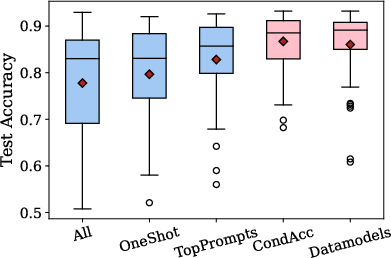
- The paper shows that data curation using CONDACC and DATAMODELS significantly reduces performance variance and enhances accuracy in in-context learning.
- It introduces efficient subset selection methods that achieve average accuracy improvements of 7.7% and 6.3% over baselines on multiple classification tasks.
- The study reveals that stable prompt examples are task-specific and effective even when traditional indicators like diversity and perplexity are not predictive.
Data Curation for Stable In-Context Learning: Methods, Analysis, and Implications
Introduction
This paper addresses the instability of in-context learning (ICL) in LLMs with respect to the choice of training examples used as prompts. The authors demonstrate that careful data curation—specifically, selecting a stable subset of training examples—can significantly reduce performance variance and improve average accuracy in ICL, without modifying the underlying model or prompt retrieval/calibration strategies. Two methods for subset selection are introduced: CONDACC, which scores examples by their average conditional accuracy, and DATAMODELS, which uses linear regression to estimate the influence of each example on model outputs. The work provides a comprehensive empirical evaluation across multiple tasks and models, and offers a detailed analysis of the properties of stable subsets.
Methods for Stable Subset Selection
The core contribution is the development of two data valuation methods for identifying stable training subsets:
- CONDACC: For each training example, compute the expected ICL accuracy on a dev set, conditioned on the example's presence in randomly sampled prompts. This is closely related to Data Shapley values, but adapted for the K-shot ICL setting.
- DATAMODELS: Fit a linear model to predict the LLM's output margin for each dev example, using as features the presence and position of each training example in the prompt. The score for each example is the number of positive weights across all dev examples and positions, reflecting its beneficial influence.
Both methods require constructing a large set of prompts (DICL) and running ICL inference multiple times to gather prompt-performance statistics. The highest-scoring examples per class are selected to form the stable subset.
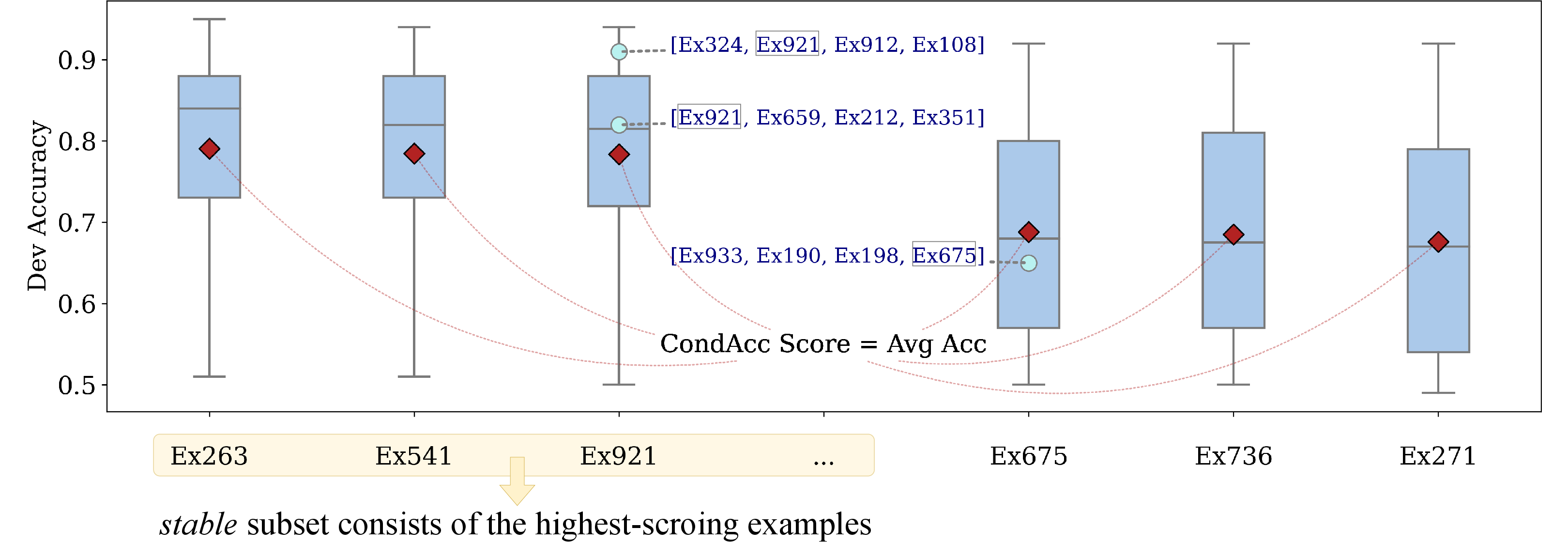
Figure 1: Overview of the CONDACC method, which scores training examples by their average dev-set accuracy when combined with random others.
Empirical Results
Experiments are conducted on five classification tasks (SST-2, BoolQ, Subj, Scicite, AGNews) and four LLMs (GPTJ-6B, OPT-13B, GPT-Neo-2.7B, OPT-6.7B). The main findings are:
Analysis of Stable Subsets
The paper provides a detailed analysis of the properties of stable subsets:
- Sequence Length and Perplexity: Good examples are not outliers in length or perplexity. There is little to no correlation between these factors and ICL performance, contradicting prior work that emphasized their importance.

Figure 3: Accuracy versus sequence length (left) and perplexity (right) for training examples. Good examples are not characterized by extreme values.
- Diversity: Contrary to previous findings, stable subsets are not more diverse (in raw text or embedding space) than random subsets. In fact, both CONDACC and DATAMODELS tend to select tightly clustered examples in embedding space.
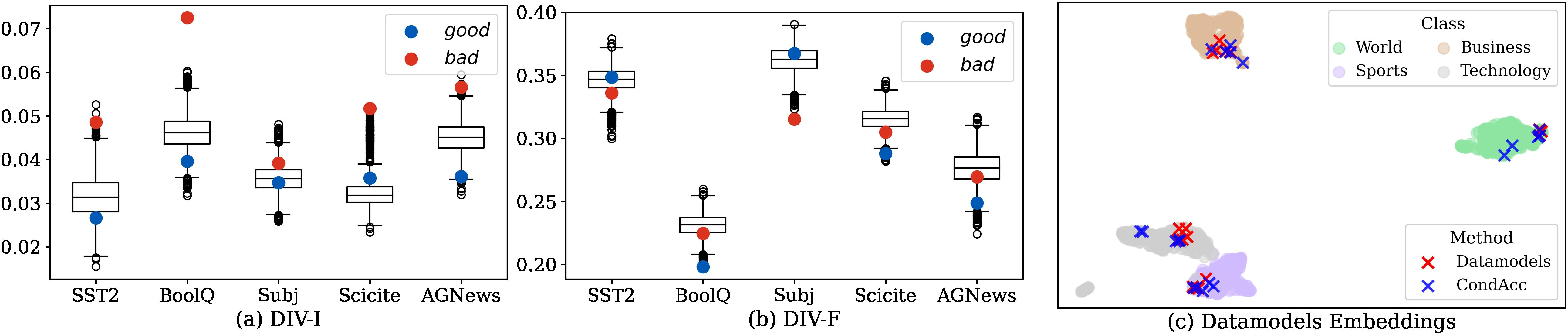
Figure 4: Diversity analysis of good, bad, and random subsets. Good subsets are not more diverse than random ones; selected examples cluster in embedding space.
- Transferability Across Models: There is limited overlap in stable subsets identified by different LLMs, but a small number of shared examples can yield high accuracy across models, suggesting the existence of universally stable examples.
Implementation Considerations
- Computational Cost: Both methods require extensive inference to collect prompt-performance statistics (e.g., 50,000 prompts per setup), resulting in high GPU hours (500+ for the largest models/tasks). The DATAMODELS method is computationally efficient once statistics are collected.
- Scalability: The approach is feasible for moderate-sized LLMs (up to 13B parameters) and classification tasks. Scaling to larger models or generative tasks would require further optimization, such as more efficient search or sampling strategies.
- Practical Deployment: The methods are model-agnostic and do not require access to model parameters, making them suitable for API-based LLMs. The curated subsets can be reused across test examples, avoiding the need for instance-dependent prompt retrieval.
Theoretical and Practical Implications
- Data Curation as a Key Factor: The results challenge the prevailing focus on prompt engineering and retrieval, showing that data curation alone can yield stable and high-performing ICL.
- Reevaluation of Diversity and Perplexity: The lack of correlation between diversity/perplexity and ICL performance suggests that prior heuristics for prompt selection may be suboptimal in the fixed-prompt regime.
- Task-Level Example Selection: The ability to construct stable subsets that generalize to OOD tasks and work with single-label prompts indicates that certain examples encode robust task definitions, which may inform future work on dataset design and synthetic example generation.
Future Directions
- Reducing Computational Overhead: Developing more efficient subset selection algorithms, possibly leveraging active learning or search-based approaches, is necessary for scaling to larger models and datasets.
- Extension to Generative Tasks: The current study is limited to classification; extending the analysis to generation and structured prediction tasks is an open problem.
- Understanding Universally Stable Examples: Further investigation into the properties of examples that are stable across models and tasks could inform the construction of benchmark datasets and the design of more robust ICL pipelines.
- Applicability to Gigantic LLMs: The findings may not directly transfer to models with >100B parameters due to emergent behaviors; empirical validation in this regime is needed.
Conclusion
This work demonstrates that careful data curation—via the CONDACC and DATAMODELS methods—can substantially stabilize and improve in-context learning in LLMs, independent of prompt retrieval or calibration. The findings call into question the necessity of diversity and low perplexity in prompt selection, and highlight the importance of identifying task-level stable examples. While computationally intensive, the approach is practical for moderate-scale models and provides a foundation for future research on efficient, robust ICL. The implications extend to dataset design, prompt engineering, and the broader understanding of data influence in LLMs.