- The paper presents an unsupervised method that segments lecture videos by deriving joint text-video embeddings with a TW-FINCH clustering algorithm.
- It leverages self-supervised learning to align narration with visual content, outperforming traditional baselines in key metrics like NMI, MoF, IoU, and Boundary Scores.
- The AVLectures dataset, consisting of 2,350 lectures across 86 courses, enriches research by offering diverse multimodal data including transcripts, OCR outputs, and slides.
Unsupervised Audio-Visual Lecture Segmentation
Introduction
The paper presents an approach to segment online lecture videos into smaller topics in an unsupervised manner, addressing the growing need for efficient navigation tools in the educational domain. The researchers introduce a large-scale dataset named AVLectures, aimed at facilitating research in understanding audio-visual lectures and automatic segmentation. The proposed methodology leverages self-supervised learning to derive multimodal representations by matching narration with temporally aligned video content, and performs segmentation using TW-FINCH, a clustering algorithm adept at maintaining temporal consistency.

Figure 1: We address the task of lecture segmentation in an unsupervised manner. We show an example of a lecture segmented using our method. Our method predicts segments close to the ground truth. Note that our method does not predict the segment labels, they are only shown so that the reader can appreciate the different topics.
AVLectures Dataset
AVLectures is composed of 2,350 lectures spanning over 86 courses and STEM subjects. This dataset is enriched with multimodal elements such as video lectures, transcripts, OCR outputs, lecture notes, and slides. It forms the backbone for analyzing the proposed lecture segmentation method, with the aim to ignite further research in educational applications.
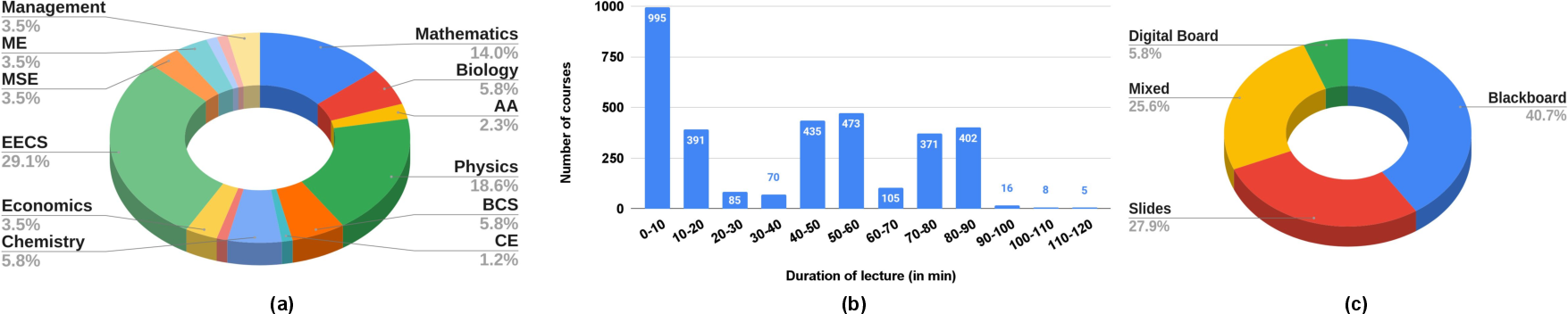
Figure 2: AVLectures statistics. (a) Subject areas. ME: Mechanical Eng., MSE: Materials Science and Eng., EECS: Electrical Eng. and Computer Science, AA: Aeronautics and Astronautics, BCS: Brain and Cognitive Sciences, CE: Chemical Eng. (b) Lecture duration distribution. (c) Presentation modes distribution.
Segmentation Methodology
The segmentation pipeline consists of three stages: feature extraction, joint text-video embedding, and clustering via TW-FINCH. During feature extraction, visual and textual information is derived from video frames using pre-trained models, including OCR API and ResNet-based models for 2D and 3D features. The self-supervised learning of joint embeddings aligns narration and video through a context-gated model, improving upon traditional methods by encoding temporal proximity within clip-level clusterings using TW-FINCH.
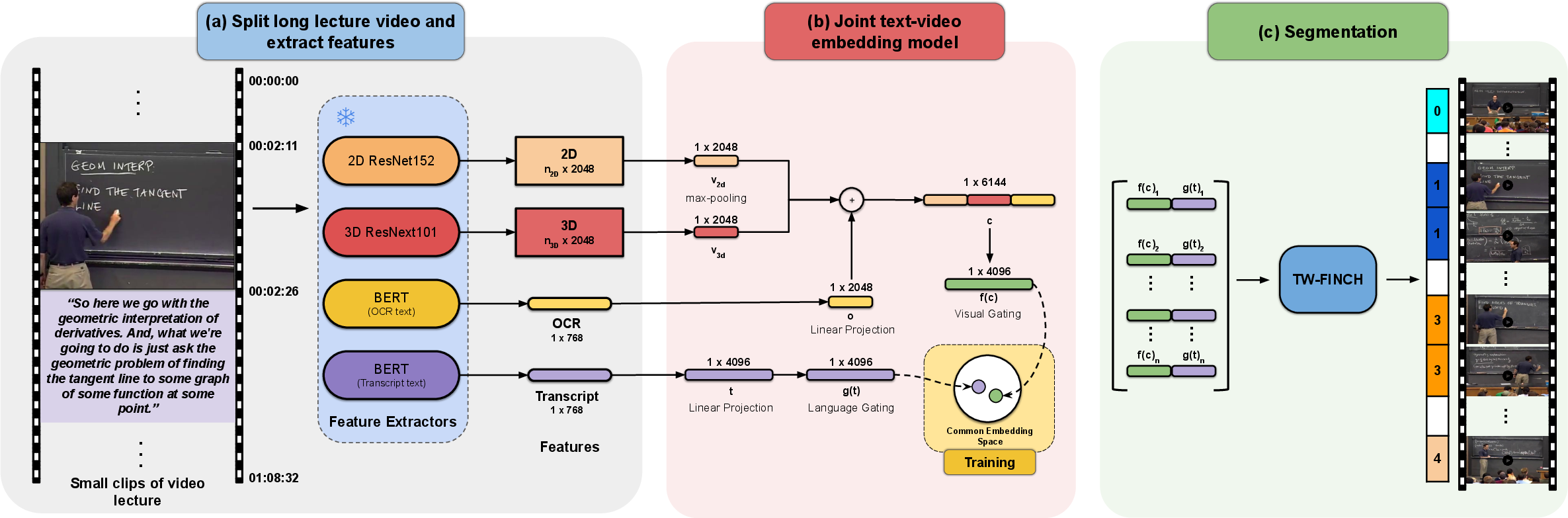
Figure 3: Segmentation pipeline. (a) Video clip and feature extraction pipeline used to extract visual and textual features from small clips of 10s-15s duration. The feature extractors are frozen and are not fine-tuned during the training process. (b) Joint text-video embedding model learns lecture-aware representations. (c) Lecture segmentation process, where we apply TW-FINCH at a clip-level to the learned (concatenated) visual and textual embeddings obtained from (b).
Experimental Results
The proposed method outperforms several baselines including visual-based and textual-based segmentation techniques by leveraging the joint embeddings. Evaluations demonstrate superior performance in Normalized Mutual Information (NMI), Mean over Frames (MoF), Intersection over Union (IoU), and Boundary Scores. Ablation studies reveal the robustness of the learned features, independent of embedding dimensions, and highlight the efficacy of larger clip durations for meaningful segmentation tasks.
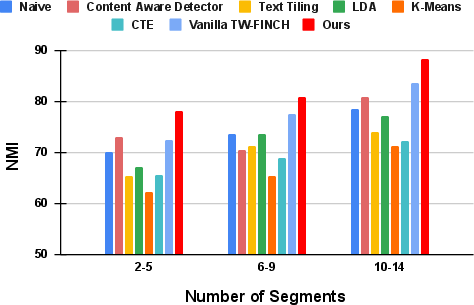
Figure 4: Comparing NMI across all methods grouped by the number of ground-truth segments.
Text-to-Video Retrieval
Beyond segmentation, the paper explores text-to-video retrieval using the learned embeddings. The model retrieves relevant lecture clips based on textual queries, showcasing its ability to correlate visual and textual data effectively, enhancing the utility of the AVLectures dataset for broader educational tasks.

Figure 5: Examples of text-to-video retrieval for different queries using our learned joint embeddings. Our model is able to retrieve relevant lecture clips based on the query.
Conclusion
The approach provides a robust, unsupervised means of segmenting lecture videos, offering vital contributions in terms of dataset and methodology. The AVLectures dataset opens numerous avenues for further educational research, potentially transforming online learning experiences through automatic content understanding and navigation. Future developments could include extending the task beyond segmentation to automated quiz generation and lecture summarization, leveraging multimodal embedding strategies for more comprehensive educational tools.

