Adap DP-FL: Differentially Private Federated Learning with Adaptive Noise
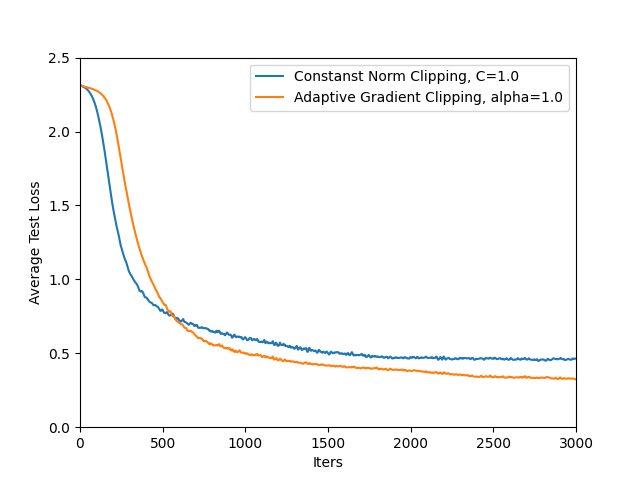
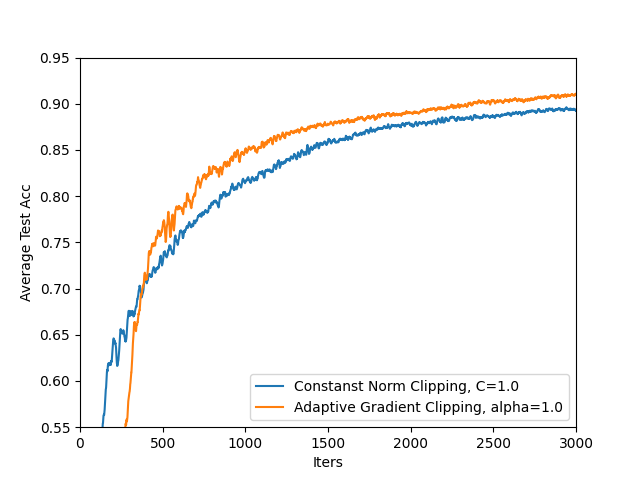
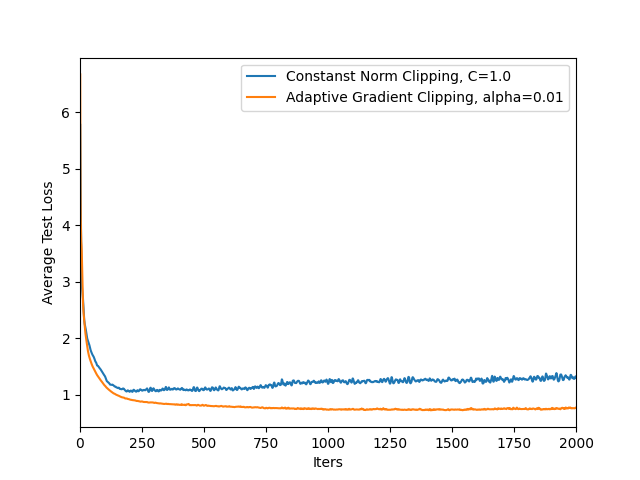
Abstract: Federated learning seeks to address the issue of isolated data islands by making clients disclose only their local training models. However, it was demonstrated that private information could still be inferred by analyzing local model parameters, such as deep neural network model weights. Recently, differential privacy has been applied to federated learning to protect data privacy, but the noise added may degrade the learning performance much. Typically, in previous work, training parameters were clipped equally and noises were added uniformly. The heterogeneity and convergence of training parameters were simply not considered. In this paper, we propose a differentially private scheme for federated learning with adaptive noise (Adap DP-FL). Specifically, due to the gradient heterogeneity, we conduct adaptive gradient clipping for different clients and different rounds; due to the gradient convergence, we add decreasing noises accordingly. Extensive experiments on real-world datasets demonstrate that our Adap DP-FL outperforms previous methods significantly.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open directions that the paper does not address but that are important for future work.
- Formal privacy accounting with data-dependent clipping: Provide a rigorous proof that using previous-round DP-noised statistics to set the next round’s clipping thresholds preserves the intended DP guarantees, including how data-dependent sensitivity interacts with the RDP accountant across rounds.
- Correctness of Theorem 1 under varying sensitivity: The stated RDP/DP bound appears to assume unit sensitivity and does not explicitly carry the dependence on the (adaptive, per-round, per-client) clipping threshold . A corrected, explicit derivation for variable and is needed.
- Subsampling model mismatch: The privacy analysis relies on RDP bounds for the Sampled Gaussian Mechanism, typically derived under Poisson subsampling. The algorithm description suggests fixed-size minibatches. Quantify the impact of without-replacement sampling and, if used, switch to the appropriate bounds.
- Privacy cost of the validation-triggered scheduler: Clarify whether the validation/verification set used to compute is public. If private, include its DP cost and composition in the accountant; if public, justify representativeness and lack of leakage.
- Post-processing claim for adaptive clipping: Explicitly prove that computing from a previous DP output (itself built using and ) does not introduce circular dependencies invalidating post-processing, and quantify any additional privacy cost for initializing .
- Initialization details and budget use: The method initializes via “training on random noise for one round.” Specify whether this consumes privacy budget, how it’s performed, and its impact on early-stage utility and DP guarantees.
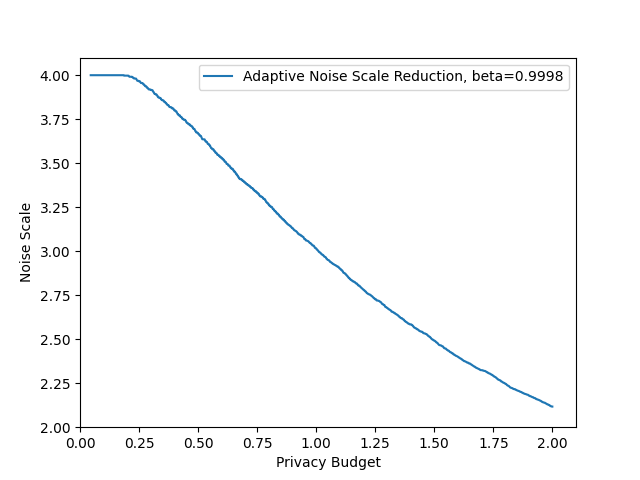
- Sensitivity of results to hyperparameters: No systematic sensitivity analysis is provided for the clipping factor , noise decay factor , initial noise scale , lot size , and learning rate. Provide tuning guidance, robustness ranges, and their effect on both privacy and utility.
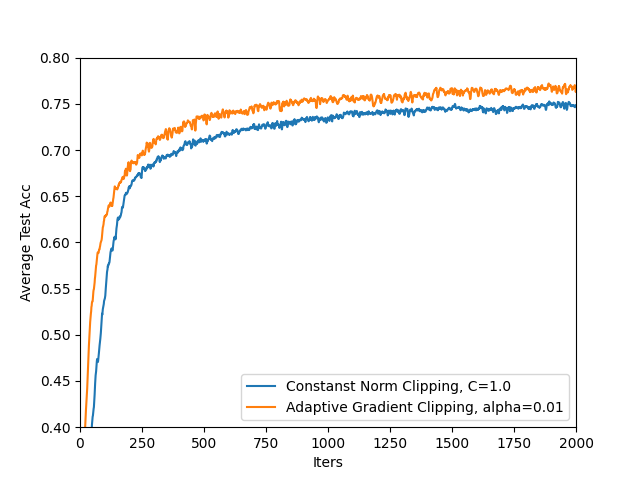
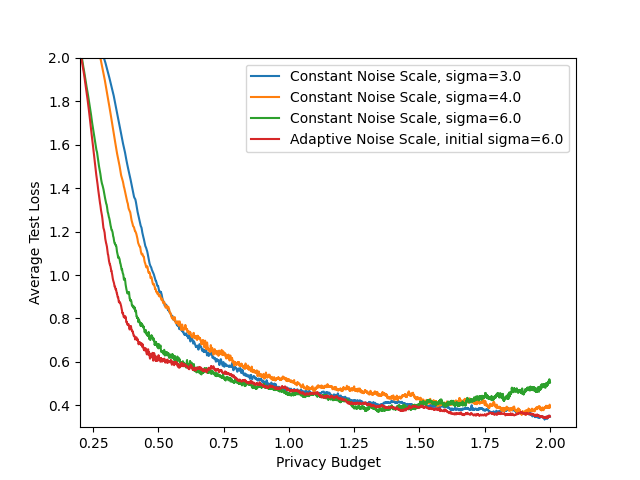
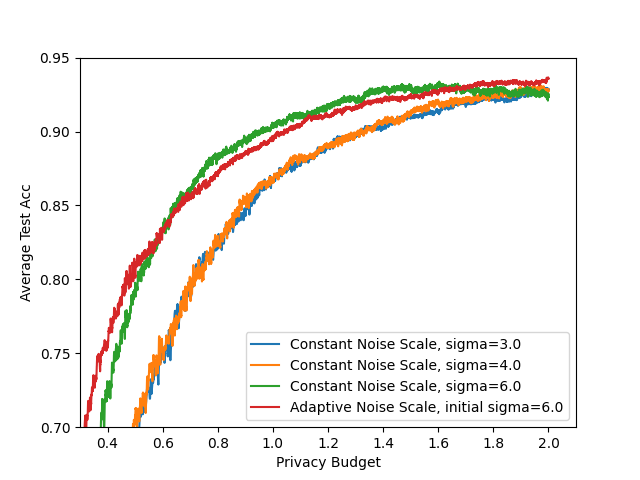
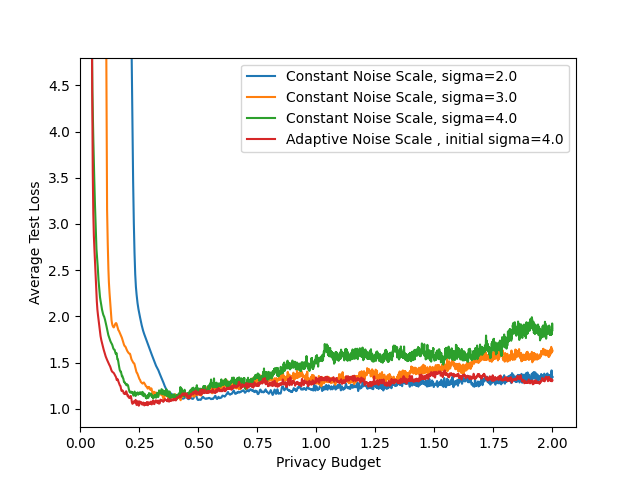
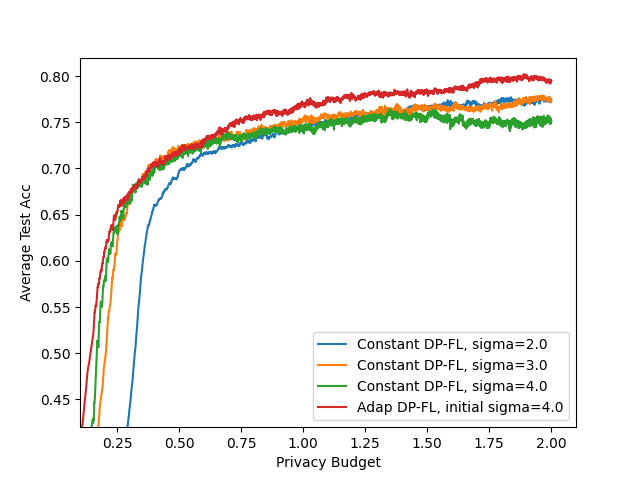
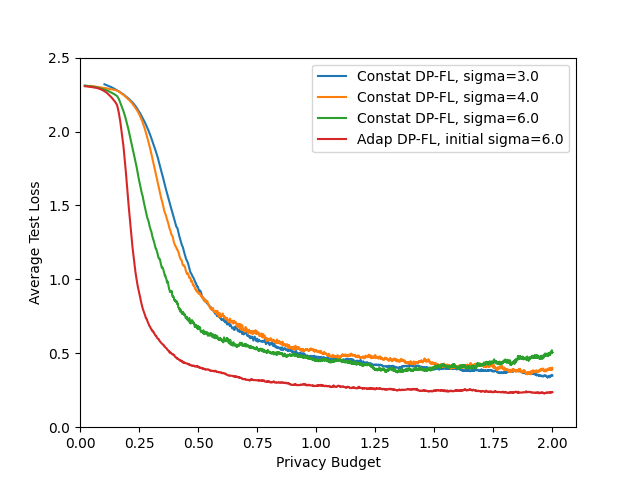
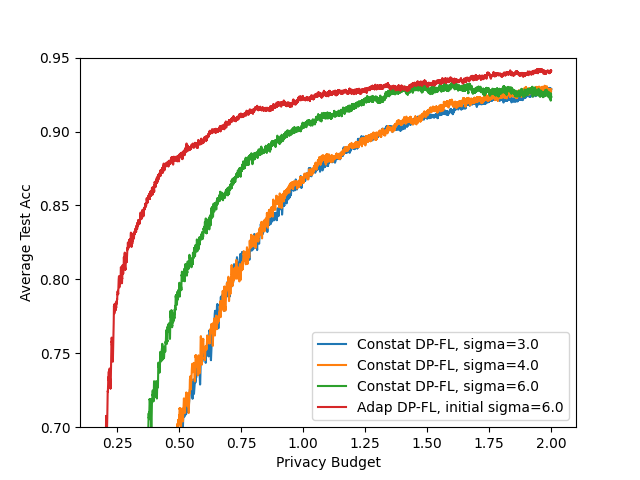
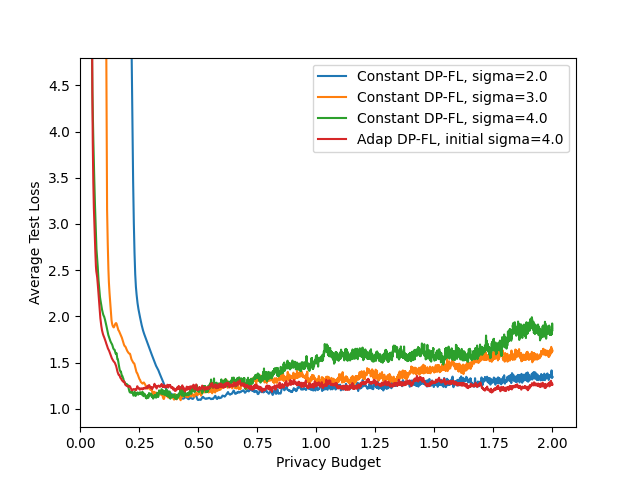
- Privacy-utility tradeoff curves: Results are shown mainly at . Report comprehensive privacy-utility curves across a range of and multiple values to understand general trends and practitioner choices.
- Client heterogeneity in privacy parameters: The privacy analysis assumes identical and for all clients, while clipping thresholds are per-client and data-dependent. Provide per-client DP guarantees when clients have heterogeneous datasets, lot sizes, or adaptive parameters.
- Handling client dropout on budget exhaustion: The algorithm stops client updates once , but the impact of staggered client exits on convergence, accuracy, and fairness is not analyzed.
- Computational and memory overhead: Per-example gradients and per-client adaptive clipping can be expensive for larger models. Quantify runtime/memory overhead, and explore efficient implementations (e.g., microbatching, ghost norm/clip, vectorized per-example gradients).
- Scalability beyond small benchmarks: Experiments are limited to MNIST/FashionMNIST, 10 clients, and a shallow CNN. Evaluate on larger datasets (e.g., CIFAR-10/100), deeper models, more clients (100+), and more realistic non-IID federated settings.
- Robustness to non-IID severity and participation patterns: Only one non-IID partition scheme is tested with full participation. Study varying degrees of heterogeneity, partial participation, client sampling, stragglers, and cross-device settings.
- Comparative baselines: Compare against stronger or more recent baselines (e.g., AdaCliP, DP-FTRL, layer-wise/coordinate-wise adaptive clipping, central DP with secure aggregation, LDP-Fed), not only a single constant-noise baseline.
- Convergence theory: No theoretical convergence or excess risk guarantees are provided for the combination of adaptive clipping and decreasing noise under non-IID data. Provide conditions and bounds to complement empirical findings.
- Attack resilience evaluation: Empirically evaluate resistance to gradient inversion (DLG/iDLG), membership inference, and property inference under the proposed scheme and compare to baselines to validate privacy beyond formal guarantees.
- Fairness and client-level disparity: Adaptive clipping may bias updates from clients with smaller gradient norms or smaller datasets. Measure per-client accuracy/contribution disparities and explore fairness-aware variants.
- Overfitting/generalization under decreasing noise: Analyze whether late-stage low-noise updates increase overfitting or privacy risk; consider noise floors, early stopping, or DP-aware regularization.
- Scheduler robustness to noisy validation signals: The “three consecutive decreases” trigger is heuristic. Study its sensitivity to validation noise, oscillations, and non-monotonic loss, and compare to alternative schedules (e.g., cosine decay, exponential decay, patience-based thresholds).
- Choice of and practical implications: The paper defaults to or $1/|D|$. Justify this choice under different data scales and threat models, and analyze the utility impact of smaller/larger .
- Layer-wise vs norm-wise clipping: Only global per-example norm clipping is considered. Investigate layer-wise or coordinate-wise adaptive clipping in FL and their privacy/utility trade-offs.
- Client-specific noise schedules: The noise schedule is global (), while gradients and convergence rates are per-client. Explore client-specific schedules and how to privately coordinate them.
- Secure aggregation and threat model: The server is honest-but-curious, yet no secure aggregation or cryptographic protection is used. Assess whether secure aggregation could be combined with the method and its effect on privacy and utility.
- Communication efficiency: No analysis of communication rounds/bytes is provided. Explore compression, sparsification, or fewer rounds under DP to reduce bandwidth while preserving utility.
- Multiple local steps per round: The algorithm appears to use a single local step; many FL systems use multiple local epochs. Extend the privacy accountant to multiple local updates per round and evaluate its impact.
- Impact of class imbalance and label sparsity: The partitioning yields clients with 2–5 labels. Analyze how class imbalance affects adaptive clipping/noise and whether reweighting or per-class clipping is beneficial.
- Release of schedules and thresholds: Clarify what is revealed (e.g., , ) and whether releasing these values can leak training dynamics. Provide guidance on which metadata can be safely disclosed under DP.
- Reproducibility details: Key implementation choices (optimizer hyperparameters, exact sampling scheme, accountant parameters for RDP order selection, seeds) are insufficiently specified for rigorous replication; provide full config and code.
Collections
Sign up for free to add this paper to one or more collections.

