- The paper’s main contribution is the development of HALIE, an evaluation framework that measures interactive human-LM dynamics over process, perspective, and criteria dimensions.
- The methodology incorporates user-centric evaluations and empirical analyses across tasks like QA, metaphor generation, and social dialogue, revealing gaps between static and interactive metrics.
- Key results demonstrate that traditional non-interactive benchmarks overlook crucial user-adaptive behaviors, highlighting the need for dynamic, process-based evaluation in real-world LM deployments.
Evaluating Human-LLM Interaction: A Comprehensive Framework for Interactive LM Evaluation
Introduction and Motivation
"Evaluating Human-LLM Interaction" (2212.09746) introduces HALIE, a formal evaluation framework targeting the assessment of LMs in truly interactive, real-world use cases. The central claim is that non-interactive, static benchmarks obscure critical nuances of human-LM dynamics. The authors provide robust evidence that optimizing for non-interactive benchmark performance does not guarantee optimal LM behavior when deployed as collaborative, interactive agents, challenging assumptions underlying most current LM evaluation pipelines.
HALIE: Dimensions and Methodological Extension
HALIE structures evaluation across three dimensions:
- Targets: Not limited to final outputs, but encompassing the full interaction process.
- Perspectives: Incorporating first-person, subjective user experience in addition to canonical third-party assessment.
- Criteria: Expanding beyond traditional notions of output quality to include attitudinal user measures such as enjoyment, ownership, and preference.
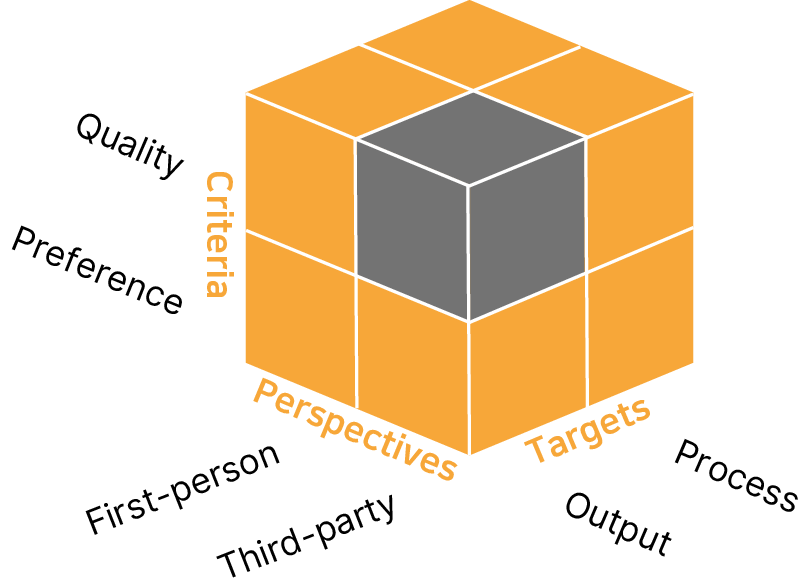
Figure 1: HALIE expands evaluation along process, perspective, and criteria axes, establishing a 2x2x2 space of human-LM evaluation metrics beyond standard paradigms.
Through this multidimensional cube, HALIE operationalizes the evaluation of interaction traces, not merely final model outputs, explicitly formalizing the role of user actions and state transitions within interactive LM systems.
Task Instantiations and System Architectures
HALIE was instantiated on five tasks chosen to span the goal-oriented to open-ended continuum: social dialogue, question answering, crossword puzzles, text summarization, and metaphor generation.
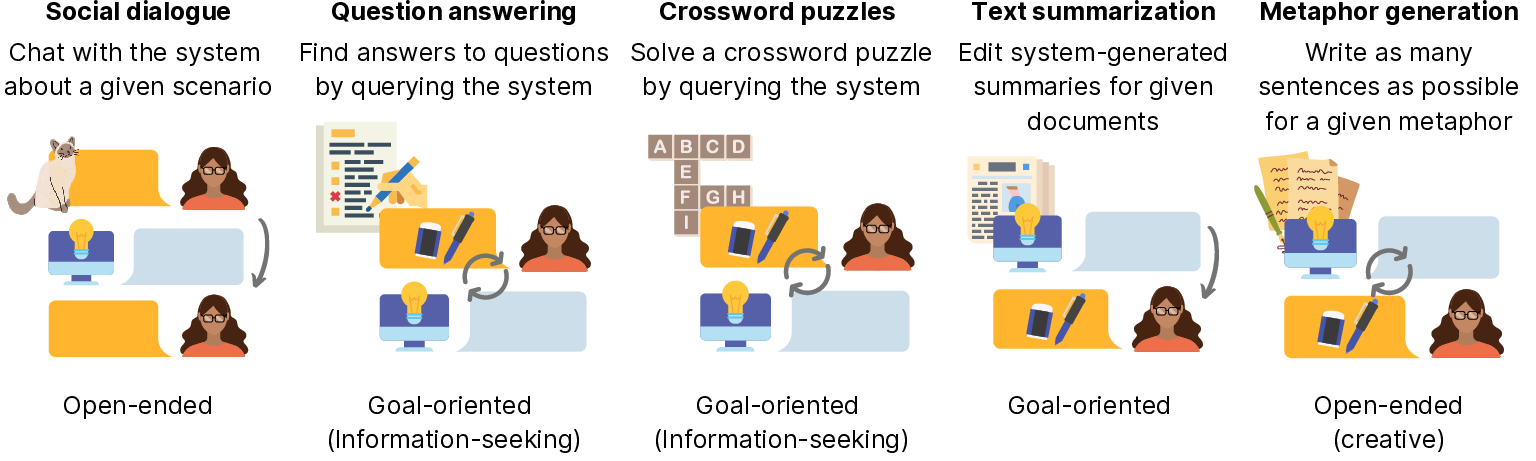
Figure 2: The five tasks cover a spectrum of human-LM interaction types from tightly-goal-directed (e.g., QA) to open-ended ideation (e.g., metaphor generation).
For each task, a distinct interactive system is defined at the levels of UI, system logic, and LM invocation protocol, emphasizing that the evaluation is of end-to-end, user-facing systems – not just raw model completions.
Key Empirical Findings
Divergence Between Non-Interactive and Interactive Metrics
The empirical section contextualizes model behavior via user studies aggregating over 1000+ interaction traces and extensive subjective/user-centric survey data. Notably:
- In QA, the worst-performing LM in the non-interactive, zero-shot setup equaled or outperformed stronger models as a collaborative assistant in select question categories, defying leaderboards as a selection criterion.
- For metaphor generation, output-based metrics (e.g., edit distance) and process-based metrics (e.g., time per composition) did not always correlate; the model requiring the least user edit per suggestion was not always the model minimizing query or composition time.
Quality vs. Preference: A Nontrivial Relationship
Results from the social dialogue task demonstrate that metrics like fluency, sensibleness, and humanness favored specific instruction-tuned LMs. However, models that scored lower on these axes but higher on specificity were equally preferred for continued interaction, suggesting misalignment between conventional quality metrics and actual human engagement drivers.
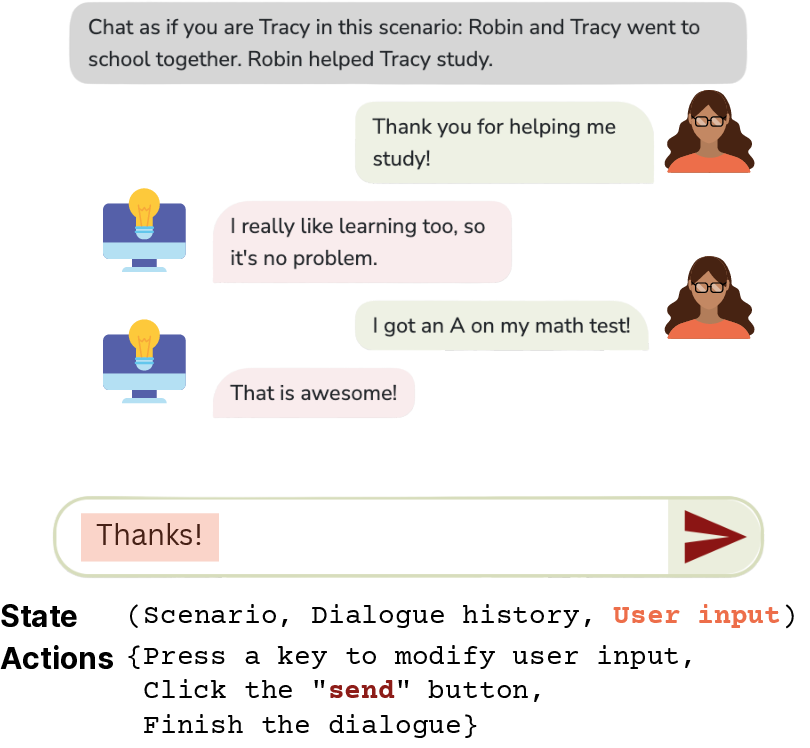
Figure 3: Example social dialogue interface, illustrating how user/system state and actions are tracked and evaluated.
First-Person vs. Third-Party Perspective Discrepancies
For text summarization and crossword puzzles, HALIE revealed instances where users rated certain LMs as more helpful or satisfactory than warranted by third-party evaluations of the final outputs. This suggests that subjective user experience is a critical, largely neglected, axis for system assessment.
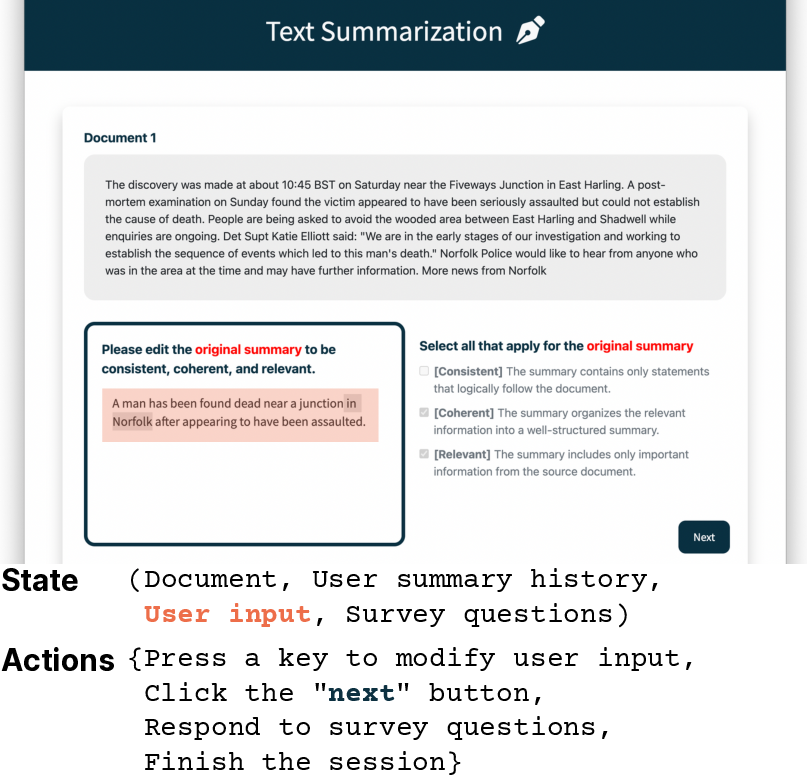
Figure 4: Text summarization system state, showing user summary history and interactive editing—central to process-based evaluation.
Dynamics of Human-LM Co-Adaptation
In both QA and crossword puzzles, user prompting behavior evolved over time. For instance, users learning to include multiple-choice answers as context for the LM, or shifting from question-style prompts to keyword-based cues, illustrated a two-way accommodation effect between the user and LM/system. HALIE's process-level metrics are essential for capturing these adaptive, longitudinal effects.
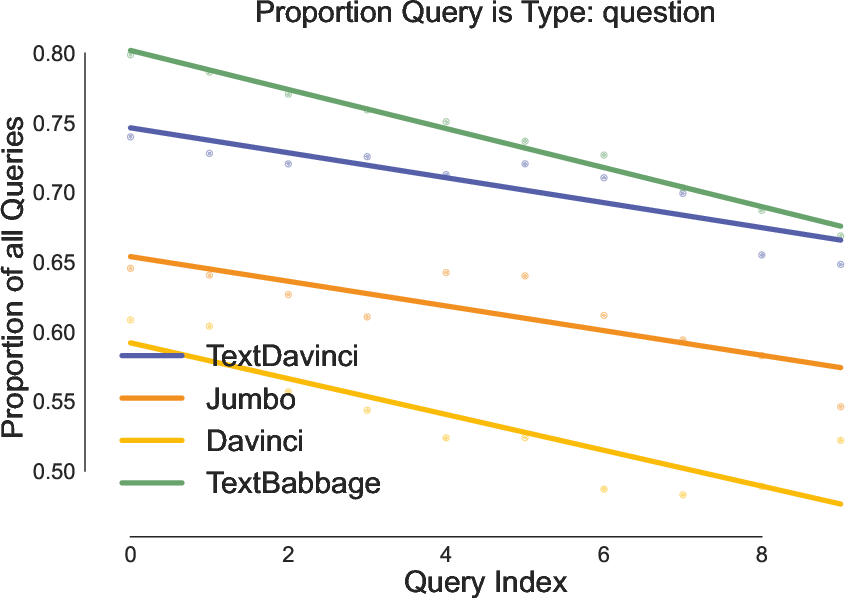
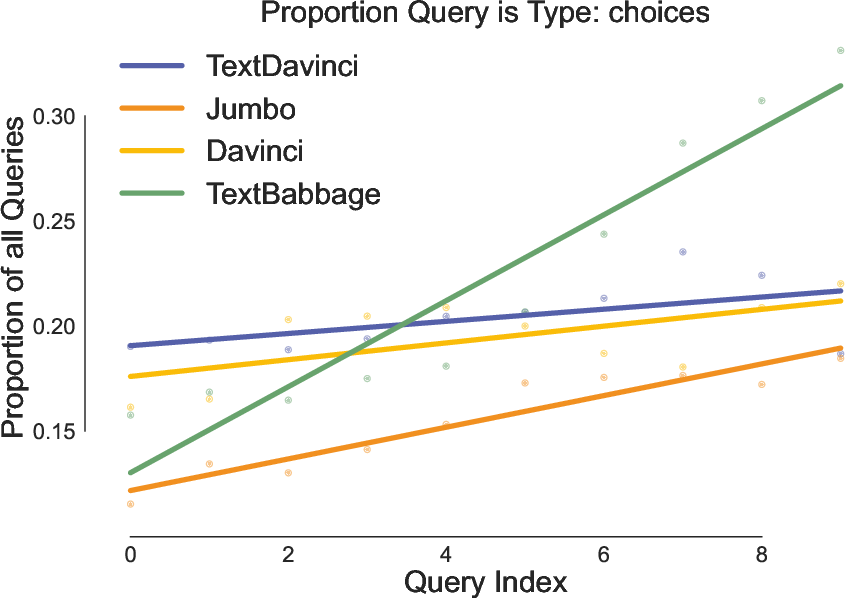
Figure 5: Quantitative evidence that users decrease question-style prompts over time, reflecting behavioral adaptation in interaction.
Harms, Safety, and Subjectivity
HALIE’s extensive user studies surfaced persistent LM harms—high-confidence misinformation and even toxic content—particularly when interaction UIs elicited short or minimally-contextual prompts (e.g., in crossword puzzles). The authors argue that interactive evaluation is crucial for both identifying and mitigating these safety hazards, which are poorly surfaced by static output sampling.
Implications and Future Outlook
HALIE’s central empirical claim is that model selection based solely on static non-interactive benchmarks is unreliable and potentially misleading for interactive LM deployments. This has immediate consequences for both research practice and real-world system optimization:
- Benchmark design must integrate process-based, user-centric, and attitudinal evaluation axes.
- Effective LM deployment in creative or assistive contexts requires tailored, task-specific interactive evaluation.
- The framework supports extensibility to new settings, but may require augmentation for multi-user/multi-agent contexts or for LMs evaluated solely by other LMs.
- Longitudinal effects, user drift/adaptation, and societal-level impacts of widespread interactive LM usage remain rich open problems.
Conclusion
"Evaluating Human-LLM Interaction" establishes HALIE as a necessary extension to current LM evaluation paradigms. By formalizing the distinction between process and output, third-party and first-person perspective, and quality and user preference, HALIE empirically demonstrates the limits of standard benchmarks and provides a guiding methodology for robust, real-world interactive LM evaluation. This framework should inform both system-building and future research in the evaluation and alignment of LLMs under authentic, human-centric use cases.