Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning
Published 11 Oct 2022 in cs.LG and cs.AI | (2210.05158v2)
Abstract: Behavioral cloning (BC) provides a straightforward solution to offline RL by mimicking offline trajectories via supervised learning. Recent advances (Chen et al., 2021; Janner et al., 2021; Emmons et al., 2021) have shown that by conditioning on desired future returns, BC can perform competitively to their value-based counterparts, while enjoying much more simplicity and training stability. While promising, we show that these methods can be unreliable, as their performance may degrade significantly when conditioned on high, out-of-distribution (ood) returns. This is crucial in practice, as we often expect the policy to perform better than the offline dataset by conditioning on an ood value. We show that this unreliability arises from both the suboptimality of training data and model architectures. We propose ConserWeightive Behavioral Cloning (CWBC), a simple and effective method for improving the reliability of conditional BC with two key components: trajectory weighting and conservative regularization. Trajectory weighting upweights the high-return trajectories to reduce the train-test gap for BC methods, while conservative regularizer encourages the policy to stay close to the data distribution for ood conditioning. We study CWBC in the context of RvS (Emmons et al., 2021) and Decision Transformers (Chen et al., 2021), and show that CWBC significantly boosts their performance on various benchmarks.
The paper introduces ConserWeightive Behavioral Cloning (CWBC) that significantly improves policy reliability under out-of-distribution conditions.
Trajectory weighting upweights high-return trajectories and, combined with conservative regularization, bridges the train-test gap in offline RL.
CWBC achieves 18% and 8% performance improvements for RvS and Decision Transformer on D4RL benchmarks, confirming its efficacy.
Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning
Abstract and Introduction
The paper "Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning" (2210.05158) addresses crucial concerns in the context of offline RL, focusing on the reliability and performance stability of Behavioral Cloning (BC) methods when dealing with out-of-distribution (OOD) returns. Traditional BC approaches, while simpler than their value-based counterparts, suffer from significant performance degradation when conditioned on OOD returns, which poses a serious challenge in practical applications requiring extrapolation beyond the offline dataset.
The authors introduce ConserWeightive Behavioral Cloning (CWBC), a method designed to enhance the reliability of conditional BC via two components: trajectory weighting and conservative regularization. This approach seeks to reconcile the train-test gap by prioritizing high-return trajectories and ensuring the policy remains close to the data distribution during OOD conditioning. The effectiveness of CWBC is demonstrated in conjunction with existing methods like Reinforcement Learning via Supervised Learning (RvS) and Decision Transformer (DT), showcasing substantial improvements across various benchmark tasks.
Methods
Trajectory Weighting
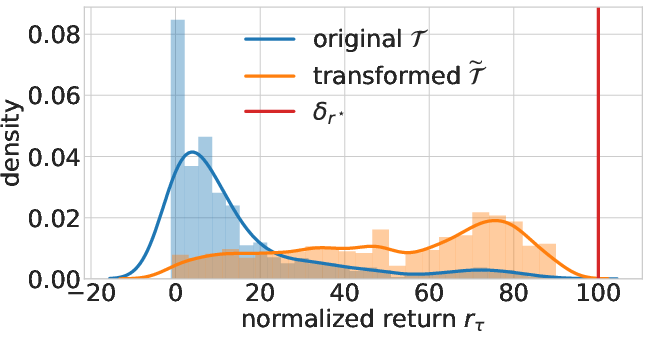
Trajectory weighting forms a core part of CWBC, aiming to transform the suboptimal trajectory distribution into one that more closely approximates the optimal distribution. This transformation is achieved by upweighting high-return trajectories, mitigating the train-test gap typically encountered in BC methods. The transformed distribution is characterized by two hyperparameters: λ, controlling proximity to the original distribution, and κ, emphasizing high-return trajectories.
Figure 1: The original return distribution T and the transformed distribution of walker2d-med-replay. We use B=20, λ=0.01, κ=r⋆−r90.
Conservative Regularization
Conservative regularization addresses model architecture sensitivity by encouraging policies to remain close to observed state-action distributions during OOD conditioning. This approach involves perturbing high-return trajectories with controlled noise to guide the policy towards conservative behavior, thereby preventing catastrophic performance drops.
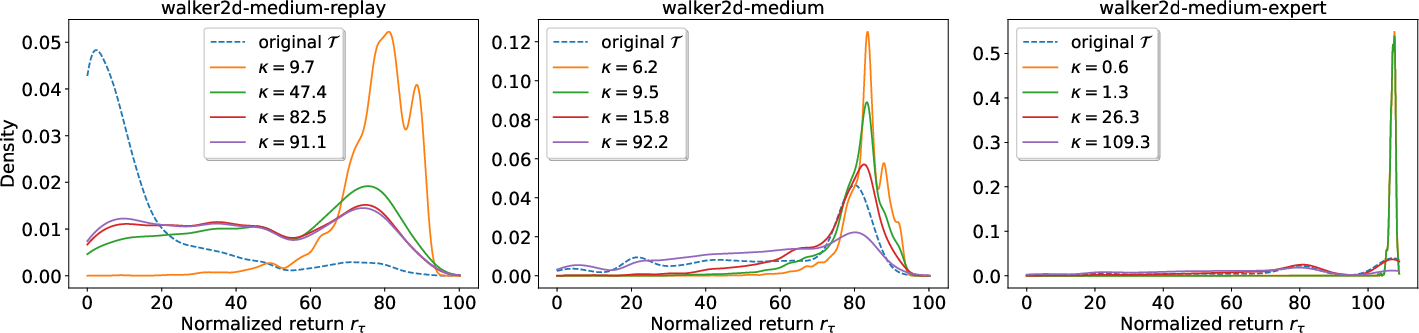
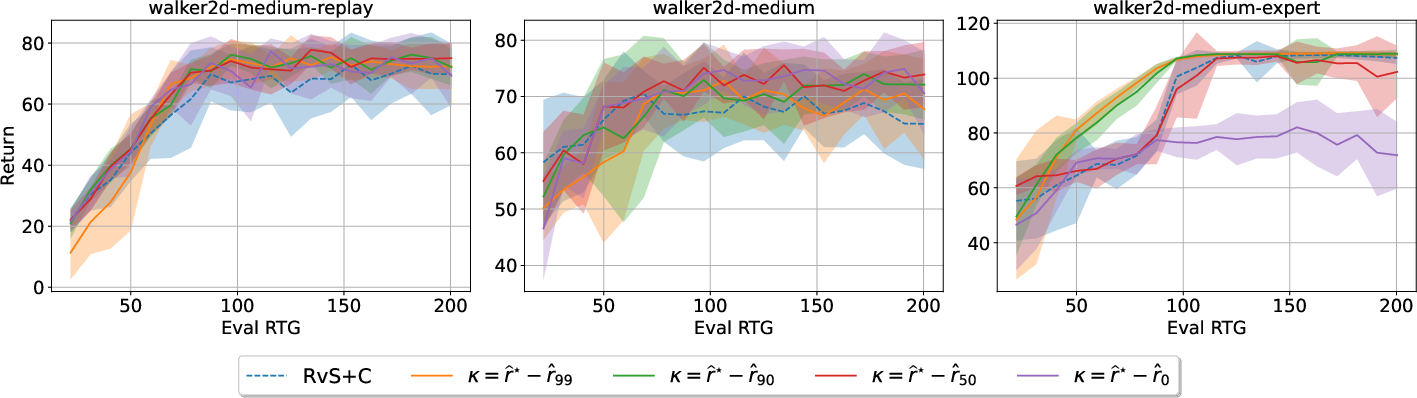
Figure 2: The influence of κ on the transformed distribution (top) and on the performance of CWBC (bottom). The legend in each panel (top) shows the absolute values of κ for easier comparison.
Experiments
D4RL Benchmark Evaluation
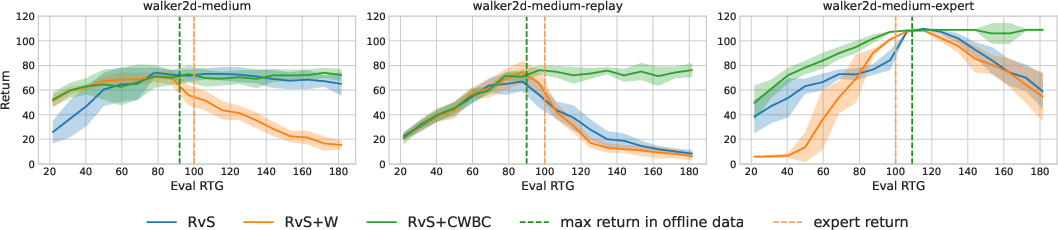
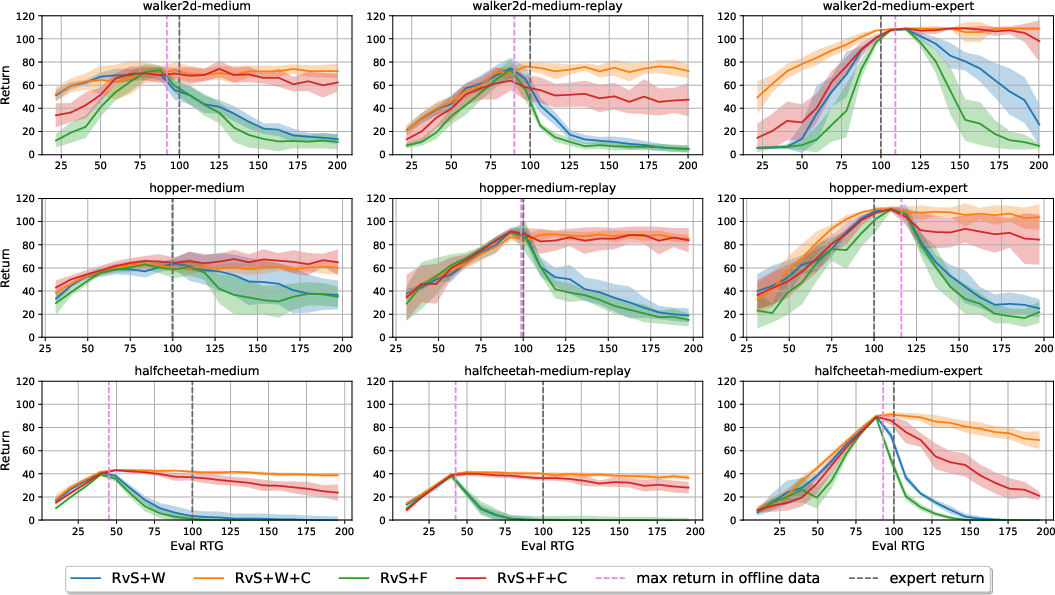
The empirical results from D4RL locomotion tasks demonstrate CWBC's substantial impact on RvS and DT performance. Comparisons show CWBC-mediated improvements averaging 18% for RvS and 8% for DT over their respective baselines. The reliability gains are particularly pronounced in low-quality datasets (med-replay), which suffer from sparse high-return trajectories.
Figure 3: The performance of RvS and its variants on walker2d datasets. RvS+W denotes RvS with trajectory weighting only, while RvS+CWBC is RvS with both trajectory weighting and conservative regularization.
Analysis of Trajectory Weighting and Conservative Regularization
Further analysis isolates the contributions of trajectory weighting and conservative regularization, highlighting their complementary roles. While trajectory weighting alone yields inconsistent improvements, combining it with conservative regularization leads to more reliable performance across varying OOD conditions. This dual-component strategy outperforms hard filtering alternatives by effectively balancing bias and variance.
Figure 4: Comparison of trajectory weighting and hard filtering.
Related Work
This study situates itself within a broader context of offline RL advancements, particularly those focusing on BC methods made competitive through strategic augmentations like contextual conditioning. The paper's innovations resonate with efforts to achieve extrapolation safety in RL by integrating task-specific conservatism, echoing similar trajectories in value-based approaches.
Conclusion
ConserWeightive Behavioral Cloning introduces a significant leap in enhancing conditional BC reliability for offline RL. Its strategic components—trajectory weighting and conservative regularization—substantially improve policy robustness and reliability under OOD conditions. Future exploration could explore cross-environment dataset amalgamation and continued refinement of extrapolation behaviors to push the boundaries of BC methods in high-stakes offline RL deployments.
Figure 5: Performance of RvS and its variants on Atari games when conditioning on different evaluation RTGs.