Abstract
We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
Overview
-
Diffusion Transformers (DiTs) integrate transformer architectures with diffusion models for generative modeling, focusing on the latent representations of images to achieve high-resolution image generation.
-
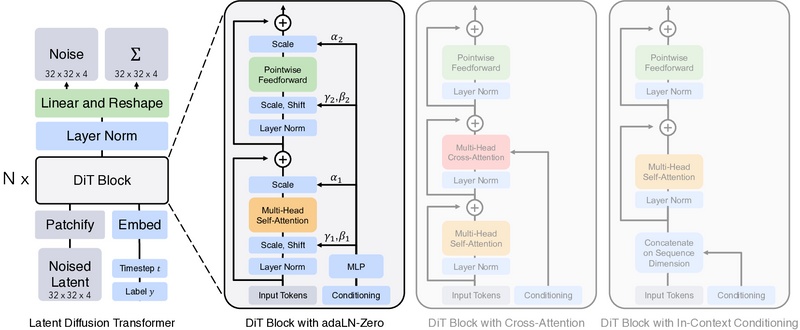
The DiT architecture modifies the Vision Transformer design to support diffusion processes, introducing adaLN-Zero blocks for improved performance and leveraging model scalability for enhanced image fidelity.
-
Empirical evaluations demonstrate DiTs' superiority in image generation quality and training efficiency over existing models, particularly on challenging ImageNet benchmarks.
-
The study highlights the theoretical and practical implications of using transformers in diffusion models and suggests future research directions for further advancements in generative modeling.
Scalable Diffusion Models with Transformers Achieve State-of-the-Art Image Quality
Introduction to Diffusion Transformers (DiTs)
A new paradigm in generative modeling has emerged through the integration of transformer architectures with diffusion models, coined as Diffusion Transformers (DiTs). These models operate by training on latent representations of images, thus deviating from the conventional U-Net-based backbone widely adopted in prior diffusion models. The research presented demonstrates a significant leap in the image generative domain, leveraging the scalability and adaptability of transformers to achieve unprecedented results in high-resolution image generation.
DiT Architecture and Design Space
At the core of DiTs is a visionary adaptation of the Vision Transformer (ViT) design, tailored to accommodate the unique demands of diffusion models. This adaptation encompasses a transformer network that directly manipulates latent patches of images, introducing a novel approach to image synthesis. The architecture's scalability is thoroughly analyzed through variations in transformer depth, width, and the number of input tokens, revealing a robust correlation between model complexity and image fidelity, as quantified by the Frechet Inception Distance (FID) metrics.
A distinctive aspect of the DiT's design is the introduction of adaLN-Zero blocks, a nuanced variation of adaptive layer normalization, showcasing an innovative initialization strategy that ensures each DiT block commences as the identity function. This design choice has proven instrumental in enhancing model performance, marking a departure from traditional practices in the genre.
Empirical Evaluation
Extensive empirical evaluations underline the effectiveness of DiTs across multiple dimensions:
- Model Scaling and Ablation: DiTs exhibit exceptional performance scaling with an increase in model size and decrease in patch size, consistently outperforming existing diffusion models in terms of FID.
- Training Efficiency: Larger DiT models not only pioneer in generative quality but also in compute efficiency, demonstrating superior utilization of computational resources during training.
- Benchmark Performance: On challenging ImageNet 512x512 and 256x256 benchmarks, the largest DiT variant achieves state-of-the-art performance, underscoring the transformative potential of integrating transformers with diffusion models. This leap is marked by notable improvements in diverse evaluation metrics beyond FID, encompassing sFID, Inception Score, Precision, and Recall.
Theoretical and Practical Implications
The integration of transformers within the diffusion paradigm presents compelling theoretical and practical implications. Theoretically, it extends the applicability of transformers, showcasing their versatility beyond language and conventional vision tasks. Practically, it sets a new benchmark in image generation, with potential applications spanning content creation, digital art, and beyond. Additionally, the architecture's scalability hints at the untapped potential awaiting further exploration in larger models and expansive datasets.
Looking Forward
The research on DiTs presents a foundational step towards harnessing the full potential of transformers in generative modeling. Future avenues may include exploring cross-domain applications, enhancing model efficiency, and further pushing the boundaries of image quality and diversity. As the model continues to evolve, it stands to significantly influence the trajectory of generative model research and applications.
Acknowledgments
This research was made possible through contributions from across the academic community, with special thanks extended to team members and supporting institutions for their invaluable input and support.
Conclusion
Diffusion Transformers (DiTs) emerge as a powerful new class of generative models, bridging the capabilities of transformers with the nuanced requirements of diffusion-based image generation to achieve unparalleled results. Through rigorous architectural innovation and empirical validation, DiTs redefine the horizons of what's possible in the realm of generative AI, setting a new standard for image quality and model scalability in the process.