- The paper introduces a bi-level framework that employs Normalizing Flows to learn and adapt sampling distributions for MPC.
- The paper leverages backpropagation-through-time and dynamic mirror descent for online updates of latent space parameters.
- The paper demonstrates improved efficiency and reduced trajectory costs in tasks such as planar navigation and robotic manipulation.
Learning Sampling Distributions for Model Predictive Control
Introduction
This paper presents a novel approach to optimizing Model Predictive Control (MPC) by learning sampling distributions using Normalizing Flows (NFs). The proposed methodology capitalizes on the flexibility and tractability of NFs to enhance sampling strategies in MPC, aiming to improve performance by adapting sampling distributions to the environmental context. The study is motivated by the limitations of traditional Gaussian assumptions in sampling-based MPC, which may lead to suboptimal performance, particularly in complex environments with sparse rewards or high-dimensional dynamics.
Sampling-Based Model Predictive Control
Sampling-based MPC leverages randomized sampling to handle non-differentiable dynamics and costs. A key component is the choice of the sampling distribution. While simple distributions like Gaussians facilitate tractable updates, they fall short in adaptability. To address this, the paper proposes a bi-level optimization framework where the base-level involves updating latent distribution parameters using Dynamic Mirror Descent (DMD), while the top-level learns the NF's transformation parameters. The process involves backpropagation-through-time (BPTT) across episodes, enabling the learned distribution to internalize environmental structure.
Methodology
The paper utilizes NFs to define complex, multimodal control distributions derived from a simpler latent space. The approach involves an episodic training regime where the latent distribution's parameters are iteratively updated online during each episode, while NF parameters are refined post-episode. The NF's ability to map between latent and observation spaces is crucial, as it permits non-differentiable dynamics, particularly through the likelihood-ratio gradients.
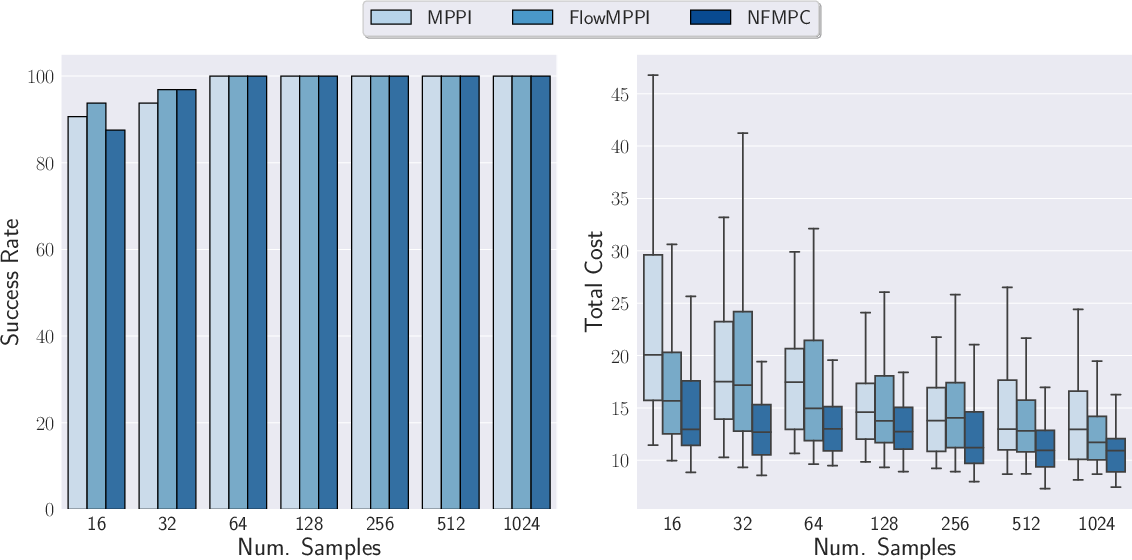
Figure 1: Success rate and cost distribution on the PNRandDyn environment across a different number of samples.
Evaluation and Results
Planar Robot Navigation
The method was tested on a planar navigation task with dynamic obstacles, where controllers need to reach a goal while avoiding collisions. The NFMPC, which fully exploits the latent space updates, demonstrated superior scalability and efficiency with reduced sample counts compared to both the baseline MPPI and a competing FlowMPPI model.



Figure 2: Visualization of a trajectory and top samples from (top) NFMPC, (middle) FlowMPPI, and (bottom) MPPI on the PNRandDyn task.
Franka Panda Arm
In a more complex robotic manipulation task involving a Franka Panda arm, NFMPC maintained a higher success rate and lower trajectory costs across a variety of sample sizes. The results reinforce the efficacy of operating within the NF's latent space and leveraging recurrent training methodologies to adaptively optimize the control distribution.
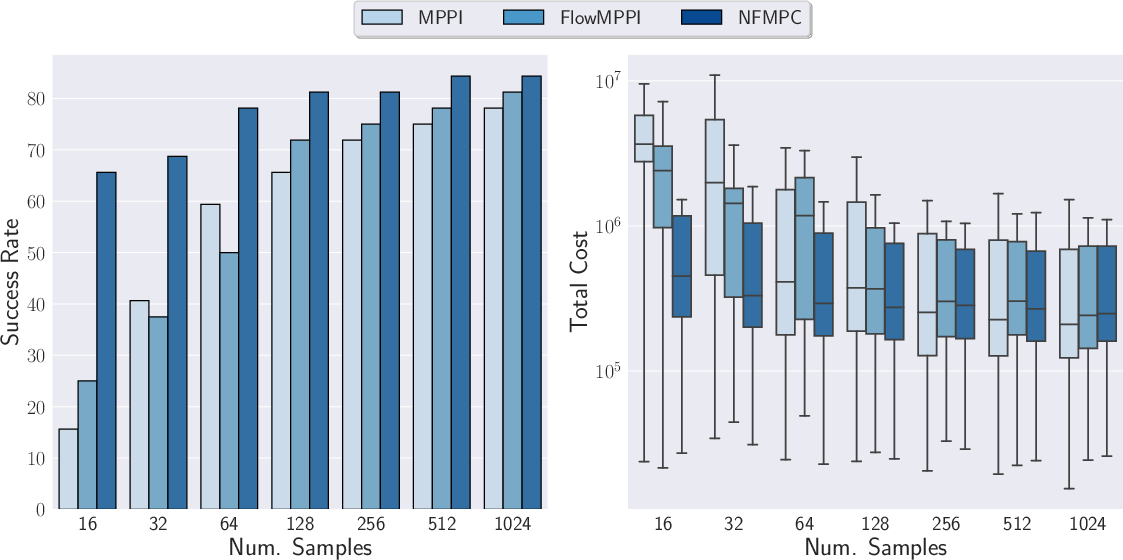
Figure 3: Success rate and cost distribution on the FrankaObstacles environment across a different number of samples.
Limitations and Future Work
A notable limitation of the NFMPC approach is its dependence on task-specific distributions, which restricts straightforward transfer to new environments or dynamics without retraining. Future work could explore architectures that generalize across tasks and environments, potentially by integrating more sophisticated context conditioning strategies. Additionally, the paper acknowledges the computational overhead introduced by the NF; however, it suggests that performance gains and better scalability offer a feasible trade-off, especially with optimized sample reduction strategies.
Conclusion
The proposed approach represents a significant stride in sampling-based MPC by fully utilizing the potential of NFs to reformulate and optimize control sequences. The empirical results affirm that adapting operations into the NF's latent semantic space and incorporating BPTT can advance control performance, particularly in environments characterized by complexity or variability. Future exploration could focus on robustness enhancements and efficiency improvements, potentially extending applicability to broader domains within robotics and beyond.