- The paper introduces GAPartNet, a dataset and method that leverages part-level abstraction to achieve cross-category, domain-generalizable object perception and manipulation.
- It proposes a Sparse UNet-based pipeline with domain adversarial training, multi-resolution features, and symmetry-aware loss functions to enhance part segmentation and pose estimation.
- Experimental results show significant improvements on both seen and unseen categories, enabling robust manipulations in simulation and real-world environments.
GAPartNet: Cross-Category Domain-Generalizable Object Perception and Manipulation via Generalizable and Actionable Parts
Introduction and Motivation
The paper introduces GAPartNet, a large-scale dataset and method for cross-category, domain-generalizable object perception and manipulation, focusing on the concept of Generalizable and Actionable Parts (GAParts). The central thesis is that part-level abstraction—rather than object category-level abstraction—enables more robust generalization in robotic perception and manipulation. GAParts are defined by both geometric similarity and actionability alignment, facilitating transfer of manipulation skills across diverse object categories.
GAPart Definition and Dataset Construction
GAPartNet comprises 1,166 articulated objects from 27 categories, annotated with 8,489 instances of 9 GAPart classes (e.g., line fixed handle, round fixed handle, hinge handle, hinge lid, slider lid, slider button, slider drawer, hinge door, hinge knob). Each part is annotated with semantic labels and canonicalized poses in Normalized Part Coordinate Space (NPCS), supporting both perception and manipulation tasks.
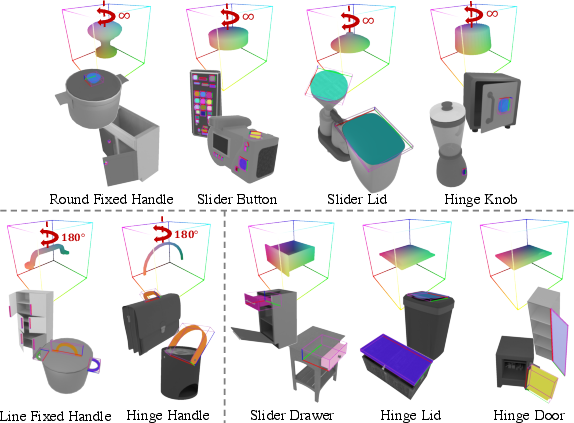
Figure 1: GAPart classes and their normalized part coordinate spaces, highlighting symmetry properties relevant for pose estimation.
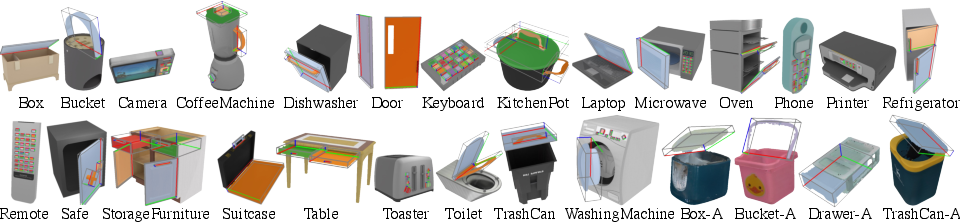
Figure 2: Representative objects from GAPartNet, illustrating the diversity of object categories and part types.
The dataset is constructed by cleaning and re-annotating meshes from PartNet-Mobility and AKB-48, ensuring consistent part semantics and pose annotations. The annotation pipeline includes mesh fixing, semantic labeling, and pose alignment, with significant manual effort to guarantee cross-category generalizability.
Domain-Generalizable Perception: Segmentation and Pose Estimation
Given a partial colored point cloud P∈RN×3, the goal is to segment each GAPart, assign its class label, and estimate its pose (Ri,ti,si) for all L parts. The perception model is trained on seen categories and evaluated on unseen categories, demanding domain generalization.
Methodology
The proposed pipeline leverages a Sparse UNet backbone for feature extraction, followed by mask proposal generation and scoring. Crucially, the method integrates domain adversarial training to learn domain-invariant features, addressing three key challenges:
- Context Invariance: Part-oriented feature query focuses the domain classifier on foreground part features, reducing context dependency.
- Size Variance: Multi-resolution feature extraction from different UNet layers accommodates the wide range of part sizes.
- Distribution Imbalance: Focal loss is employed in the domain adversarial loss to mitigate the effects of imbalanced part distributions.
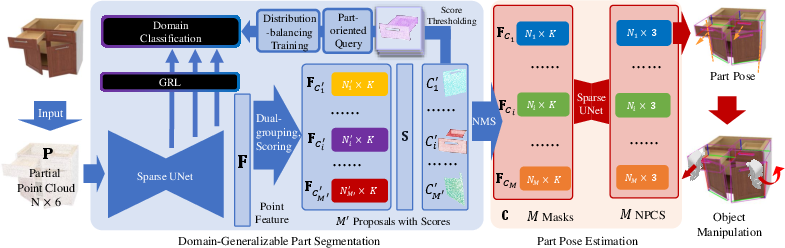
Figure 3: Overview of the domain-generalizable part segmentation and pose estimation pipeline, highlighting the part-oriented domain adversarial training strategy.
The final segmentation loss combines standard segmentation objectives with the domain adversarial loss, promoting domain-invariant GAPart feature learning.
Pose Estimation
For each segmented part, NPCS-Net regresses point-wise NPCS coordinates. RANSAC and the Umeyama algorithm are used for robust pose fitting. Symmetry-aware loss functions are designed to handle the intrinsic symmetries of different GAPart classes, improving pose estimation accuracy.
Experimental Results
Part Segmentation
On seen categories, the method achieves 76.5% AP50, outperforming PointGroup, SoftGroup, and AutoGPart baselines by 7.7–9.2% absolute and 11.2–13.1% relative margins. On unseen categories, the method achieves 37.2% AP50, a 6.7% absolute and 22% relative improvement over the best baseline.
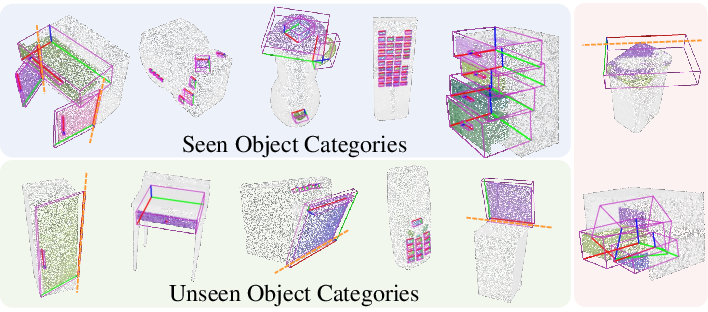
Figure 4: Qualitative results of cross-category part segmentation and pose estimation, including failure cases.
Ablation studies confirm the contribution of each technique (part-oriented query, multi-resolution, distribution-balancing) to generalization performance.
Part Pose Estimation
The method yields lower rotation, translation, and scale errors compared to baselines, with higher mIoU and pose accuracy on both seen and unseen categories. The domain-invariant feature extraction is shown to be critical for generalizable pose estimation.
Part-Based Manipulation
The paper demonstrates part-pose-based manipulation heuristics in both simulation and real-world settings. Tasks include opening drawers, doors, manipulating handles, and pressing buttons. The method achieves 90–100% success rates on seen categories and 55–95% on unseen categories, significantly outperforming Where2Act and ManiSkill baselines.

Figure 5: Part-based object manipulation results in simulation and real-world environments, showing perception outputs and target parts.
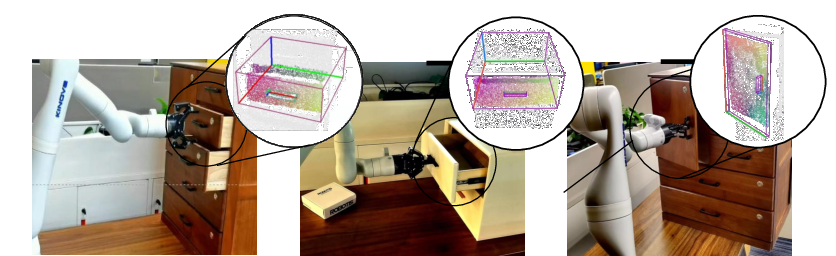
Figure 6: Additional qualitative results for part-based object manipulation in the real world.
Implications and Future Directions
The GAPart abstraction enables transfer of perception and manipulation skills across object categories, reducing the need for category-specific training and manual policy design. The domain adversarial training framework is shown to be effective for 3D part segmentation and pose estimation, suggesting broader applicability in other cross-domain 3D vision tasks.
The results indicate that part-level abstraction is a promising direction for generalizable robotic manipulation. However, the reliance on precise pose estimation and heuristic policies highlights the need for further research into robust manipulation strategies, especially for outlier part shapes and challenging real-world sensing conditions.

Figure 7: Exemplar objects of each GAPart class from seen and unseen categories, visualizing segmentation masks and poses.
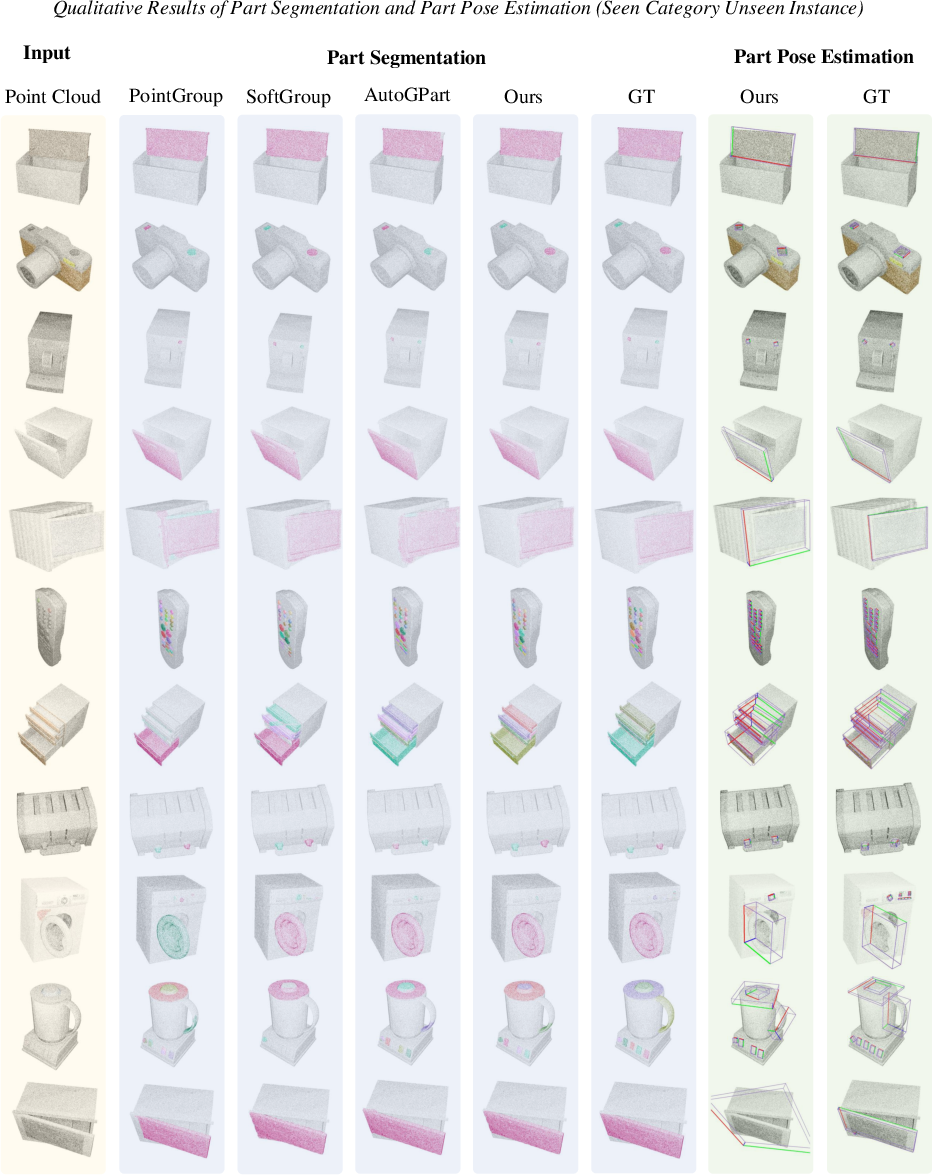
Figure 8: Segmentation and pose estimation results on unseen instances from seen categories, comparing GAPartNet to baselines.

Figure 9: Segmentation and pose estimation results on unseen instances from unseen categories, demonstrating cross-category generalization.

Figure 10: Segmentation and pose estimation results on real-world unseen objects, validating sim-to-real transfer.
Conclusion
GAPartNet establishes a new paradigm for cross-category, domain-generalizable object perception and manipulation by focusing on generalizable and actionable parts. The dataset, domain adversarial training framework, and manipulation heuristics collectively enable robust transfer of skills to unseen object categories and real-world scenarios. The work provides a foundation for future research in part-centric perception, pose estimation, and manipulation, with potential extensions to reinforcement learning and more advanced policy learning leveraging part-level abstractions.

