- The paper introduces POLA as a proximal operator reinterpretation of LOLA, achieving parameterization invariance for more reliable reciprocity-based cooperation.
- It leverages outer POLA and POLA-DiCE approximations to provide tractable, first-order updates with unbiased gradient estimation in high-dimensional settings.
- Experiments in iterated prisoner's dilemma and coin games demonstrate POLA’s superior performance and scalability compared to the original LOLA algorithm.
Proximal Learning With Opponent-Learning Awareness
Introduction
The paper "Proximal Learning With Opponent-Learning Awareness" introduces Proximal Learning with Opponent-Learning Awareness (POLA), a novel algorithmic framework designed to address limitations of the Learning With Opponent-Learning Awareness (LOLA) algorithm in multi-agent reinforcement learning (MARL) settings. While LOLA is known to facilitate cooperation in simple social dilemmas, it struggles with neural network-parameterized policies due to sensitivity to policy parameterization. POLA addresses this by reinterpreting LOLA as an approximation of a proximal operator, thus achieving parameterization invariance and improving reliability in learning reciprocity-based cooperation.
Theoretical Developments
At its core, POLA is developed by framing LOLA within proximal algorithms, which are gradient-based optimization techniques renowned for their robustness to parameterization changes. The paper derives POLA updates using proximal formulations that incorporate penalty terms to maintain proximity in the policy space, thus ensuring that behaviorally equivalent policies result in behaviorally equivalent updates. This formulation is particularly advantageous in opponent modeling scenarios where the opponent's policy is not directly observable and must be inferred from interactions.
Practical Approximations of POLA
Given the impracticality of exact POLA updates, the paper presents tractable algorithms: outer POLA and POLA-DiCE. Outer POLA simplifies the original formulation by employing first-order approximations for computational feasibility. POLA-DiCE further adapts these techniques to environments requiring policy gradient methods with rollouts, leveraging DiCE for unbiased gradient estimation in high-dimensional spaces.
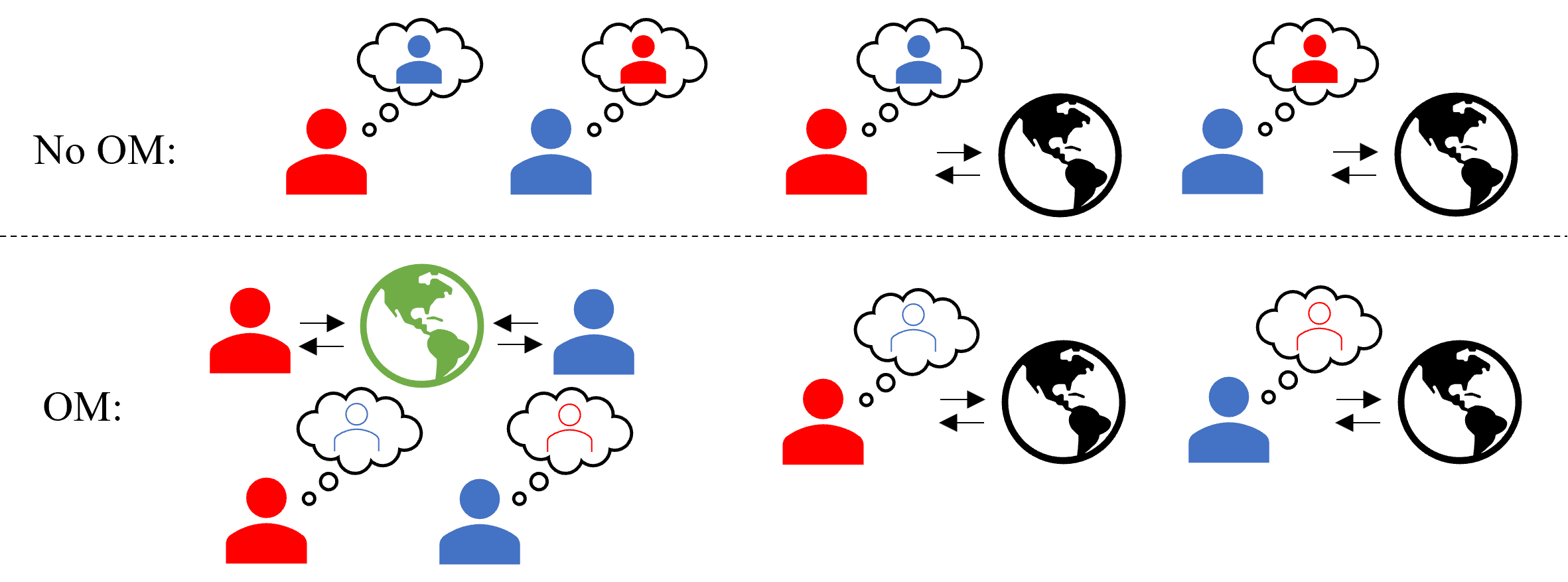
Figure 1: Illustration of the training process at each time step for LOLA-DiCE and POLA-DiCE.
Experimental Analysis
The paper rigorously evaluates POLA in various MARL scenarios, including the iterated prisoner's dilemma (IPD) and the coin game. These experiments highlight POLA's superior performance relative to LOLA in achieving reciprocity-based cooperation across different parameterizations, demonstrating its robustness and scalability in function approximation contexts.
- One-Step Memory IPD: POLA consistently finds tit-for-tat (TFT) strategies with both tabular and neural network policies, unlike LOLA which fails when policy parameterizations vary significantly.
- Full Action History IPD: Utilizing GRUs for parameterization, POLA-DiCE agents show a high probability of mutual cooperation while defecting against non-cooperative opponents, maintaining robustness even with opponent modeling.
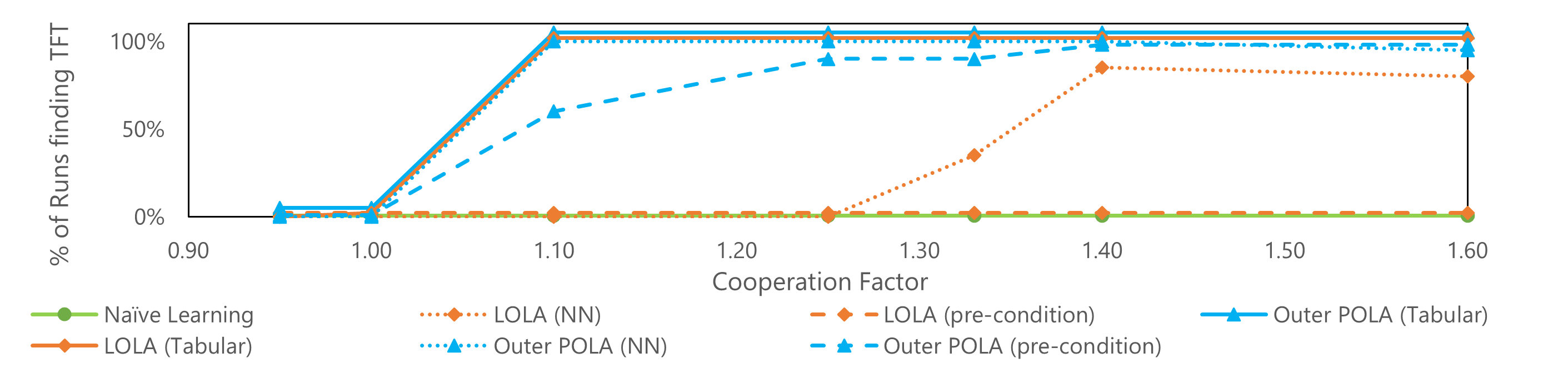
Figure 2: Comparison of LOLA and outer POLA in the one-step memory IPD.
- Coin Game: In a high-dimensional observation setting, POLA-DiCE significantly outperforms LOLA-DiCE, achieving near-optimal levels of cooperation while using opponent modeling effectively.
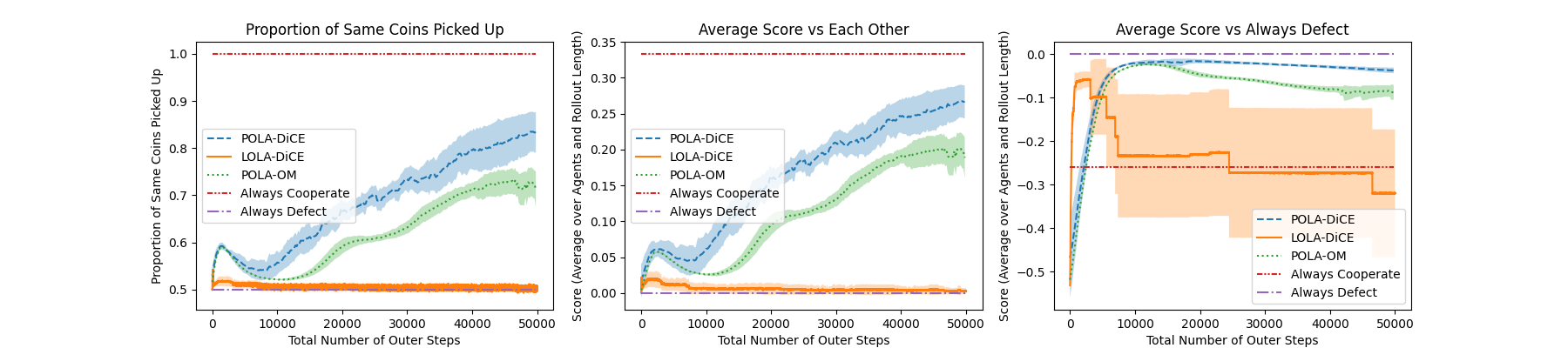
Figure 3: Comparison of LOLA-DiCE and POLA-DiCE on the coin game.
Implications and Future Work
POLA's invariance to policy parameterization opens new avenues for deploying opponent shaping algorithms in more complex MARL environments. Future research could explore extensions to three or more agents, performance in larger-scale cooperative scenarios, and adaptations that enhance sample efficiency.
Conclusion
The introduction of POLA represents a significant step towards robust, parameterization-invariant cooperative learning in MARL. By addressing the limitations inherent in LOLA, POLA sets the stage for more reliable and scalable solutions in environments demanding intricate strategic interactions among autonomous agents.
