- The paper introduces CQT-Diff, a diffusion model that preconditions on an invertible Constant-Q Transform to address various audio inverse problems.
- It demonstrates effective restoration across tasks like bandwidth extension, long audio inpainting, and declipping using both objective metrics and subjective listening tests.
- The flexible U-Net architecture, enhanced with dilated convolutions and FiLM modulations, exploits pitch equivariance to improve audio generative capacity.
Solving Audio Inverse Problems with a Diffusion Model
Introduction
The paper presents CQT-Diff, a neural diffusion model designed to address a variety of audio inverse problems, including bandwidth extension, inpainting, and declipping, using a problem-agnostic approach. CQT-Diff leverages pitch-equivariant symmetries intrinsic to music by preconditioning the model with an invertible Constant-Q Transform (CQT). This enables the translation equivariance in the pitch domain to be exploited, facilitating an effective and flexible audio restoration framework.
CQT-Diff Framework
CQT-Diff utilizes score-based generative modeling to reverse a diffusion process that transforms data progressively into Gaussian noise. The reverse diffusion process is controlled by a stochastic differential equation (SDE), where the underlying score function is estimated with a deep neural network. This framework is flexible in that it allows for audio restoration tasks to be addressed without retraining the model for specific degradations, relying instead on the conditioning of observations through data consistency and reconstruction guidance techniques.
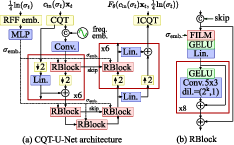
Figure 1: Diagram of the neural network architecture adapted for the CQT domain.
Architecture Design
The architecture of CQT-Diff is built upon a U-Net structure, where only the time resolution is modified during processing, supporting efficient handling of harmonic structures in music. Dilated convolutions are used to manage frequency dependencies, accompanied by FiLM modulations incorporating frequency positional embeddings. The neural network operates within the CQT domain, enabling the network to leverage pitch equivalence in musical signals, thus enhancing the generative capacity in audio modeling.
Experimental Evaluation
The efficacy of CQT-Diff is demonstrated across three audio restoration tasks:
- Bandwidth Extension: The generative nature of CQT-Diff avoids issues of filter generalization seen in previous methods. Objective metrics reported indicate superiority over both SashiMi-Diff and STFT-Diff configurations, with subjective listening tests supporting its high perceptual quality across different cutoff frequencies.
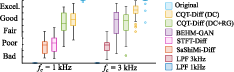
Figure 2: Results of the bandwidth extension listening test.
- Long Audio Inpainting: Similarly, CQT-Diff applies reconstruction guidance significantly improving performance over data consistency alone. The inclusion of long-range data dependencies, missing in the U-Net architecture, is compensated by reconstruction guidance, ensuring coherent signal restoration.
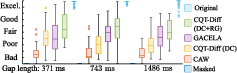
Figure 3: Results of the audio inpainting listening test.
- Audio Declipping: Performance in declipping tasks underscores the advantage diffusion models possess in handling low SDR scenarios, offering higher fidelity restoration compared to traditional declipping methods.
Implications and Future Work
The paper underscores the flexibility of CQT-Diff being adaptable to a range of audio processing tasks without requiring retraining, showcasing competitive results even in tasks beyond the main evaluated scope like declipping. The potential extension to broader audio restoration applications is suggested, with the necessity to address large-scale data training constraint highlighting future work. The use of CQT as an effective inductive bias in generative modeling for audio processing represents a compelling approach but warrants further empirical exploration to substantiate performance claims.
Conclusion
CQT-Diff presents an innovative approach to solving audio inverse problems, utilizing diffusion models preconditioned by CQT. Its design offers versatility in tackling various audio restoration tasks with impressive subjective and objective evaluation results. Future directions involve exploring the model's application towards accommodating broader audio restoration challenges and enhancing training scalability.