- The paper presents a comprehensive taxonomy of SSL methods, categorizing context-based, contrastive, and generative approaches.
- It demonstrates that contrastive methods yield high linear probe performance while masked image modeling excels in transfer tasks.
- The survey identifies open challenges including theoretical frameworks, automatic pretext optimization, and unified multimodal SSL.
A Comprehensive Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends
Introduction: Motivation and Context of Self-supervised Learning
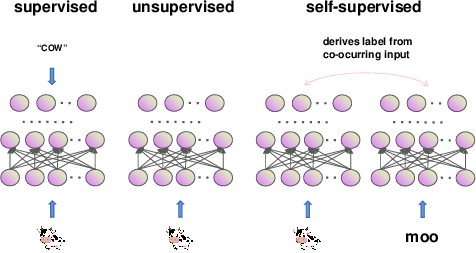
Self-supervised learning (SSL) is presented as a robust alternative to supervised learning, motivated by the enormous cost and impracticality of obtaining large labeled datasets in real-world scenarios. SSL leverages pretext tasks—auxiliary objectives constructed from unlabeled data—to enable representation learning without manual annotations. This framework exploits the structural properties and relationships inherent in the data to produce pseudo-labels for pre-training, with the learned representations subsequently fine-tuned for downstream tasks.
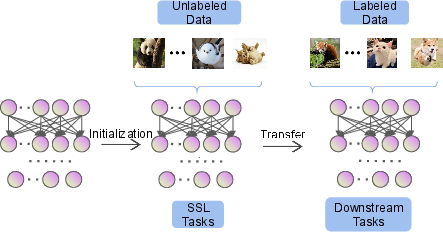
Figure 1: The overall framework of SSL.
The exponential increase in SSL research output underlines the centrality of the field to the progression of deep learning. The number of related publications has rapidly accelerated, highlighting the community's prioritization of SSL-based techniques for fundamental advances in both computer vision (CV) and NLP.
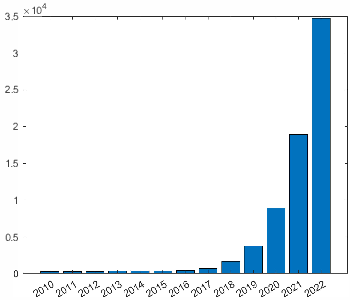
Figure 2: Number of SSL publications per year indicates rapid growth and continued interest in the field.
Taxonomy and Key Algorithms in Self-supervised Learning
The survey categorizes SSL approaches based on the design of pretext tasks and the mathematical properties of their learning signals. The principal methodologies are as follows:
Context-based Pretext Tasks
Canonical context-based tasks include geometric prediction (rotation), spatial arrangement (jigsaw puzzles), and channel reconstruction (colorization). Each task enforces unique constraints on the learned representations, promoting invariance to specific data transformations or dependencies.

Figure 4: Examples of context-based pretext tasks: rotation (geometric context), jigsaw (spatial context), and colorization (channel context).
Contrastive Learning (CL) Approaches
Contrastive learning, epitomized by MoCo and SimCLR, relies on instance discrimination through augmentations, maintaining a queue or large batch for negative samples. Recent methods, including BYOL and SimSiam, demonstrate that strong representation learning is possible even in the absence of explicit negative pairs, by leveraging projection heads, stop-gradient tricks, and architectural symmetries.
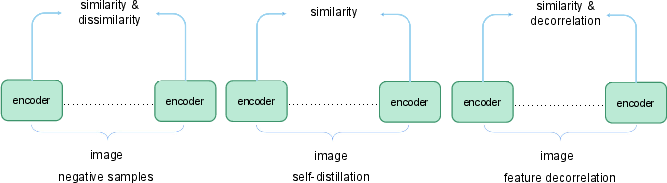
Figure 5: Taxonomy of CL methods: standard negative mining (left), self-distillation (center), and feature decorrelation (right).
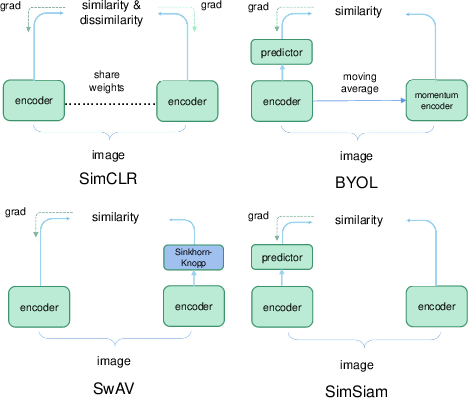
Figure 6: Key Siamese architectures in CL: encoder cooperation enables diverse negative/positive strategies.
Masked Image Modeling (MIM) and Generative Algorithms
Recent advances in MIM, such as BEiT, MAE, CAE, and SimMIM, represent a paradigm shift. These methods mask a subset of the input and train the model to reconstruct either raw pixels or tokenized patches, with variants differing in target definition and architectural coupling between encoder and decoder. BEiT leverages tokenization inspired by NLP, whereas MAE directly regresses pixel values without a tokenizer.
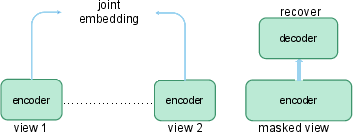
Figure 7: Comparing the pipelines of CL and MIM methods—highlighting information flow and reconstruction targets.
Representative Pretext Tasks

Figure 8: Notable SSL pretext tasks spanning context-based, contrastive, and generative setups.
Integration with Other Learning Paradigms
The survey underscores the modularity and utility of SSL for enhancing and complementing other learning paradigms:
- GANs: Embedding self-supervision within GANs (e.g., SS-GAN) facilitates improved discrimination and generation.
- Semi-supervised Learning: SSL objectives supplement labeled-data losses for regularization (as in S4L), bolstering performance in low-label regimens.
- Multi-modal and Multi-view Learning: SSL is a natural fit for multi-sensory settings, promoting cross-modal consistency via synchronized pretext tasks.
Applications Across Modalities
- Computer Vision: State-of-the-art SSL approaches yield transferable features for classification, detection, segmentation, and re-identification tasks; SSL for video is enhanced by modeling temporal order, speed, and multi-modal synchronization.
- Natural Language Processing: SSL underpins foundational models such as BERT and GPT; masked token prediction, autoregression, and other pretext tasks underpin rapid advances in bidirectional and generative language modeling.
- Medical Imaging & Remote Sensing: SSL addresses the critical bottleneck of sparse labels by leveraging domain-specific pretext tasks, shown to yield robust representations in segmentation, detection, and change tracking.
The survey presents strong empirical evidence that:
- CL-based SSL methods generally attain superior linear probe performance (for classification), due to well-clustered latent features.
- MIM approaches, when fine-tuned, surpass contrastive methods on transfer tasks, notably in object detection and segmentation. This robustness is credited to MIM's reduced propensity to overfit and effective use of architectural inductive biases.
- CL methods are resource-intensive, often requiring momentum encoders, memory queues, and large batch mining, which limits scalability relative to the inherent parallelism of MIM-style training.
Open Problems and Future Trends
Theoretical Advances
The survey notes the lag in theory relative to the empirical proliferation of SSL. The collapse avoidance in non-contrastive methods (BYOL, SimSiam) and the comparative superiority of MIM over CL in certain settings merit rigorous theoretical elucidation.
Automatic Pretext Optimization
Automating the selection and composition of pretext tasks, tailored to maximize transfer learning performance for downstream applications, remains formally unresolved. The field warrants further study in data-driven or meta-learning-based task design.
Towards Unified Multimodal SSL
A compelling research trajectory is the construction of unified SSL paradigms that span modalities, architectures, and data types—particularly via transformer backbones, with the potential to yield cross-domain, foundation models scalable to vision, language, and beyond.
Scaling Laws and Data Utilization
While SSL in principle can exploit limitless unlabeled data, identifying regimes and architectures that consistently benefit from data scaling is nontrivial. The data efficiency and scaling behavior mismatch between generative and contrastive approaches remains to be systematized and theoretically explained.
Failure Modes and Guidance for Practitioners
The field increasingly recognizes that more unlabeled data is not universally beneficial, especially in semi-supervised settings or under distributional mismatch. Developing diagnostics and recommendations for algorithm selection, based on problem statistics and failure mode analysis, constitutes an actionable research agenda.
Conclusion
This survey establishes a rigorous taxonomy and critical synthesis of self-supervised learning algorithms, with detailed coverage of architectural strategies, integration with other machine learning paradigms, and the breadth of real-world applications. Key numerical findings include the superior linear probe results of contrastive approaches and the robust fine-tuning performance of masked image modeling methods, challenging prior assumptions about task-agnostic transferability. The work highlights open theoretical questions, the necessity for automatic and multimodal pretext engineering, and the nuanced relationship between data scaling and SSL performance. Self-supervised learning is poised to continue serving both as a theoretical frontier and a practical engine for progress across modalities and domains in AI.