- The paper demonstrates that integrating frozen general PLM memory using a memory-attention mechanism effectively prevents catastrophic forgetting in domain-specific tasks.
- It introduces multiple memory-transfer strategies, including single-layer, multiple-layer, gated, and chunk-based methods, with the chunk-based approach showing superior performance.
- Experimental results across text classification, QA, and NER tasks confirm that G-MAP enhances domain adaptation while preserving general knowledge in NLP.
Summary of "G-MAP: General Memory-Augmented Pre-trained LLM for Domain Tasks"
Introduction and Motivation
The paper "G-MAP: General Memory-Augmented Pre-trained LLM for Domain Tasks" addresses the issue of catastrophic forgetting in domain-adaptive pre-training (DAPT) within pre-trained LLMs (PLMs). Conventional approaches to enhancing domain-specific performance, such as DAPT, involve further pre-training PLMs on domain-specific corpora. However, this often leads to the degradation of general knowledge, impairing performance on tasks that require such information.
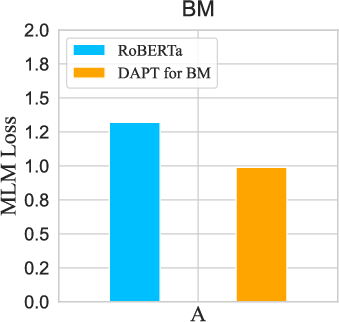
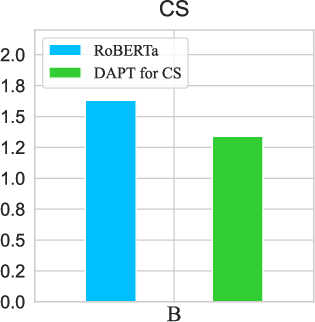
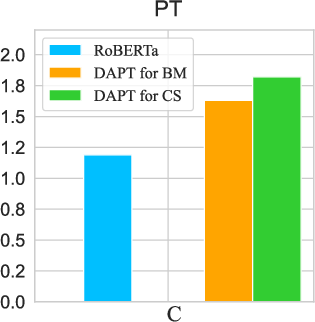
Figure 1: Masked LM (MLM) loss of RoBERTa on 50K randomly sampled documents from each domain before and after DAPT, illustrating catastrophic forgetting.
To tackle this problem, the authors propose a framework called General Memory-Augmented Pre-trained LLM (G-MAP), which augments domain-specific PLMs with memory representations derived from frozen general PLMs, thereby preserving general domain knowledge. This memory-augmented model aims to enhance the generalization capabilities of domain-specific PLMs without additional training of the general PLM.
Methodological Framework
G-MAP Architecture
The core concept of G-MAP revolves around integrating general knowledge from a frozen PLM into a domain-specific PLM through a novel memory-augmented layer. This integration involves a memory-attention mechanism that adaptively fuses general and domain-specific representations.
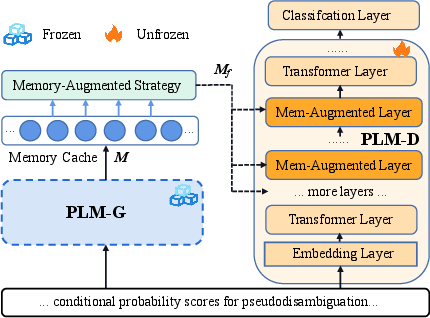
Figure 2: A framework of G-MAP with the cs-domain task input.
Memory-Augmented Strategies
The paper explores several strategies for constructing and transferring memory representations:
- Single-Layer Memory Transfer: This approach incorporates the last hidden state of the general PLM as a memory cache into a single layer of the domain-specific PLM.
- Multiple-Layer Memory Transfer: Here, all hidden states from the general PLM are transferred to corresponding layers in the domain-specific PLM.
- Gated Memory Transfer: Using a gating mechanism, layer-wise representations are adaptively combined and fused into one layer of the domain-specific PLM.
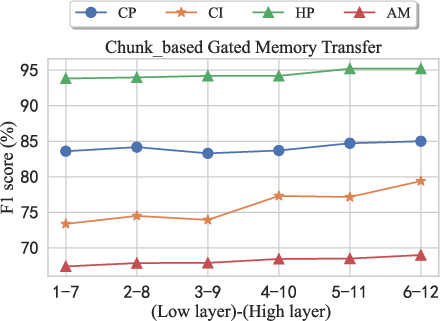
- Chunk-based Gated Memory Transfer: Based on chunking observations, memory representations are divided into high-level and low-level chunks, which are transferred into layers in the domain-specific PLM accordingly.
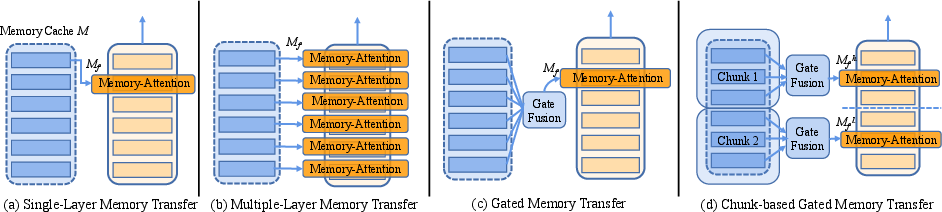
Figure 3: Memory-augmented strategies of the G-MAP framework illustrating layer interactions.
Results and Experimental Analysis
G-MAP demonstrates significant improvements across various domain-specific tasks including text classification, QA, and NER. Particularly, the chunk-based gated memory transfer strategy surpasses other methods due to its efficient utilization of layer-wise token-level information.
Experimental results highlight the effectiveness of leveraging memory from frozen PLMs:
Further Discussion
The study explores the effectiveness of frozen memory, demonstrating that unfreezing memory affects performance and training efficiency adversely. Moreover, comparisons with other attention-based mechanisms establish the superiority of memory-attention due to its parameter efficiency.
Pre-training Stage Application
Applying G-MAP during pre-training shows reduced masked LM loss, suggesting its utility in preserving general knowledge during domain adaptation.
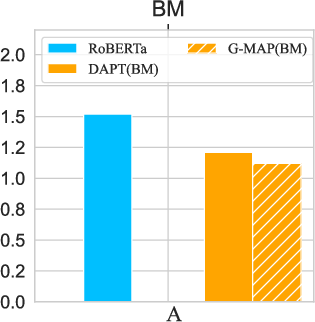
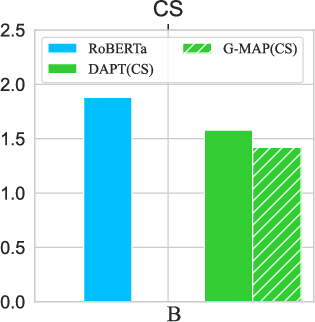
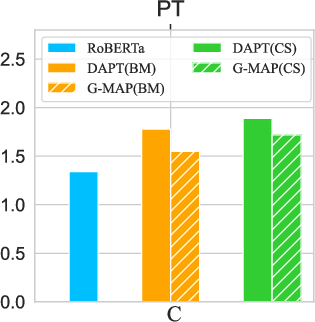
Figure 5: Masked LM loss for the pre-training stage across domains with G-MAP, indicating lower values are better.
Conclusion
The G-MAP framework presents a promising solution to catastrophic forgetting in DAPT scenarios by incorporating memory representations that preserve general knowledge. Its flexibility extends across numerous NLP tasks and domains, with empirical evidence showcasing its superior performance compared to conventional models.
In summary, G-MAP successfully mitigates forgetting while boosting generalization capability, setting a new benchmark for augmenting domain-specific PLMs. Future work could explore large-scale pre-training with G-MAP and investigate automatic layer selection methodologies to enhance performance further.
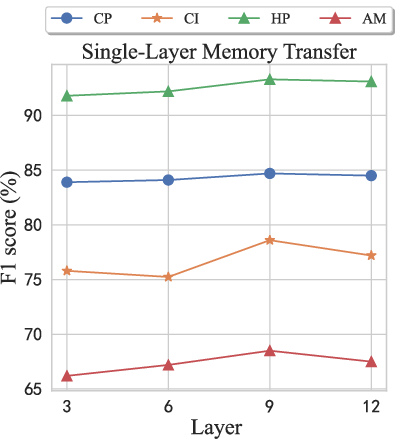
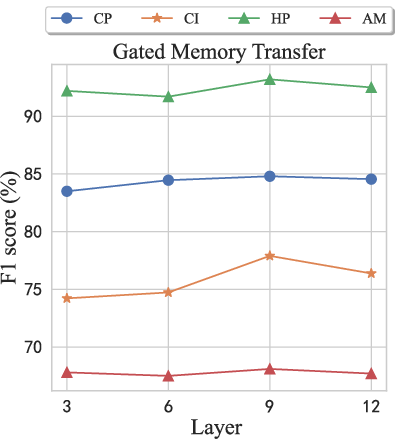
Figure 6: Performance of different layer-selection indexes in memory-attention strategies.