- The paper introduces a novel few-shot planning method that generates high-level subgoals for embodied agents with minimal labeled data.
- It employs a hierarchical framework that separates subgoal generation from low-level action execution, enhancing planning precision.
- Dynamic grounded re-planning allows the system to adapt plans based on real-time environmental feedback, achieving a 15.36% success rate on unseen tasks.
LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with LLMs
Introduction
This paper introduces the concept of using LLMs as planners for embodied agents, specifically focusing on the task of following natural language instructions in visually-perceived environments. The proposed system, LLM-Planner, leverages the capabilities of LLMs such as GPT-3 for few-shot high-level planning. This approach addresses the high data cost and low sample efficiency issues prevalent in contemporary models, which traditionally require extensive labeled examples to learn new tasks. LLM-Planner utilizes physical grounding to enhance planning, facilitating dynamic plan updates based on environmental feedback.
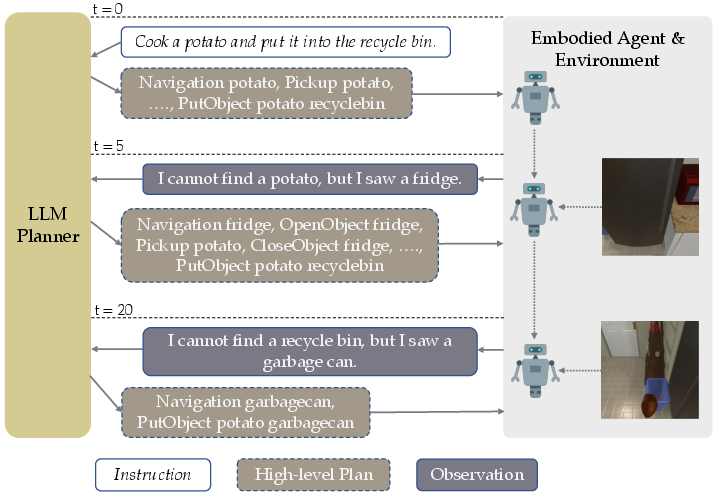
Figure 1: An illustration of LLM-Planner for high-level planning, highlighting the re-planning mechanism when agents get stuck.
Framework
Hierarchical Planning
The LLM-Planner employs a hierarchical planning structure consisting of high-level and low-level planners. The high-level planner generates a sequence of subgoals based on natural language instructions using LLMs. These subgoals guide the agent in achieving the final task objective. The low-level planner then translates each subgoal into primitive actions tailored to the current environment, decoupled from language instructions once the high-level plan is established.
Dynamic Grounded Re-planning
The innovation in dynamic grounded re-planning allows agents to adapt plans based on observations, thus grounding the LLM's decisions in physical reality. When the agent struggles to achieve a subgoal, environmental cues prompt the LLM to update the plan, considering newly perceived objects and contextual information.
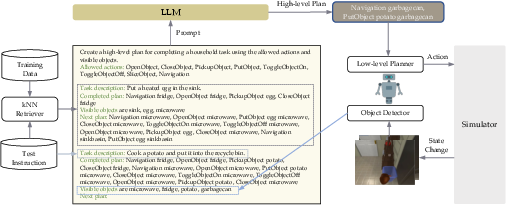
Figure 2: Overview of LLM-Planner with prompt design and grounded re-planning.
Experiments and Results
Dataset and Metrics
The ALFRED dataset serves as the testing ground, featuring diverse tasks and complex environments. Evaluation metrics include success rate, goal-condition success rate, and a novel high-level planning accuracy metric to directly assess performance.
The LLM-Planner demonstrates competitive performance using under 0.5% of the data compared to full dataset models like HLSM. It substantially outperforms several baselines under few-shot settings, exhibiting 15.36% success rate on unseen valid splits—a marked improvement over traditional approaches.
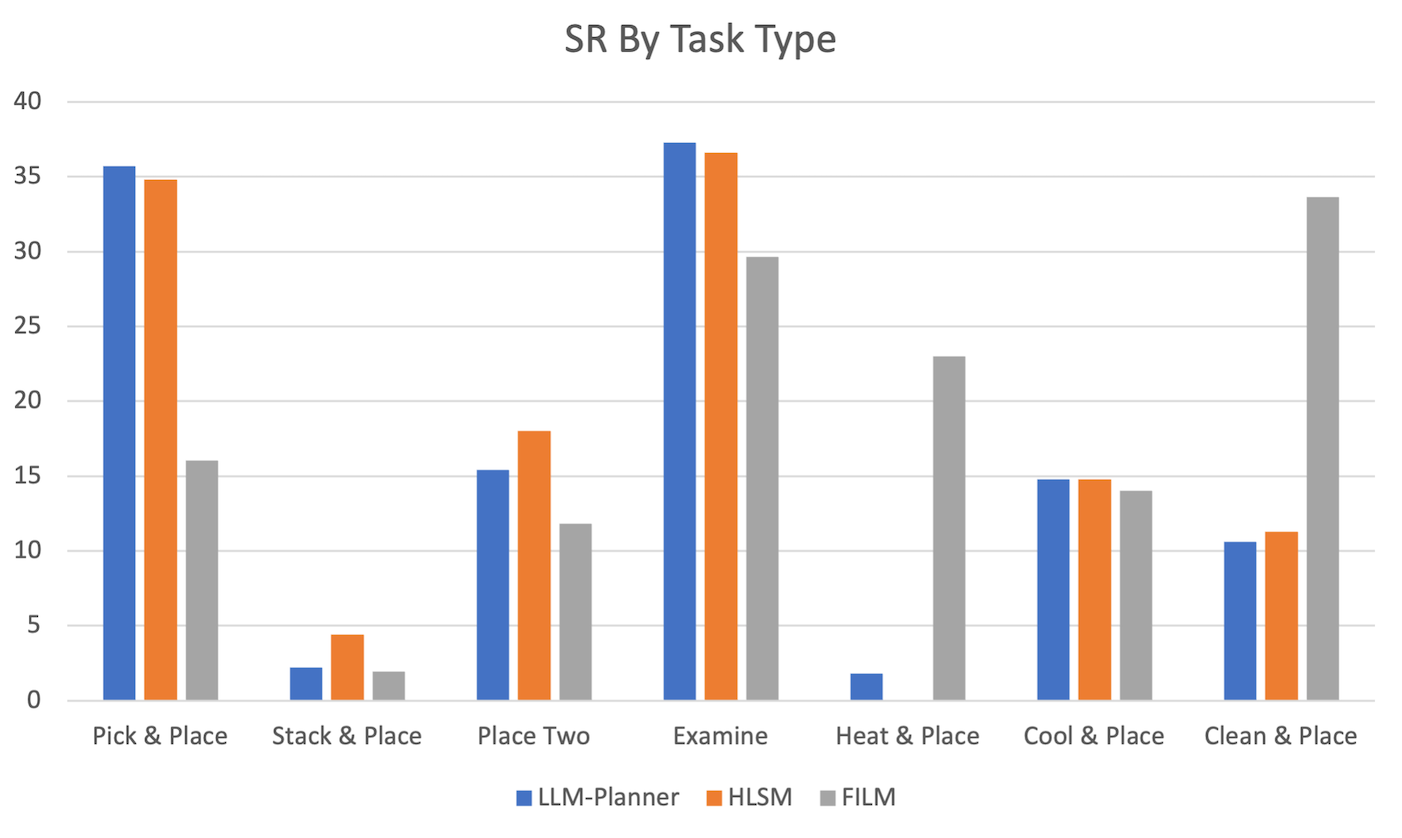
Figure 3: Success rate by task type on ALFRED valid unseen split.
Implementation and Integration
Prompt Design
Optimal prompt design is critical for harnessing GPT-3's planning capabilities. The final prompt structure incorporates task explanations, goal instructions, and environmental cues. In-context examples are selectively retrieved using a kNN mechanism, enhancing accuracy.
System Integration
Integrating LLM-Planner into existing frameworks involves employing the high-level planner's outputs in tandem with pre-trained models for perception and navigation. Notably, the grounded re-planning algorithm dynamically adjusts as tasks progress, ensuring resilience and adaptability.
Future Directions
Future research could explore expanding the model's capabilities by integrating more advanced LLMs and refining grounding techniques. Additionally, real-world deployment could benefit from improved environmental interaction models and object detectors to further augment performance.
Conclusion
LLM-Planner represents a significant advancement in few-shot planning for embodied agents, offering a scalable, versatile solution that mitigates the traditional reliance on extensive annotated training data while exhibiting robust performance across complex tasks.
The findings indicate promising pathways for leveraging LLMs in autonomous navigation and task execution, paving the way for more intelligent, adaptable robotic systems.

