- The paper demonstrates a method to quantify and control the Big Five traits in LMs using adapted personality questionnaires.
- It uses context manipulations, including item-level and Reddit-based inputs, to modify trait scores with high Pearson correlations.
- Findings reveal biases in pretrained models and suggest pathways for bias-aware, personalized dialog systems.
Identifying and Manipulating the Personality Traits of LLMs
The paper "Identifying and Manipulating the Personality Traits of LLMs" presents a systematic study on measuring, analyzing, and controlling perceived personality traits of LMs, specifically focusing on the Big Five personality taxonomy. By exploring how LMs such as BERT and GPT-2 exhibit and modify these traits, the research aims to enhance applications in dialog systems, ensuring smoother human-AI interactions and identifying potential biases stemming from training data.
Introduction and Motivation
The rise of AI systems such as Alexa and Siri and their integration into daily life has led to a pressing need to understand their underlying behaviors, including perceived personality traits. Ensuring that these systems can be tailored to user personalities or specific application needs, such as non-reinforcing responses in clinical settings, is critical. This work investigates the extent to which LMs exhibit consistent personality traits, assessing how context influences these traits, and examining potential for trait manipulation to ensure beneficial interactions.

Figure 1: We explore measuring and manipulating personality traits in LLMs. The top frame shows how openness might be expressed, and the bottom frame shows influence via additional context.
Methodology
The study employs a modified Big Five questionnaire to evaluate personality traits in BERT and GPT-2 using sentence completion tasks. Each item in the questionnaire is adapted to fit the prediction capabilities of LMs through masked or probabilistic context completion, thus assessing traits like extroversion and openness. Personality scores are derived by summing responses to trait-related questions, aligning them with human percentile equivalents for contextual comparability.
Base Model Evaluation
Initial evaluations without context manipulation reveal that base model scores of BERT and GPT-2 inhabit typical human personality ranges, implying that pretraining data mirrors real-world personality distributions. However, there exist notable deviations suggestive of inherent biases, such as BERT’s lower openness percentile and GPT-2’s higher emotional stability percentile.
Manipulating Personality Traits with Contexts
Item Context
Item responses from the Big Five assessment were used as context to manipulate model personality traits predictably. Correlations were found between expected and observed traits, with conscientiousness and emotional stability showing high predictability (median Pearson correlations of 0.84 and 0.81 for BERT and GPT-2).
Reddit Context
To qualitatively assess personality shifts, Reddit responses describing user personalities were utilized as context. Logistic regression indicated qualitative alignment of trait shifts with human intuition—certain words indicative of extroversion, agreeableness, etc., effectively modified trait scores significantly.
Psychometric Survey Data
Analysis with crowd-sourced personality descriptions, both directed and undirected, uncovered moderate to strong correlations between survey context-based predictions and actual human Big Five scores, up to 0.48 for specific datasets, highlighting potential for LMs to predict personality traits using free-text descriptions.
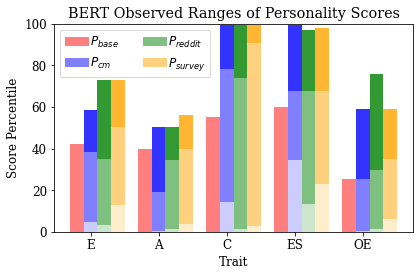
Figure 2: Observed ranges of personality traits shown by BERT under various contexts, indicating full-spectrum trait manipulation capability.
Gender Differences in Personality
An analysis comparing male and female character names across common US names shows tendencies aligning broadly with empirical findings—higher female scores for agreeableness and conscientiousness, but diverging for emotional stability—highlighting existing biases or context-sensitivity.
Discussion and Implications
The findings underscore LMs' potential both as tools for personality identification and as adaptable agents in dialog systems. Future work could explore larger models and diverse data inputs to ascertain the scalability and robustness of personality trait manipulation. The role of context in amplifying perceived personality traits calls for comprehensive understanding and mitigation of biases that may unfavorably characterize or misrepresent user interactions.
Conclusion
The paper delineates key methodologies to steer personality traits in LMs predictably, offering a foundation for more personalized and bias-aware applications. By leveraging context and psychometrics, LMs can not only be advanced as models of human-like interaction but also be refined for wider societal interaction and acceptance, fostering ethical AI deployment.