- The paper presents a novel framework that leverages LLMs and detailed prompt engineering to detect and repair hardware security bugs in Verilog HDL.
- It employs a multi-component methodology—combining static analysis, repair generation, and simulation-based evaluation—to validate functional and security compliance.
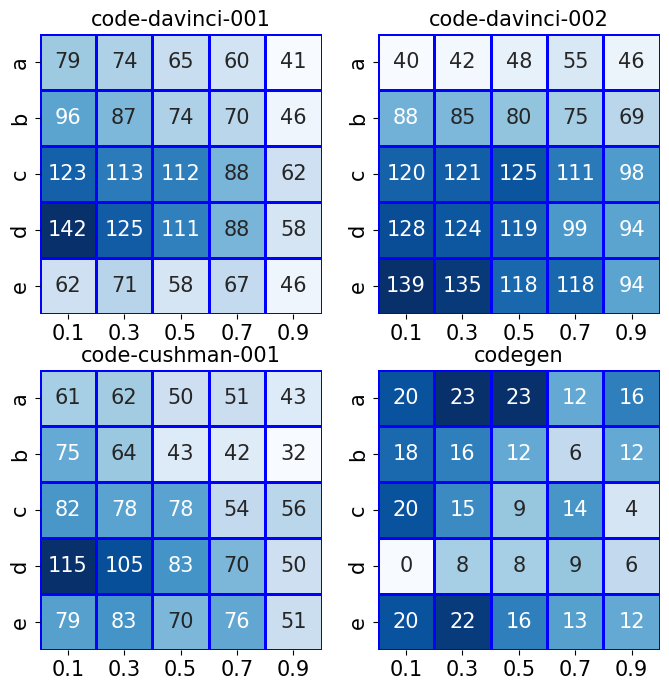
- Experimental results show that robust models like code-davinci at lower temperature settings yield consistent and accurate repairs, outperforming traditional tools such as CirFix.
Fixing Hardware Security Bugs with LLMs
Recent advancements in AI-based tools have enabled innovative applications in various domains, including automated bug fixing in software. The paper "Fixing Hardware Security Bugs with LLMs" explores utilizing LLMs for detecting and repairing security-related bugs in hardware designs, specifically focusing on Verilog HDL. The paper provides both theoretical insights and practical applications of LLMs in the field of hardware bug repair.
Approach and Framework
The core approach utilized in the study involves constructing a specialized framework that assesses the performance of any LLM aimed at fixing specified hardware security bugs. The framework consists of four main components:
- Sources: This involves gathering a set of domain-representative hardware security bugs from various systems, such as Verilog files demonstrating both bugs and their functional behavior.
- Detector: A static analysis tool used primarily to detect bugs and classify them using CWEs. This tool is essential for automating the bug identification process.
- Repair Generator: This is the essence of using LLMs; the flawed code is presented to the LLM with instructions, and repair suggestions are generated.
- Evaluator: This component uses simulation tools (like ModelSim in this study) to verify the correctness of LLM-generated repairs through functional and security evaluations.
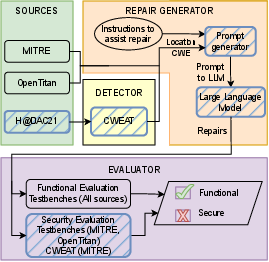
Figure 1: Overview of the framework used in our experiments It is broken down into 4 main components. Sources are the designs containing bugs. Detector localizes the bug (for bugs 8-10). Repair generator contains the LLM which generates the repairs. Evaluator verifies the success of the repair.
Implementation Details
Prompt Engineering
Prompt engineering is crucial when using LLMs for hardware bug repair. Variations in the instruction sets (prompts) significantly impact the success rate of bug repairs. The study experimented with five instruction variations from minimal assistance ("no instructions") to detailed bug-fixing guidance expressed in pseudo-code.
Model and Temperature Variations
The experiments used multiple models, including OpenAI's code-davinci and code-cushman, as well as the open-source CodeGen model. Temperature settings were tested across a range from 0.1 to 0.9, impacting the determinism and creativity of the generated repairs.
Evaluation Metrics
Repairs were assessed based on two primary criteria:
Experimental Results and Findings
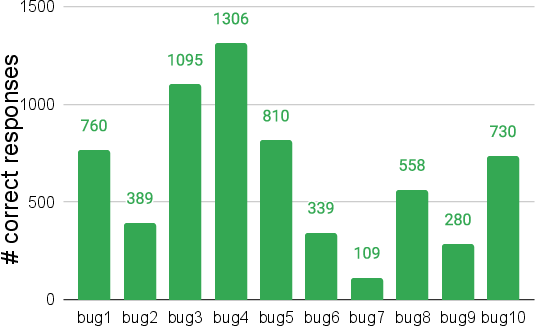
The study demonstrated that LLMs could effectively repair hardware security bugs, achieving varying degrees of success dependent on the choice of LLM, instruction variation, and temperature. Some key findings include:
Conclusion
The paper demonstrates that LLMs hold significant potential in automatically repairing hardware security bugs, complementing existing techniques. The framework and methodologies presented provide a basis for further exploration in hardware security and AI-based bug fixing. Future work is expected to improve upon the localization of bugs and refine LLM-based methodologies to ensure higher efficiency and broader practical applications in the semiconductor industry.