masked image generation. arXiv preprint arXiv:2302.05496, 2023.
- Instructpix2pix: Learning to follow image editing instructions. arXiv preprint arXiv:2211.09800, 2022.
- John Canny. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, (6):679–698, 1986.
- Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
- Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12299–12310, 2021.
- Vision transformer adapter for dense predictions. International Conference on Learning Representations, 2023.
- Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8789–8797, 2018.
- darkstorm2150. Protogen x3.4 (photorealism) official release, https://civitai.com/models/3666/protogen-x34-photorealism-official-release, 2022.
- Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- Hyperinverter: Improving stylegan inversion via hypernetwork. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11389–11398, 2022.
- Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021.
- Make-a-scene: Scene-based text-to-image generation with human priors. In European Conference on Computer Vision (ECCV), pages 89–106. Springer, 2022.
- An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022.
- Stylegan-nada: Clip-guided domain adaptation of image generators. ACM Transactions on Graphics (TOG), 41(4):1–13, 2022.
- Clip-adapter: Better vision-language models with feature adapters. arXiv preprint arXiv:2110.04544, 2021.
- Towards light-weight and real-time line segment detection. In Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
- Hypernetworks. In International Conference on Learning Representations, 2017.
- Heathen. Hypernetwork style training, a tiny guide, stable-diffusion-webui, https://github.com/automatic1111/stable-diffusion-webui/discussions/2670, 2022.
- Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Classifier-free diffusion guidance, 2022.
- Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799, 2019.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Composer: Creative and controllable image synthesis with composable conditions. 2023.
- Region-aware diffusion for zero-shot text-driven image editing. arXiv preprint arXiv:2302.11797, 2023.
- Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1125–1134, 2017.
- OneFormer: One Transformer to Rule Universal Image Segmentation. 2023.
- Progressive growing of gans for improved quality, stability, and variation. International Conference on Learning Representations, 2018.
- A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019.
- A style-based generator architecture for generative adversarial networks. IEEE Transactions on Pattern Analysis, 2021.
- Multi-level latent space structuring for generative control. arXiv preprint arXiv:2202.05910, 2022.
- Imagic: Text-based real image editing with diffusion models. arXiv preprint arXiv:2210.09276, 2022.
- Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2426–2435, 2022.
- Variational diffusion models. Advances in Neural Information Processing Systems, 34:21696–21707, 2021.
- Kurumuz. Novelai improvements on stable diffusion, https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac, 2022.
- Deep learning. Nature, 521(7553):436–444, May 2015.
- Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- Noise2noise: Learning image restoration without clean data. Proceedings of the 35th International Conference on Machine Learning, 2018.
- Measuring the intrinsic dimension of objective landscapes. International Conference on Learning Representations, 2018.
- Gligen: Open-set grounded text-to-image generation. 2023.
- Exploring plain vision transformer backbones for object detection. arXiv preprint arXiv:2203.16527, 2022.
- Benchmarking detection transfer learning with vision transformers. arXiv preprint arXiv:2111.11429, 2021.
- Piggyback: Adapting a single network to multiple tasks by learning to mask weights. In European Conference on Computer Vision (ECCV), pages 67–82, 2018.
- Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018.
- Sdedit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2021.
- Midjourney. https://www.midjourney.com/, 2023.
- Self-distilled stylegan: Towards generation from internet photos. In ACM SIGGRAPH 2022 Conference Proceedings, pages 1–9, 2022.
- T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453, 2023.
- GLIDE: towards photorealistic image generation and editing with text-guided diffusion models. CoRR, 2021.
- Glide: Towards photorealistic image generation and editing with text-guided diffusion models. 2022.
- Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- Mystyle: A personalized generative prior. arXiv preprint arXiv:2203.17272, 2022.
- ogkalu. Comic-diffusion v2, trained on 6 styles at once, https://huggingface.co/ogkalu/comic-diffusion, 2022.
- OpenAI. Dall-e-2, https://openai.com/product/dall-e-2, 2023.
- Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2337–2346, 2019.
- Zero-shot image-to-image translation. arXiv preprint arXiv:2302.03027, 2023.
- Styleclip: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2085–2094, October 2021.
- Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
- Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637, 2020.
- Efficient parametrization of multi-domain deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8119–8127, 2018.
- Encoding in style: a stylegan encoder for image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021.
- High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention MICCAI International Conference, pages 234–241, 2015.
- Incremental learning through deep adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(3):651–663, 2018.
- Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv preprint arXiv:2208.12242, 2022.
- Learning representations by back-propagating errors. Nature, 323(6088):533–536, Oct. 1986.
- Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 Conference Proceedings, SIGGRAPH ’22, New York, NY, USA, 2022. Association for Computing Machinery.
- Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022.
- LAION-5b: An open large-scale dataset for training next generation image-text models. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022.
- Overcoming catastrophic forgetting with hard attention to the task. In International Conference on Machine Learning, pages 4548–4557. PMLR, 2018.
- Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pages 2256–2265. PMLR, 2015.
- Stability. Stable diffusion v1.5 model card, https://huggingface.co/runwayml/stable-diffusion-v1-5, 2022.
- Stability. Stable diffusion v2 model card, stable-diffusion-2-depth, https://huggingface.co/stabilityai/stable-diffusion-2-depth, 2022.
- Bert and pals: Projected attention layers for efficient adaptation in multi-task learning. In International Conference on Machine Learning, pages 5986–5995, 2019.
- Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks. arXiv preprint arXiv:2112.06825, 2021.
- Plug-and-play diffusion features for text-driven image-to-image translation. arXiv preprint arXiv:2211.12572, 2022.
- Diode: A dense indoor and outdoor depth dataset. arXiv preprint arXiv:1908.00463, 2019.
- Sketch-guided text-to-image diffusion models. 2022.
- Pretraining is all you need for image-to-image translation. 2022.
- High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8798–8807, 2018.
- Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1395–1403, 2015.
- Side-tuning: Network adaptation via additive side networks. In European Conference on Computer Vision (ECCV), pages 698–714. Springer, 2020.
- Cross-domain correspondence learning for exemplar-based image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5143–5153, 2020.
- Tip-adapter: Training-free clip-adapter for better vision-language modeling. arXiv preprint arXiv:2111.03930, 2021.
- Zero initialization: Initializing residual networks with only zeros and ones. arXiv, 2021.
- Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 633–641, 2017.
- Cocosnet v2: Full-resolution correspondence learning for image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11465–11475, 2021.
- Unpaired image-to-image translation using cycle-consistent adversarial networks. In Computer Vision (ICCV), 2017 IEEE International Conference on, 2017.
- Toward multimodal image-to-image translation. Advances in Neural Information Processing Systems, 30, 2017.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.