- The paper proposes a transformer-based model that fuses multi-modal data to enhance sequential recommendation tasks.
- It integrates data2vec-generated embeddings from text, images, and tabular data, significantly boosting NDCG scores.
- Experiments on Amazon Fashion and ML-20M datasets validate the model's superior performance over conventional systems.
This essay summarizes the paper "Multi-Modal Recommendation System with Auxiliary Information" (2210.10652), which investigates the integration of multi-modal auxiliary data into context-aware recommender systems utilizing advanced transformer architectures. The paper proposes enhancing the sequential recommendation task by incorporating structured and unstructured data representations, thereby improving prediction accuracy.
Introduction
The paper addresses the challenges in context-aware recommendation systems, emphasizing the potential benefits of utilizing auxiliary information beyond sequential item ordering. It explores extracting vector embeddings from diverse data types using data2vec, merging these embeddings, and utilizing them within transformer architectures to improve user-item representation learning. The proposed model, which includes multi-modal auxiliary information, reports significant improvements in NDCG scores for both long and short user sequence datasets.
The use of multi-modal auxiliary data marks a significant enhancement over conventional methods, which primarily focus on item identifiers or tabular data. This paper incorporates vector embeddings of both structured and unstructured data, including text, images, and continuous tabular data, into the recommendation model. The study utilizes data2vec to produce unified embeddings from unstructured data sources.
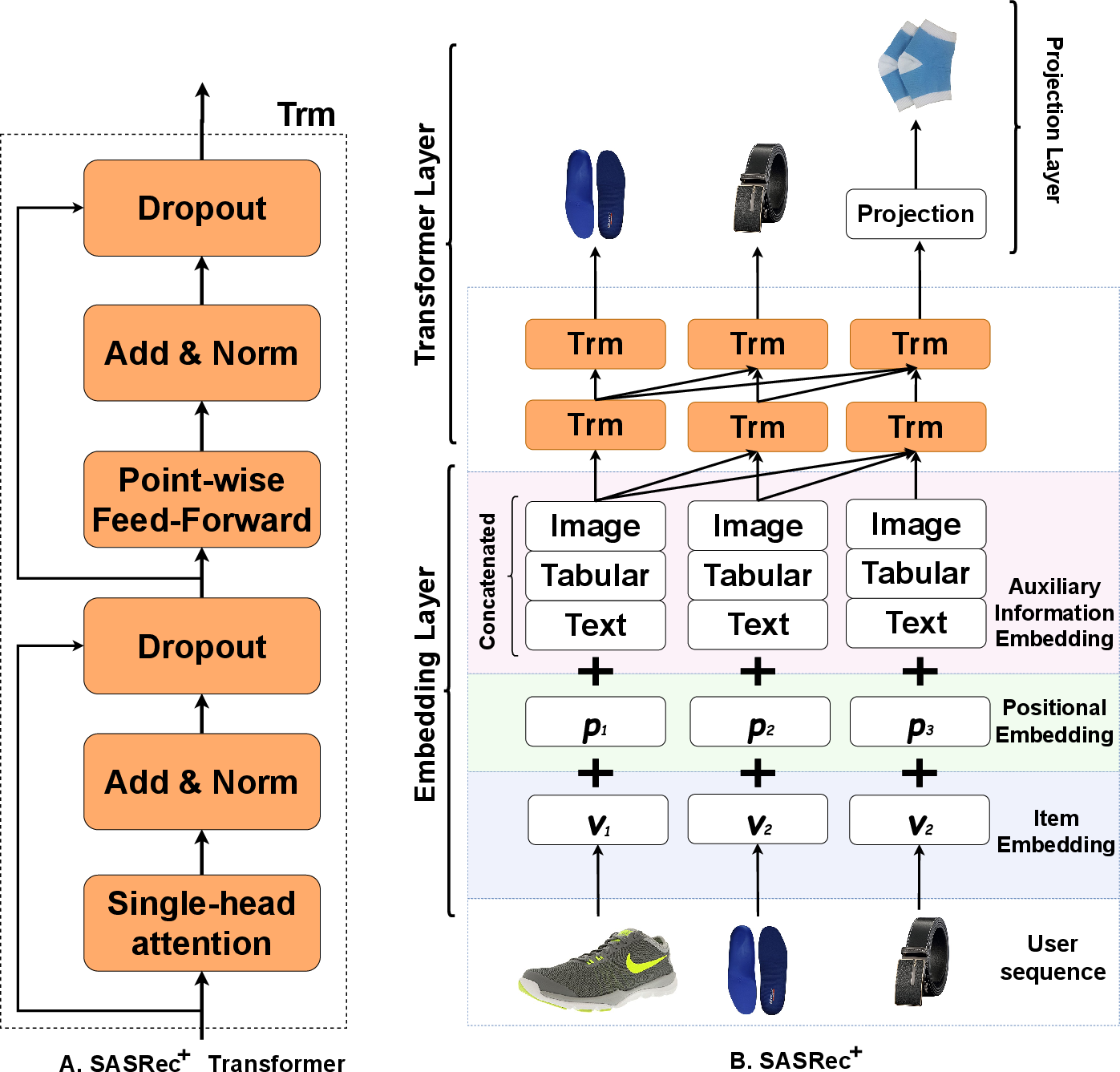
Figure 1: The SASRec+ architecture with the inclusion of multi-modal auxiliary information embedding.
The paper evaluates both unidirectional and bidirectional transformers, SASRec and BERT4Rec, respectively, for modeling sequential dependencies. SASRec effectively captures user-item interactions in sequential order with single-head self-attention, whereas BERT4Rec uses multi-head self-attention to process information bidirectionally. The inclusion of auxiliary information through the concatenation of embeddings enhances the model's capability to retain item-specific features.
Experimental Methodology
The paper conducts experiments using the Amazon Fashion and ML-20M datasets to validate the proposed approach. These datasets provide diverse consumption patterns and auxiliary information, enabling a robust assessment of the model's performance in real-world scenarios. The evaluation uses performance metrics such as HR@N, NDCG@N, and MAP to quantify the improvements in recommendation accuracy.
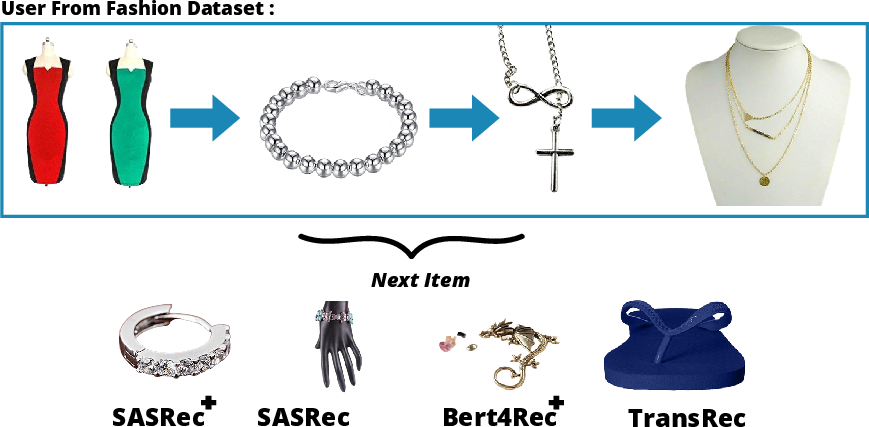
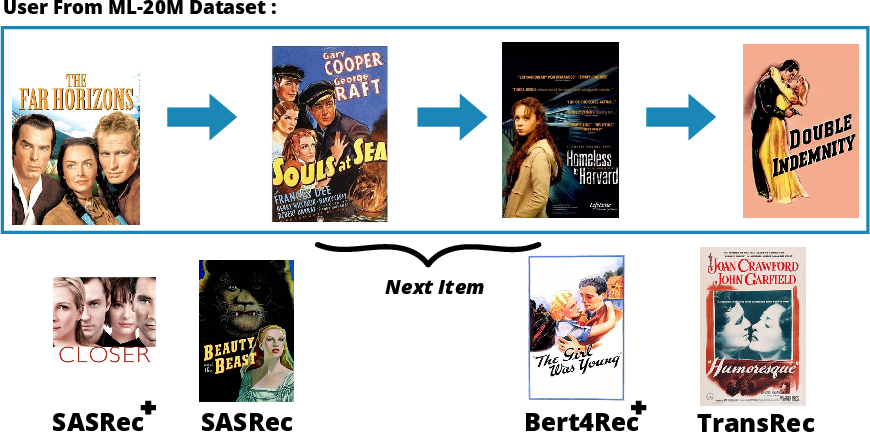
Figure 2: A sample of two users' historical consumption of items and the predicted next item by each model.
Results
The experimental results exhibit a clear advantage in accuracy metrics when incorporating multi-modal auxiliary information. The SASRec+ model consistently outperforms baseline models, demonstrating a substantial increase in NDCG scores—4% and 11% for ML-20M and Fashion datasets, respectively—highlighting the model's effectiveness in leveraging rich contextual embeddings.
Ablation Study
An ablation study further scrutinizes the impact of individual modalities and their combinations within the recommendation model. The findings suggest that datasets with shorter sequence lengths benefit more from single modality embedding, while concatenated embeddings prove superior for longer sequences.
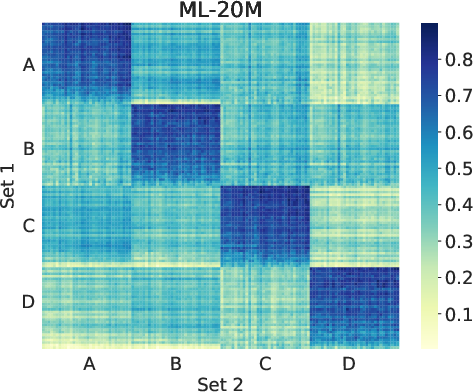
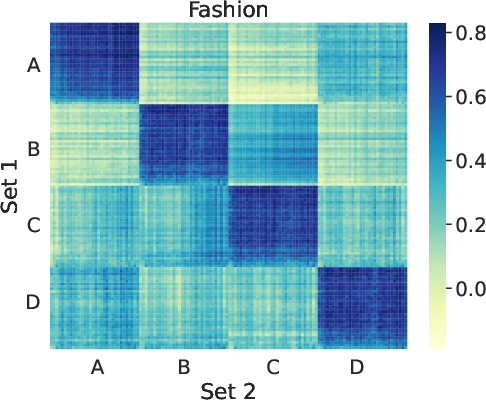
Figure 3: Heatmaps of the similarity scores between two sets of user's average attention weights.
Conclusion
The paper successfully elevates the context-aware recommendation system by integrating multi-modal auxiliary information. The empirical analysis validates that leveraging comprehensive multi-modal datasets enhances user behavior modeling and prediction accuracy. Future research is encouraged to explore finer granularity within embeddings and alignment between modalities. The study's contributions extend beyond recommendation systems, offering insights into efficient multi-modal data fusion techniques.