- The paper demonstrates that lower prompt perplexity correlates with enhanced task accuracy across multiple language models.
- The methodology involves automatic prompt expansion using GPT-3 and backtranslation to generate diverse candidate prompts.
- The SPELL method outperforms manual prompt selection by up to 3.6 points, highlighting its potential for efficient prompt engineering.
Demystifying Prompts in LLMs via Perplexity Estimation
Introduction
The efficacy of prompts in LLMs for zero- and few-shot learning is well-documented, yet there remains considerable variance in performance contingent on the choice of prompt. This paper investigates the factors causing this variance, positing that the familiarity of a prompt's language significantly affects task performance. The authors propose that a prompt's perplexity, serving as a proxy for its familiarity during training, inversely correlates with performance efficacy when evaluated across diverse tasks and models. Leveraging this insight, they developed a method—SPELL (Selecting Prompts by Estimating LM Likelihood)—for generating effective prompts by minimizing perplexity.
Hypothesis and Methodology
The core hypothesis asserts that lower perplexity in prompts corresponds to superior task performance due to increased familiarity with the model's training data. The paper refrains from direct training data access, which is typically prohibitive, instead recommending perplexity as a proxy measure. This methodology facilitates prompt selection even in the absence of substantial labelled datasets. SPELL involves augmenting an initial seed of manually curated prompts through paraphrasing with GPT-3 and backtranslation, followed by selecting prompts based on their perplexity ranking.
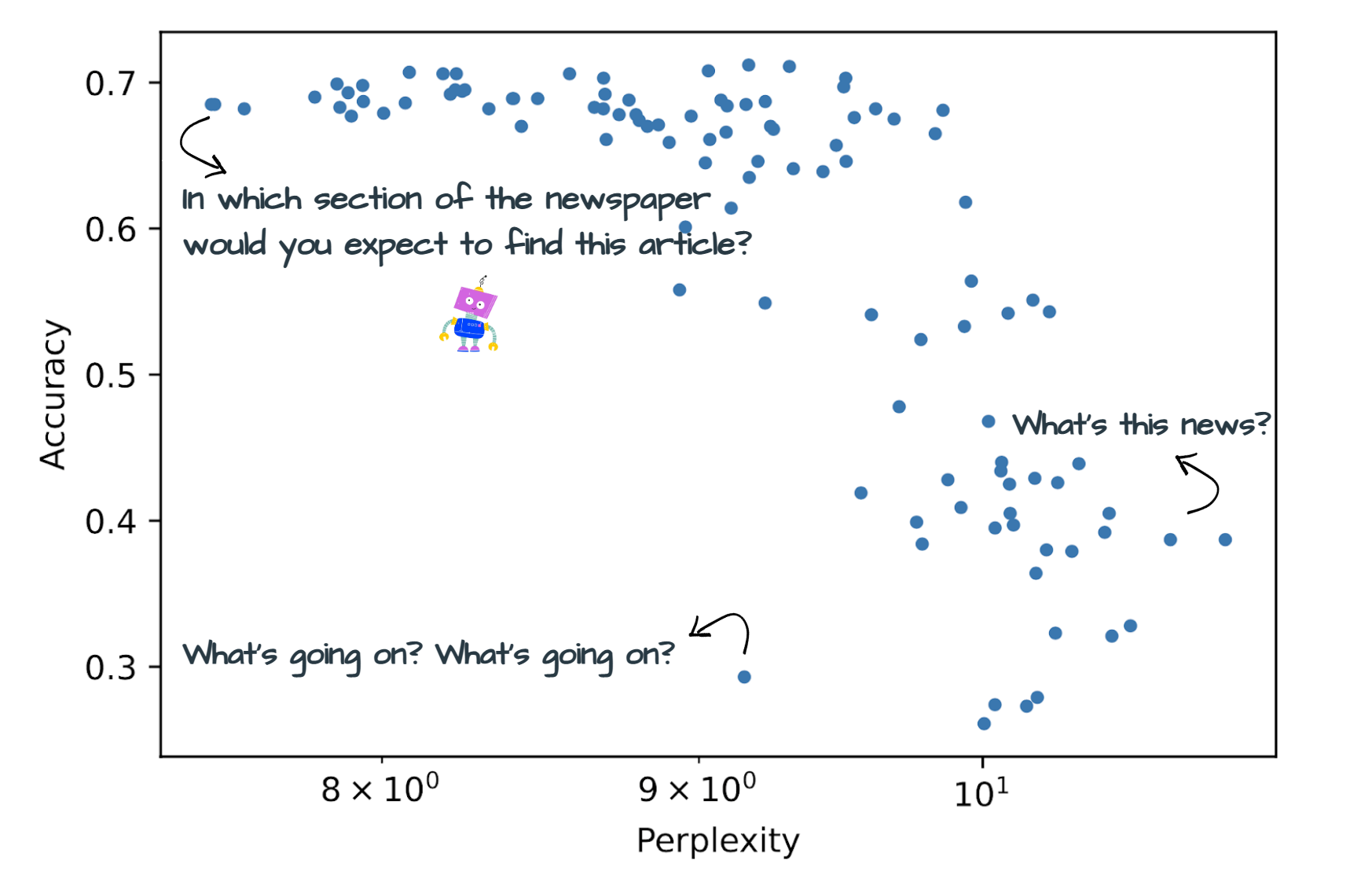
Figure 1: Accuracy vs.~perplexity for the AG News dataset with OPT 175b. Each point denotes a distinct prompt.
Experimental Validation
The empirical evaluation spans four auto-regressive models—OPT (in configurations of 1.3b, 30b, and 175b parameters) and Bloom (176b parameters)—across a broad array of tasks, including word prediction and classification. The analysis confirmed that lower-perplexity prompts generally yield better results, with statistically significant negative correlations across most tasks. This is illustrated in tasks like AG News classification, where substantial accuracy disparities of up to 30 points were observed among manually curated prompts.
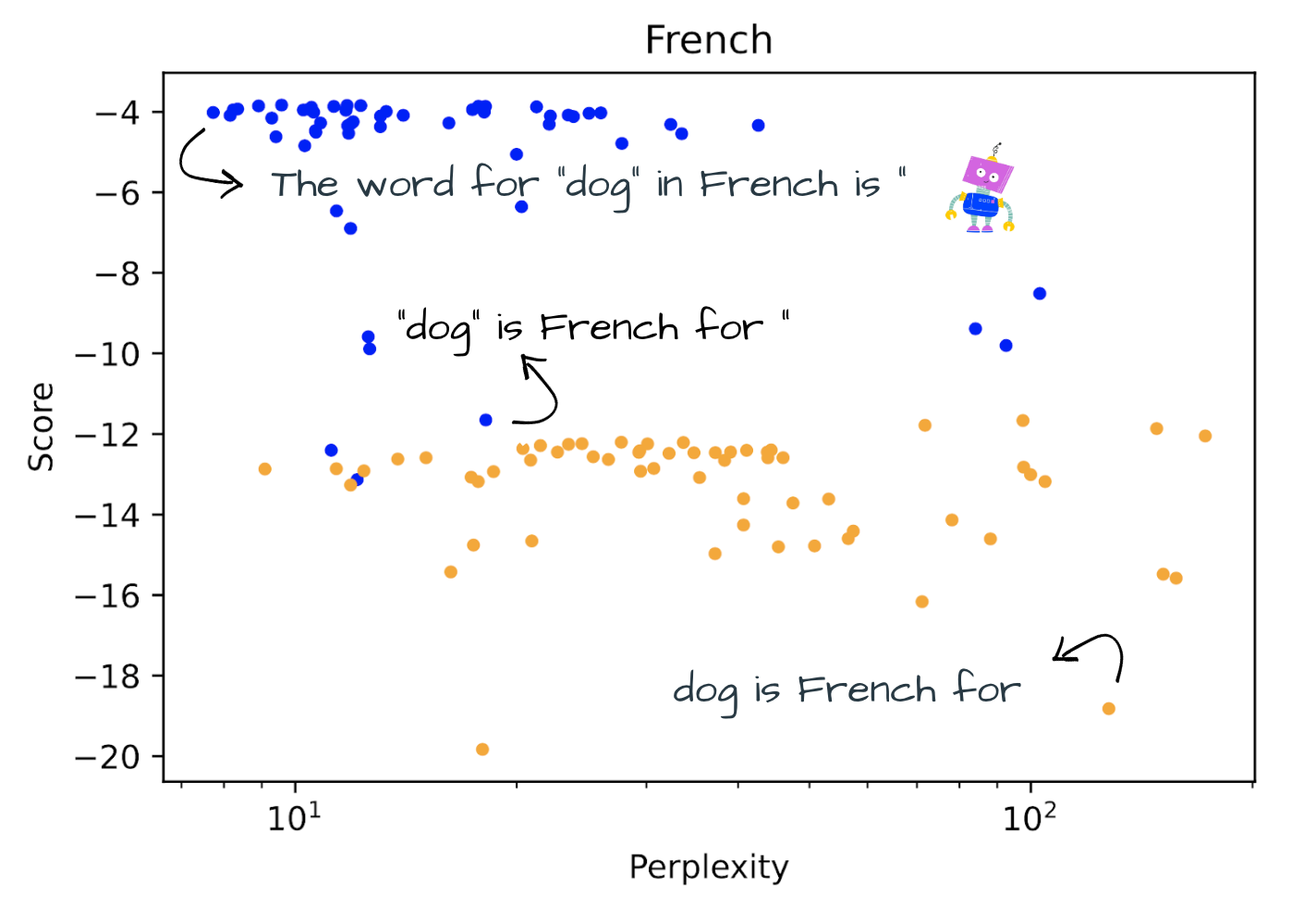
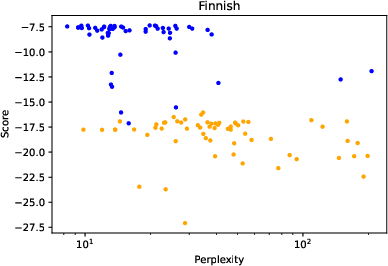
Figure 2: Score of correct label vs. perplexity for the word-level translation task with OPT 175b. Blue points represent prompts using quotation marks.
Prompt Expansion and Selection
The automatic expansion process utilizes GPT-3 for paraphrasing from a seed set of prompts, followed by backtranslation to enrich prompt variety. The final selection via SPELL leverages the perplexity measure, assuring minimal human intervention while optimizing task performance. The paper documents that SPELL's chosen prompts outperform manual attempts by approximately 1.8 points with OPT 175b and 3.6 points with Bloom on average.
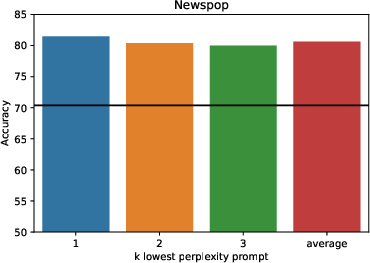
Figure 3: Accuracy with k lowest perplexity prompts compared to the average accuracy of manual prompts for Tweet Offensive and Newspop tasks.
Discussion and Implications
The findings reveal that prompt performance is heavily model-specific, as depicted by the minimal overlap between effective prompts across different models. This necessitates tailored analysis for each model when developing a low-perplexity prompt base.
Furthermore, the magnitude of perplexity's impact varies by task, suggesting deeper integrations of task-specific characteristics in future prompt design strategies.
Conclusion
The paper elucidates a decisive link between prompt perplexity and task efficacy in LLMs, alongside proposing a pragmatic method for prompt selection that reduces development overhead. While primarily validated on OPT and Bloom models, SPELL underscores the potential for broad application across other LLM architectures and tasks.
In closing, the insights and methodologies presented facilitate enhanced comprehension and optimization of prompts for real-world LLM applications, poised to advance the state-of-the-art in adaptive, automated prompt engineering.