- The paper presents an automated approach using few-shot prompting to invert code models and expose security vulnerabilities.
- It employs FS-Code, FS-Prompt, and OS-Prompt strategies to simulate insecure code generation and evaluate diverse sampling outputs.
- The created CodeLMSec benchmark systematically assesses and ranks code language models based on their propensity to generate vulnerable code.
CodeLMSec Benchmark: Evaluating Vulnerabilities in Code LLMs
The paper "CodeLMSec Benchmark: Systematically Evaluating and Finding Security Vulnerabilities in Black-Box Code LLMs" addresses the critical issue of security vulnerabilities in code generated by LLMs. With the increasing reliance on tools like GitHub Copilot for AI-assisted programming, understanding the security implications of automatically generated code becomes essential.
Introduction to CodeLMSec
The research highlights the challenges posed by unsanitized data used in training LLMs, which often incorporates security vulnerabilities present in open-source repositories. The lack of comprehensive studies on the security aspect of LLM-generated code underscores the need for systematic approaches to evaluate these models beyond functional correctness.
Methodology: Model Inversion and Few-Shot Prompting
The core contribution of this study is an automated approach that approximates the inverse of black-box models using few-shot prompting to discover security vulnerabilities. This method involves:
- Model Inversion: The process is visualized as approximating the inverse of code generation models to predict prompts that result in vulnerabilities.
- Few-Shot Learning: By leveraging a few examples of known vulnerable code (Figure 1), the model is guided to generate similar scenarios that exploit the same vulnerabilities.
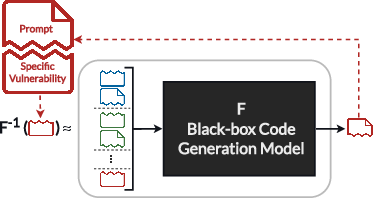
Figure 1: We systematically find vulnerabilities and associated prompts by approximating the inverse of black-box code generation model F.

Figure 2: Overview of our proposed approach to automatically finding security vulnerability issues of the code generation models.
Implementation Strategy
The implementation involves three strategies: FS-Code, FS-Prompt, and OS-Prompt. FS-Code combines code examples with vulnerabilities, leading to these primary outcomes:
- Non-Secure Prompt Generation: Using few-shot examples that include vulnerabilities, the model generates prompts conducive to creating insecure code.
- Sampling Techniques: Strategies like nucleus sampling are employed to diversify output and explore the model's potential for generating vulnerable code across various sampling temperatures (Figure 3).
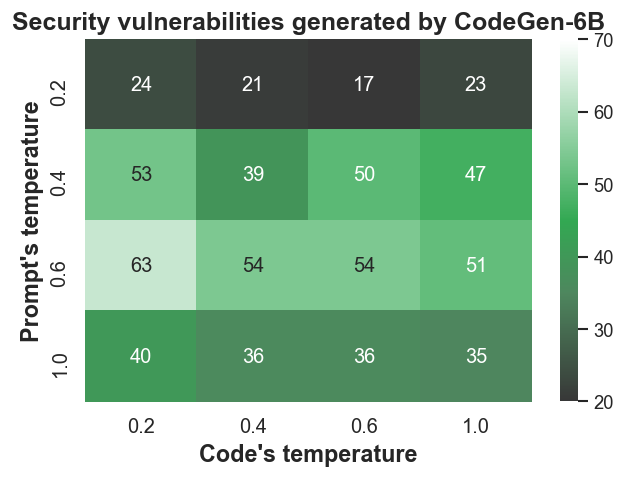
Figure 3: Number of discovered vulnerable Python codes using different sampling temperatures.
Evaluation and Results
The paper presents extensive evaluations comparing vulnerabilities discovered across different CWEs in Python and C code. Notably, FS-Code and FS-Prompt exhibit substantial efficacy in generating code that mirrors the weaknesses present in the few-shot examples (Figure 4).
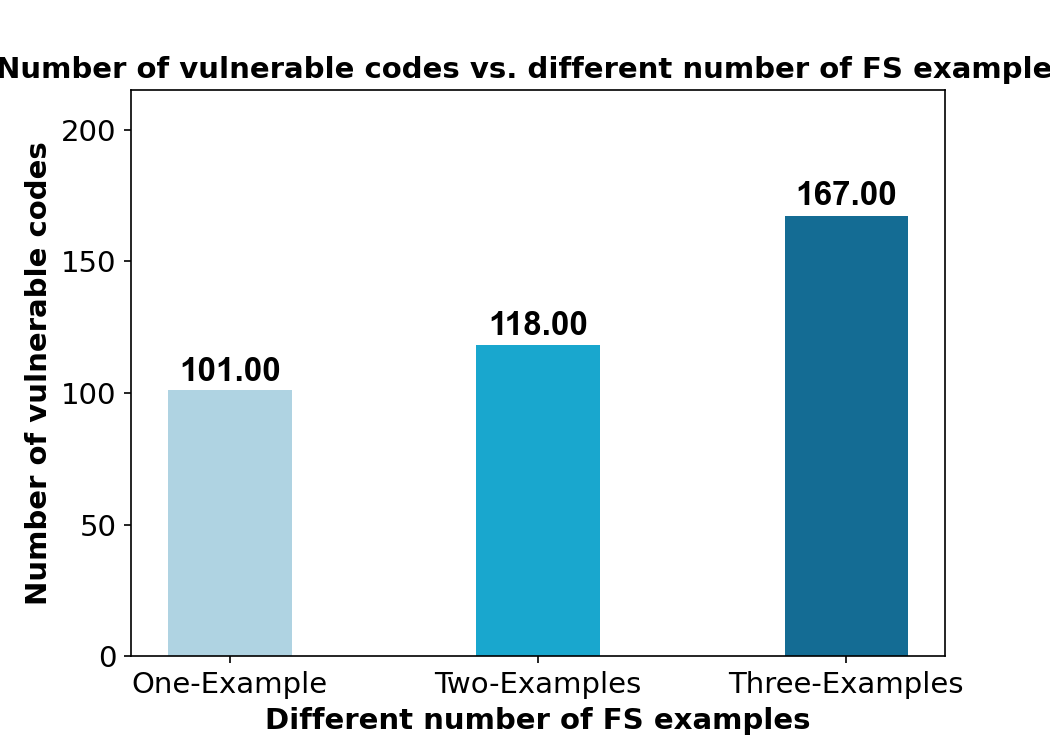
Figure 4: Number of discovered vulnerable Python codes using a different number of few-shot examples.
Benchmarking and Future Implications
A key outcome of this research is the creation of the CodeLMS benchmark dataset, designed to systematically assess and rank code models based on their propensity to output vulnerable code. This benchmark allows for the evaluation of current and future model versions, promoting continuous improvements in secure code generation practices.
Discussion
While demonstrating the scalability and effectiveness of their approach, the authors acknowledge limitations such as reliance on static analysis tools like CodeQL, which may not capture all potential vulnerabilities. Furthermore, this work lays the groundwork for future explorations into enhancing model reliability, potentially influencing model training methods to mitigate security risks.
Conclusion
This research provides a vital foundation for systematically evaluating security vulnerabilities in LLMs for code generation. By introducing methodologies for discovering vulnerabilities and establishing benchmarks, it sets a precedent for future endeavors to refine model outputs and enhance security in automatically generated code. The release of the CodeLMSec dataset provides a practical tool for developers and researchers to diagnose, compare, and improve the security integrity of code LLMs.