- The paper introduces a novel detection method that exploits probability curvature differences, using random perturbations to differentiate machine-generated text from human-written text.
- It computes log probability discrepancies from minor text perturbations, achieving significant AUROC improvements over baseline zero-shot approaches.
- Empirical results on models like GPT-2, GPT-Neo, and GPT-J demonstrate DetectGPT's robustness and efficiency in real-world authenticity verification.
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature (arXiv (2301.11305))
Introduction
The paper introduces DetectGPT, a model leveraging curvature-based criteria for differentiating machine-generated text from human-written content. Distinctively, it operates without the need for additional classifiers or datasets, focusing purely on the log probability distributions of LLM outputs. Central to the method is the observation that text generated by LLMs tends to reside in negative curvature regions of the model's log probability function, an insight that DetectGPT exploits using random perturbations.
Curvature of Log Probability Function
DetectGPT's foundation lies in the hypothesis that machine-generated text, when subjected to minor perturbations, shows a significant decrease in log probability in comparison to the original text. This is contrasted with human-written text, whose perturbations do not exhibit such systematic behavior. The model relies on the local structure surrounding candidate passages, utilizing a perturbation function to approximate the trace of the log probability's Hessian.
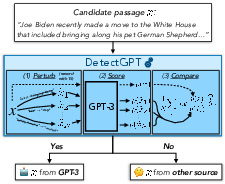
Figure 1: We determine if a text was generated by an LLM by averaging log probability ratios of original and perturbed samples.
DetectGPT Algorithm
The algorithm computes perturbation discrepancies by averaging log probabilities of perturbed samples from another LLM. If this discrepancy is sufficiently large, it indicates machine-generated text. DetectGPT is thus able to perform zero-shot detection profoundly more effectively than baseline methods, improving the AUROC significantly over existing techniques.
Empirical Validation
The authors substantiate their claims through rigorous experiments across multiple datasets and LLMs like GPT-2, GPT-Neo, and GPT-J. DetectGPT outperforms these models' zero-shot detection mechanisms, achieving higher AUROC scores and maintaining robustness even when applied to large models like GPT-3.
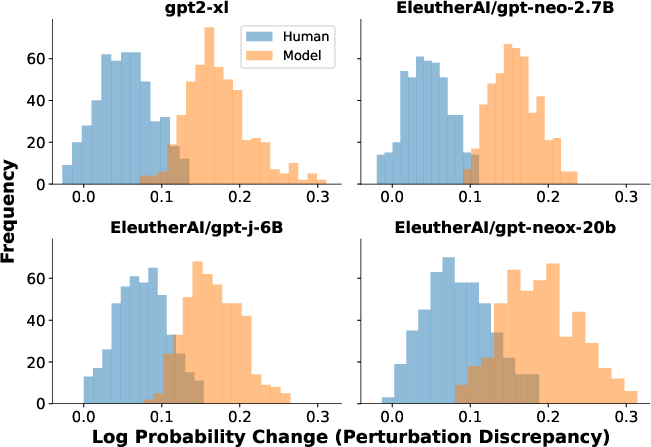
Figure 2: Distributions of perturbation discrepancies are consistently higher for model-generated texts than for human texts, indicating a detectable characteristic.
DetectGPT showcases enhanced detection capabilities over supervised detectors, particularly in out-of-domain scenarios, underscoring its practicality in varied real-world applications. The paper discusses the trade-off between detection accuracy and computational efficiency, addressing potential costs by optimizing the number of perturbations used.
Discussion and Future Work
The research highlights its potential in conjunction with watermarking techniques for increasing the robustness of detection. Future directions include exploring detection mechanisms across non-textual generative models, such as those producing multimedia content.
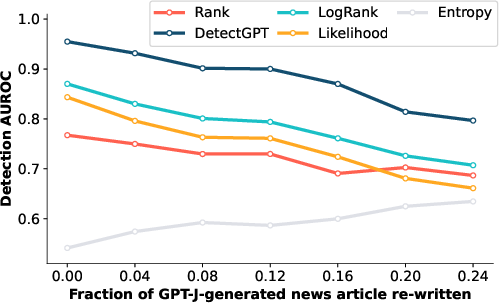
Figure 3: Performance degradation of top methods under increased revisions, where DetectGPT robustly maintains accuracy.
Conclusion
DetectGPT offers a novel and efficient approach to machine-generated text detection, using insights from probability functions without relying on additional training data or models. It sets a foundation for further exploration into generative model behavior, promising significant impact across domains reliant on authenticity verification.
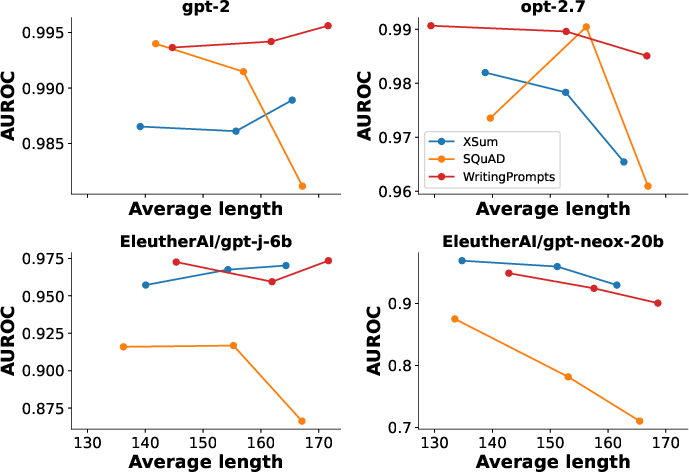
Figure 4: Illustration of DetectGPT's architecture and its procedural flow.