- The paper introduces a novel latent diffusion framework (LD4LG) that bypasses the discrete token limitation by operating in a continuous latent space.
- The methodology integrates a pretrained encoder-decoder, compression networks, and a diffusion model to efficiently generate high-fidelity text.
- Experimental results demonstrate superior quality, diversity, and efficiency compared to prior diffusion and autoregressive models.
Latent Diffusion for Language Generation: A Technical Analysis
Introduction
The paper "Latent Diffusion for Language Generation" (2212.09462) presents an innovative framework for generative modeling in the space of natural language by exploiting the strengths of latent diffusion models (LDMs) within discretized, linguistically grounded domains. While diffusion models have achieved state-of-the-art results in high-dimensional continuous domains such as image, audio, and video synthesis, their direct application to language has been hindered by the inherently discrete structure of text. This work addresses core technical obstacles by proposing Latent Diffusion for Language Generation (LD4LG), a method that transfers diffusion into the continuous latent space of a high-capacity language autoencoder, effectively circumventing the limitations associated with the discrete nature of text tokens.
Methodology
LD4LG is architecturally characterized by the integration of a pretrained encoder-decoder LLM (e.g., BART, T5), an additional pair of compression and reconstruction networks, and a continuous diffusion process within a learned, compact, fixed-length latent space. The entire generation pipeline can be analytically decomposed as follows:
- Language Autoencoding: Input token sequences are mapped to variable-length, high-dimensional contextual representations by a frozen LM encoder. The compression network, adopting a Perceiver Resampler design, interrogates these features via cross-attention, compressing them to a fixed-length, low-dimensional latent suitable for diffusion. The reconstruction network inverts this operation, expanding the compressed latents back to a high-dimensional space compatible with the LM decoder, facilitating high-fidelity reconstruction.
- Latent Diffusion Modeling: A diffusion model is trained to map Gaussian noise iteratively to the latent space of the language autoencoder. The sampling process in generation starts from pure Gaussian noise; the denoising network, parameterized as a pre-LN transformer with self-conditioning and alpha-conditioning, iteratively refines this noise toward semantic latent representations.
- Decoding: The denoised latent is mapped back through the reconstruction network, and the pretrained decoder performs cross-attentive decoding to produce natural language text.
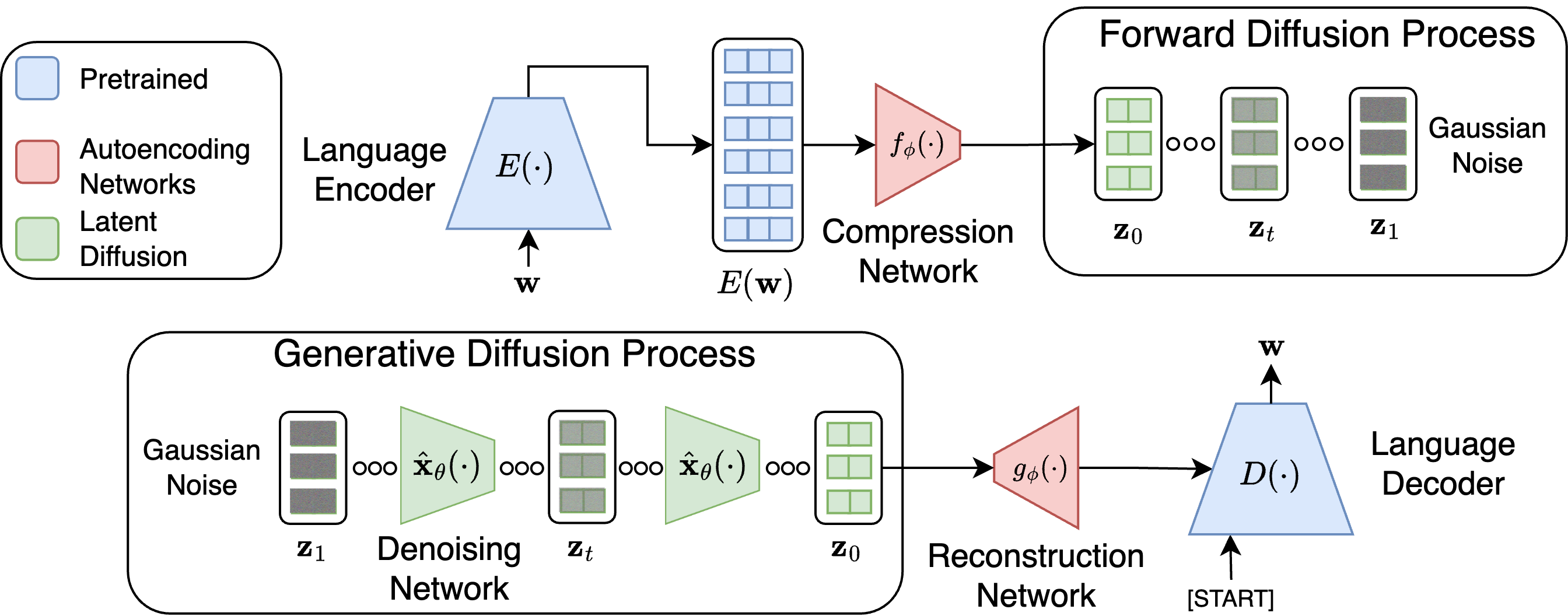
Figure 1: Overview of the latent language diffusion framework, showing latent encoding, diffusion-based generation, and decoding into text.
The approach also supports label conditioning for class-controlled generation and source conditioning in seq2seq scenarios, with denoising networks equipped with cross-attention to source features.
Experimental Results
The empirical results provided demonstrate several critical claims with substantial numerical evidence:
- Superiority to Prior Diffusion Models: On ROCStories, LD4LG (BART-base) achieves a MAUVE score of 0.716 with 250 sampling steps, compared to Diffusion-LM's 0.043 with 2000 steps; on XSum, LD4LG attains a ROUGE-L of 31.9 (BART-based), versus DiffuSeq's 14.1 under comparable conditions.
- Efficiency: LD4LG requires an order of magnitude fewer generation steps compared to previous continuous diffusion text models, with ablation showing that compression of latent space not only increases final quality (relative speedup of 3.86× to reach baseline MAUVE) but dramatically reduces compute.
- Generalization and Diversity: The models are robust to memorization—a known failure mode of autoregressive text generation—yield lower n-gram overlap with training data, and display higher diversity compared to both diffusion and strong AR baselines on several metrics.
- Control and Conditioning: In class-conditional setups (e.g., AG News), LD4LG delivers high-fidelity, class-conditional generations, with sharply diagonal MAUVE matrices indicating correct conditioning alignment. For seq2seq tasks like summarization and paraphrasing, LD4LG matches or surpasses fine-tuned AR models, particularly when leveraging MBR decoding to sample/re-rank multiple outputs.
Architectural and Algorithmic Insights
Key architectural and training decisions include:
- Denoising Network: Uses a pre-LN transformer with 12 layers, GeGLU activations, dense connections, learnable positional encodings, and adaptive layer norm. Alpha-conditioning and class/source-conditioning embeddings ensure diffusion awareness.
- Latent Constraints: The latent space is optionally scaled to match the expected norm of noise, facilitating stable and efficient diffusion.
- Self-Conditioning: The adoption of self-conditioning yields substantial improvements in sample quality, reducing perplexity and increasing MAUVE.
- Computation: The quadratic complexity of self-attention is mitigated by compressing the latent sequence to fixed length before diffusion.
Theoretical and Practical Implications
This work demonstrates that latent-space diffusion offers a highly effective synthesis of semantic control and tractability for text domains, overcoming key issues in direct discrete or embedding-space diffusion. The separation of high-frequency detail modeling (handled by the autoencoder/decoder) from higher-level semantic compositionality (modeled by the diffusion process) is shown not only to be feasible but advantageous for language.
Practically, LD4LG enables unconditional, conditional, and sequence-to-sequence generation with a single, unified framework. The system is competitive with, and sometimes superior to, strong AR baselines, particularly when coverage and sample diversity are valued. This presents an appealing alternative in scenarios where sample quality, controllability, and resistance to memorization are paramount—for example, in dialogue systems, controlled story generation, or abstractive summarization.
Theoretically, successful application of LDMs to text suggests new research avenues:
- Development of universal, pretrained language autoencoders amortized across domains.
- Diffusion step distillation for accelerated inference, potentially reducing sampling to a handful of steps.
- Integration of explicit coverage or risk-averse decoding strategies (e.g., improved MBR).
Limitations and Open Directions
Despite its strengths, LD4LG inherits sampling latency from the iterative nature of diffusion models. Although the current work reduces steps to 250 (versus the ∼2000 used in earlier systems), further reductions via model distillation and advances in guidance strategies are necessary for real-time generation tasks.
Another central limitation is the decoupling of latent modeling and surface realization, which means final quality remains coupled to the fidelity of the autoencoding backbone. The autoencoder is also trained per dataset in this work; scaling to previously unseen domains or amortizing this cost remains to be explored.
Finally, coverage in decoding is high, but identification of optimal samples via MBR is imperfect in the absence of ground truth (noted in summarization experiments), indicating room for improved candidate ranking or learned proposal models.
Conclusion
Latent Diffusion for Language Generation (2212.09462) establishes a compelling, high-performance generative paradigm for LLMs, achieving substantial improvements over prior diffusion-based methods in controllable, efficient, and diverse text generation. By leveraging diffusion in the continuous latent spaces of high-capacity language autoencoders, this framework provides a scalable, adaptable blueprint for future research in non-AR text generation, controlled language modeling, and hybrid AR-diffusion architectures. The methodological separation of semantic latent modeling from token-level detail is particularly noteworthy, and the approach has the potential to become foundational for a new family of controllable, robust NLP systems.

