- The paper presents ReasTAP, a novel pre-training method that injects table reasoning skills by generating synthetic QA examples over tables.
- It defines seven distinct reasoning skills and models the task as sequence generation, achieving state-of-the-art results on Table QA, Fact Verification, and Table-to-Text tasks.
- Empirical evaluations show improved scalability and robust performance, especially in low-resource settings, compared to traditional pre-trained models.
ReasTAP: Enhancing Table Reasoning Skills through Pre-training with Synthetic Examples
Introduction
The paper "ReasTAP: Injecting Table Reasoning Skills During Pre-training via Synthetic Reasoning Examples" (2210.12374) introduces a novel approach to pre-training models for table-based reasoning tasks. This approach, termed ReasTAP, focuses on enhancing the ability of LLMs to perform high-level table reasoning by pre-training them to handle synthetic question-answer (QA) examples generated over tables. By defining and implementing a series of table reasoning skills, ReasTAP eliminates the need for complex table-specific architectures, thus simplifying the model training process.
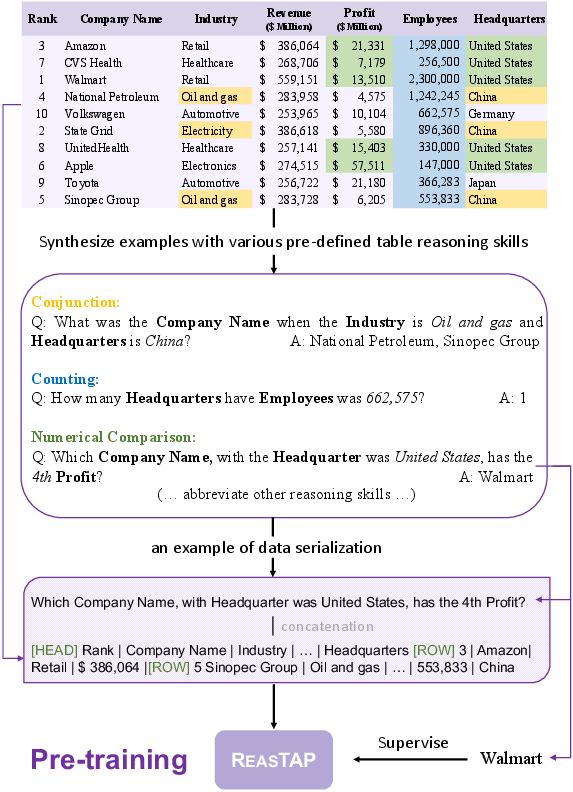
Figure 1: The illustration of ReasTAP pre-training with example generation for different table reasoning skills.
Pre-training Methodology
ReasTAP approaches table reasoning by initially defining seven distinct table reasoning skills, including numerical operations, temporal comparisons, and conjunctions. For each skill, an example generator is developed to synthesize QA pairs over tables using predefined templates. These examples are used to model the pre-training task as a sequence generation problem, where the objective is to generate correct answers given a flattened table and a synthetic query.
The pre-training corpus is constructed using semi-structured tables extracted from a large-scale Wikipedia dump. The tables are pre-processed by shuffling rows to mitigate bias towards row order, ensuring the model learns true table reasoning rather than memorizing specific patterns. The synthetic QA examples are categorized and sampled according to the prevalence of different reasoning skills within the dataset, ensuring a balanced pre-training process.
Downstream Applications
ReasTAP's effectiveness is evaluated on multiple downstream tasks, including Table Question Answering (QA), Table Fact Verification, and Faithful Table-to-Text Generation. Notably, these tasks encompass datasets such as WikiSQL-Weak, WikiTQ, TabFact, and LogicNLG.
Table QA
In Table QA tasks, models must interpret questions and retrieve or compute answers from provided tabular data. ReasTAP shows significant improvements over existing pre-trained models, achieving state-of-the-art performance on datasets with complex reasoning requirements.
Table Fact Verification
For fact verification tasks, ReasTAP demonstrates enhanced ability to verify the truth of statements based on table data. This is validated on the TabFact dataset, where ReasTAP outperforms previous models, particularly in examples requiring intricate reasoning.
Faithful Table-to-Text Generation
ReasTAP also shows an edge in generating natural language descriptions from tables, ensuring logical consistency and high fluency. The improvements in SP-Acc and NLI-Acc scores on the LogicNLG dataset indicate its superior performance in maintaining logical fidelity.
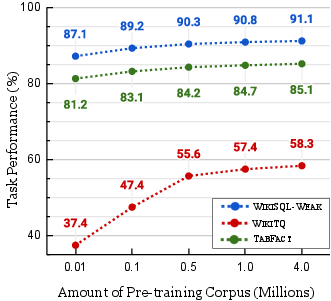
Figure 2: ReasTAP performance on various downstream tasks with different pre-training corpus scales.
The research further explores ReasTAP's performance in low-resource settings, demonstrating substantial improvements over BART, especially with limited training data. Analysis of pre-training corpus scales reveals that larger corpora benefit complex tasks, indicating the scalability of ReasTAP's pre-training approach.
The necessity of specific reasoning skills is validated by assessing the impact of their omission on model performance, with skills like counting and temporal comparison contributing significantly to overall task proficiency. Additionally, multi-task fine-tuning experiments show that while ReasTAP benefits from multi-task learning, its pre-training largely encapsulates necessary reasoning skills.
ReasTAP distinguishes itself from other table pre-training approaches by focusing on reasoning skill injection rather than complex model architectures or recovery-based pre-training objectives like those seen in TaBERT and TaPas. Its innovative use of a sequence generation framework for pre-training, along with the use of synthetic data, sets a new standard in table reasoning capabilities in LLMs.
Conclusion
ReasTAP is a significant advancement in pre-training models for table reasoning tasks. By effectively injecting reasoning skills into the pre-training process, it achieves substantial improvements across various benchmarks without relying on complex architectural designs. Future work could explore expanding the set of reasoning skills, integrating hierarchical tables, and leveraging more efficient training frameworks. Through its innovative approach, ReasTAP sets the stage for deploying more capable and flexible table reasoning models.

