- The paper introduces Colossal-Auto, a novel system that integrates pipeline and tensor parallelism with activation checkpointing for efficient large-model training.
- It employs a symbolic profiler and a two-stage hierarchical solver to optimize distributed execution and memory usage with minimal user intervention.
- Evaluations on NVIDIA A100 GPUs show superior throughput and reduced bottlenecks, making large-scale model training more accessible.
Colossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models
Colossal-Auto addresses the computational challenges related to training and optimizing large-scale models, integrating techniques such as pipeline parallelism, tensor parallelism, and activation checkpointing. This paper introduces a system designed to jointly optimize distributed execution and gradient checkpointing plans efficiently, providing a theoretical framework and practical implementation to automate these processes seamlessly with minimal code alteration.
Background and Challenges
Large models, characterized by their impressive performance across domains, demand extensive computational resources that often exceed the capacity of typical hardware configurations like GPUs. Currently, distributed training systems employ various strategies, including data, pipeline, and tensor parallelism, to mitigate these limitations. However, these methods are intrinsically complex, requiring expert-driven execution plans that address diverse hardware setups and configuration-specific constraints.
The paper highlights the difficulties in efficiently unifying intra-op parallelism due to variable sharding specifications and complex communication patterns among devices, especially when considering novel hardware topologies. Current solutions such as Alpa and FlexFlow, while offering parallelism, neglect activation checkpoint integration, leading to potential inefficiencies in memory use and computation time.
System Design
Colossal-Auto proposes a three-part design: a symbolic profiler, a hierarchical solver, and a code generation module.
- Symbolic Profiler: It estimates computing and memory costs by leveraging PyTorch's FX module for static graph analysis, enabling low-cost profiling. This profiler accurately predicts resource demands by tracing out operations symbolically rather than executing them, providing meta-data that informs the optimization algorithms.
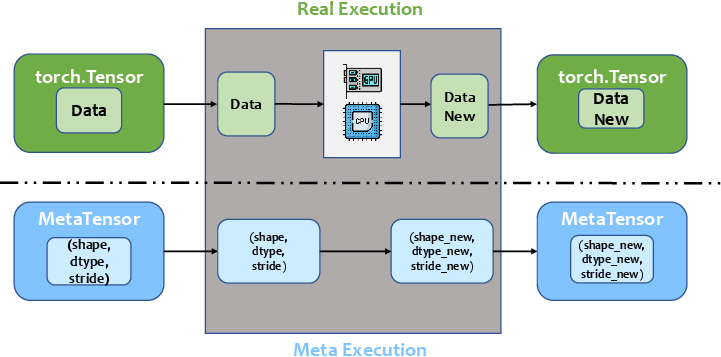
Figure 1: Symbolic execution used by Colossal-Auto to estimate computational and memory costs.
- Two-Stage Solver: The hierarchical solver implements a two-level strategy: intra-op parallelism followed by activation checkpointing.
- The intra-op parallel solver modifies sharding strategies using an ILP optimizer, limiting devices to realistic configurations, thus optimizing execution plans per hardware topology.
- Activation checkpointing solver adapts techniques from existing research but includes communication overhead modeling, optimizing memory without extending execution time unnecessarily.
This hierarchical search effectively mitigates the exponential complexity of unified plans, enabling more practical deployment in clusters with heterogeneous configurations.
Integration and Automation
Colossal-Auto automates model transformation with minimal user intervention. It compiles the refined computation graph into executable PyTorch models, embedding strategies into runtime operations like gradient synchronization and bespoke memory management modules drawn from frameworks such as ZeRO-Offload. This automation is crucial in democratizing large-model training, allowing users to sidestep manual tuning of execution plans.
Evaluation and Implications
Comparison with contemporary systems demonstrates Colossal-Auto's competitive performance in practical scenarios, accentuated by its adaptive communication pattern strategies that align with device capabilities. Through benchmarks on configurations with variable hardware connectivity (NVIDIA A100 GPUs), Colossal-Auto achieves superior throughput, leveraging inter-device communication aware execution plans to minimize bottlenecks.
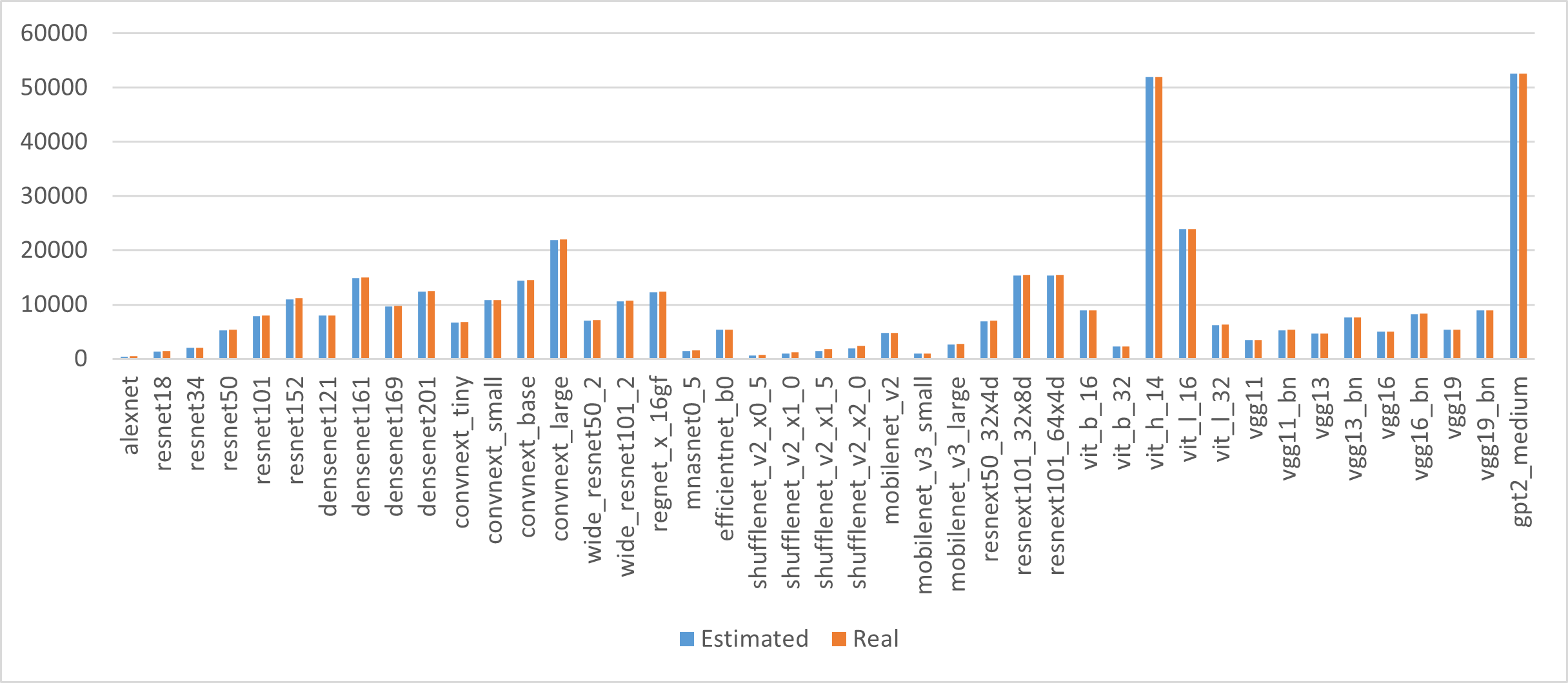
Figure 2: Evaluation of symbolic memory profiling accuracy against real execution values for various models.
The implications are profound for AI practitioners seeking to scale models without extensive hardware-specific code modification. By automating both memory and processing distribution, Colossal-Auto bridges the gap between theoretical efficiency and practical applicability, enabling broader accessibility to cutting-edge model training methods.
Conclusion
Colossal-Auto exemplifies a sophisticated integration of memory optimization and distributed parallel strategy into a coherent automated system, significantly reducing the manual overhead traditionally required for large-scale model training. Future work should focus on refining inter-op parallelism and extending device mesh flexibility, ensuring broader applicability across diverse hardware ecosystems. The system's public availability through ColossalAI further underscores its role as a critical facilitator of large-model training democratization.