- The paper demonstrates that standard MT metrics do not correlate strongly with extrinsic task success at the segment level.
- The study applies a Translate-Test setup across semantic parsing, question answering, and dialogue state tracking to robustly assess metric efficacy.
- The paper recommends transitioning from numerical scores to error-focused labeling and diverse training data to enhance MT evaluation.
Extrinsic Evaluation of Machine Translation Metrics
Introduction
The paper "Extrinsic Evaluation of Machine Translation Metrics" investigates the efficacy of automatic machine translation (MT) metrics in detecting the segment-level quality of translations. These metrics have traditionally been used to evaluate translation quality at the system level, but their ability to assess individual sentence translations remains ambiguous. This study correlates MT metrics with outcomes from downstream tasks, including dialogue state tracking, question answering, and semantic parsing, to measure their utility in practical applications.
Methodology
The methodology involves the Translate-Test setup, where translations of test language sentences to the task language are evaluated for downstream tasks.
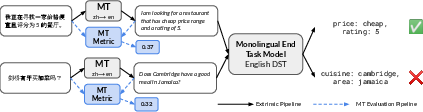
Figure 1: The meta-evaluation pipeline. The predictions for the extrinsic task in the test language (Chinese, ZH) are obtained using the Translate-Test setup --- the test language is translated into the task language (English, EN) before passing to the task-specific model.
Tasks Evaluated
- Semantic Parsing (SP): Uses logical forms to transform natural language into machine-readable formats, evaluated using exact-match denotation accuracy.
- Extractive Question Answering (QA): Predicts word spans from a paragraph to answer questions, with performance measured by Exact-Match metrics.
- Dialogue State Tracking (DST): Maps user intents in conversations to predefined slots, tested with Joint Goal Accuracy.
After translations are processed by task-specific models, MT metrics assess whether translations contribute to downstream task success or failure.
Results
The study finds minimal correlation between MT metrics scores and success in extrinsic tasks, indicating that current metrics are not reliable at the segment level.
Case Study
A focused analysis on the semantic parsing task with Chinese inputs illustrates the limitations of MT metrics, using COMET-DA scores to categorize correct versus incorrect parses.
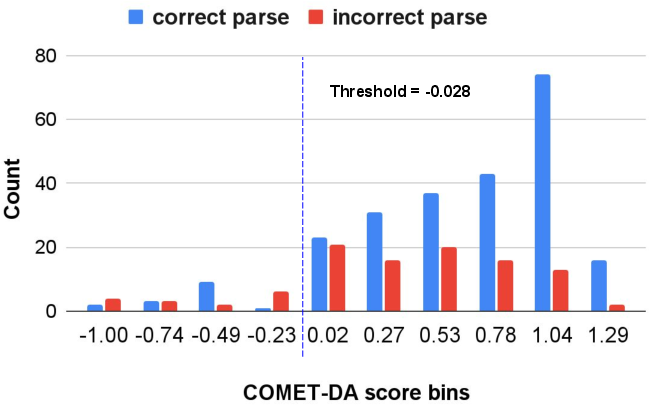
Figure 2: Graph of predictions by COMET-DA (threshold: -0.028), categorized by the metric scores in ten intervals. Task: Semantic Parsing with English parser and test language is Chinese.
Analysis and Recommendations
The paper proposes recommendations for improving MT metrics:
- MQM for Human Evaluation: Suggests leveraging Multidimensional Quality Metrics for marking explicit translation errors to refine metric accuracy.
- Labels vs Scores: Advocates for segment-level evaluation metrics that predict error types rather than relying on ambiguous numerical scores.
- Diverse Training Data: Recommends including varied references during training to improve the robustness of metrics against paraphrases.
Conclusion
The study provides insight into the limitations of current MT metrics in assessing translation quality at the segment level. Recommendations focus on enhancing MT evaluation by transitioning from score-based assessments to error-focused labeling. Future developments should address the diverse error sensitivities of extrinsic tasks to improve MT systems' efficacy in real-world applications.
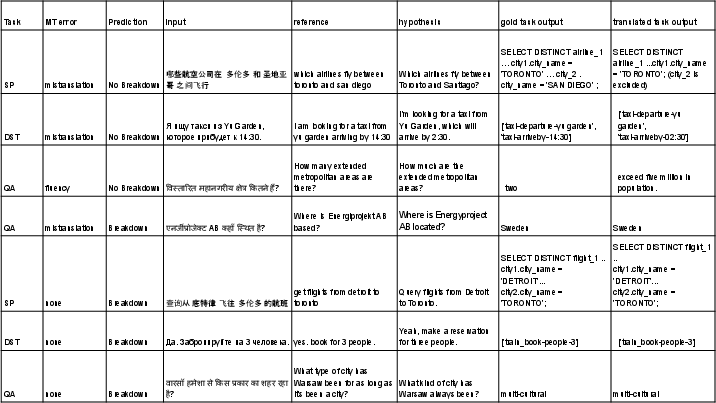
Figure 3: Examples of errors made by COMET-DA.
The findings emphasize a need for more sophisticated approaches to evaluate MT translations, intending to bridge the gap between intrinsic metric performance and extrinsic task success.