- The paper demonstrates that aggregating human labels into a single ground truth can obscure inherent subjectivity and annotation ambiguity.
- It introduces innovative methodologies that leverage un-aggregated, annotator-level data to improve model training and interpretability.
- The authors advocate for revising evaluation practices by incorporating soft metrics like cross-entropy and Kullback-Leibler divergence to reflect label variability.
Human Label Variation in Machine Learning: An Overview
Introduction
The concept of human label variation (Hlv) presents a critical challenge in ML, particularly within the realms of NLP and computer vision (CV). This paper, titled "The 'Problem' of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation" (2211.02570), addresses an often-overlooked aspect of ML: the assumption of a singular ground truth. The conventional ML pipeline—comprising data collection, modeling, and evaluation—typically aggregates human labels to derive a gold standard, thereby neglecting the inherent variation in human annotation. This oversight can impact the entire ML lifecycle, necessitating a reevaluation of how we view and utilize human label data.
Data and Human Label Variation
The foundation of any ML system is its data, which must be both valid and reliable. However, research has revealed that disagreements between annotators, even in seemingly objective tasks, can be quite prevalent. The paper defines Hlv as plausible annotation variation rather than simple disagreement, which implies incompatibility of views. In contrast, Hlv acknowledges factors such as subjectivity, genuine disagreement, and ambiguity, which can all result in multiple plausible annotations.
To address this, the paper advocates for the collection and release of un-aggregated, annotator-level data, inclusive of metadata such as annotator background and annotation process documentation. The authors highlight the increased availability of datasets featuring multiple annotations, underscoring the potential for these resources to inform more nuanced understanding of ML model behavior and limitations.
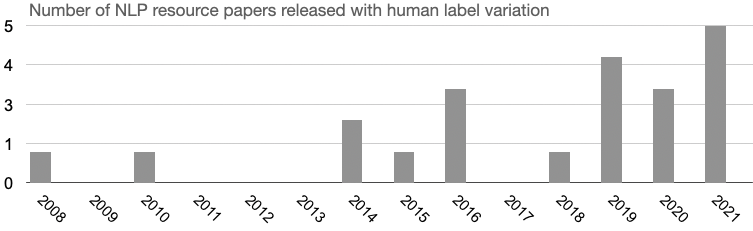
Figure 1: NLP Resource papers per publication year, counting publicly-available datasets released with human label variation.
Modeling and Human Label Variation
In terms of modeling, the paper categorizes existing methodologies into those that resolve Hlv and those that embrace it. Traditional methods, such as aggregation (e.g., majority voting) and filtering, attempt to address Hlv by consolidating it into a single label or discarding low-agreement data. However, these approaches can result in the loss of valuable information.
Emerging approaches aim to leverage Hlv by integrating un-aggregated labels directly into the learning process or by enriching models with human label variation data. This includes techniques such as repeated labeling and soft-label multi-task learning. Despite the promise shown in areas like CV, the adoption of these methods is still nascent within NLP, highlighting a need for comprehensive evaluations and explorations of task-specific properties that could influence method suitability.
Evaluation and Human Label Variation
Evaluation practices in ML, NLP, and CV predominantly rely on accuracy metrics against a singular ground truth. However, this approach is insufficient for tasks characterized by Hlv, as it fails to provide insight into model reasoning, confidence, and trustworthiness. The paper points to the necessity of moving beyond hard labels in evaluation and adopting soft metrics that consider human label distributions, such as cross-entropy and Kullback-Leibler divergence.
The authors also highlight the disparity between in-vitro (laboratory) and in-vivo (real-world) performance, stressing the importance of soft evaluation metrics that can better reflect this dynamic. This calls for an overhaul of standard evaluation practices to incorporate a broader array of metrics that accommodate the complexities introduced by Hlv.
Conclusions
The paper articulates a forward-looking view on Hlv, framing it as an opportunity to innovate across data collection, modeling, and evaluation within ML pipelines. By advocating for an interdisciplinary discourse and the incorporation of comprehensive Hlv frameworks, the authors set the stage for more inclusive and trustworthy AI systems. Their contributions, including a repository of datasets [https://github.com/mainlp/awesome-human-label-variation], are intended to spearhead discussions and encourage broader adoption of practices that acknowledge the multifaceted nature of human label data.
In conclusion, the recognition and integration of Hlv into the ML pipeline can lead to advancements in model robustness, calibration, and ultimately, applicability in diverse and real-world scenarios. As the field progresses, the continued exploration of Hlv-driven methodologies holds the potential to redefine how AI interacts with the nuanced and subjective dimensions of human cognition.

